Clear Sky Science · it
Una nuova strategia multi-modulo di reti neurali per il riconoscimento delle emozioni umane nell’interazione uomo-robot
Insegnare ai robot a leggere le nostre emozioni
Man mano che i robot entrano nelle case, negli ospedali e nelle aule, non basta più che eseguano semplicemente istruzioni. Per essere davvero utili devono percepire come ci sentiamo e adattare il loro comportamento—confortando un paziente nervoso, calmando un guidatore agitato o incoraggiando uno studente timido. Questo articolo presenta un nuovo metodo per i robot per riconoscere le emozioni umane dalle espressioni facciali in modo rapido e accurato, anche in contesti reali disordinati dove illuminazione, sfondi affollati e occlusioni parziali spesso confondono i sistemi.

Perché i robot sensibili alle emozioni sono importanti
L’interazione uomo–robot dipende da più dei soli comandi vocali e dei movimenti precisi. Le persone segnalano naturalmente le emozioni attraverso il volto, e ci aspettiamo che le macchine socialmente intelligenti le notino e rispondano in modo appropriato. I sistemi di riconoscimento delle emozioni esistenti funzionano spesso bene solo in condizioni di laboratorio controllate: i volti sono centrati, ben illuminati e chiaramente visibili. Nella vita quotidiana, invece, i volti sono ruotati, parzialmente nascosti o catturati in scarsa illuminazione, e alcune emozioni—come paura o disgusto—appaiono molto meno frequentemente nelle immagini di addestramento. Gli autori mirano a colmare questo divario progettando un sistema di riconoscimento delle emozioni sufficientemente robusto per applicazioni reali come controlli di sicurezza, supporto sanitario, monitoraggio del guidatore e istruzione personalizzata.
Fondere più reti ispirate al cervello
Invece di fare affidamento su una singola rete neurale artificiale, i ricercatori costruiscono un sistema "multi-modulo" che combina i punti di forza di diversi modelli avanzati di analisi delle immagini. Quattro diverse reti, basate su convoluzioni e su architetture transformer, esaminano ciascuna le immagini facciali in arrivo in modo indipendente: alcune privilegiano l’efficienza per l’uso in tempo reale, altre eccellono nel catturare dettagli fini o relazioni a lungo raggio tra regioni del volto, e una mette in evidenza aree critiche come occhi e bocca. I loro output vengono fusi in una rappresentazione condivisa ricca che cattura sia texture sottili che pattern globali dell’espressione. Questa rappresentazione fusa viene poi inviata a un gruppo di classificatori, tra cui una rete convoluzionale, un’unità ricorrente in grado di tracciare i cambiamenti nel tempo nei video, e un tradizionale perceptron multistrato; il voto combinato di questi classificatori produce l’etichetta emotiva finale.
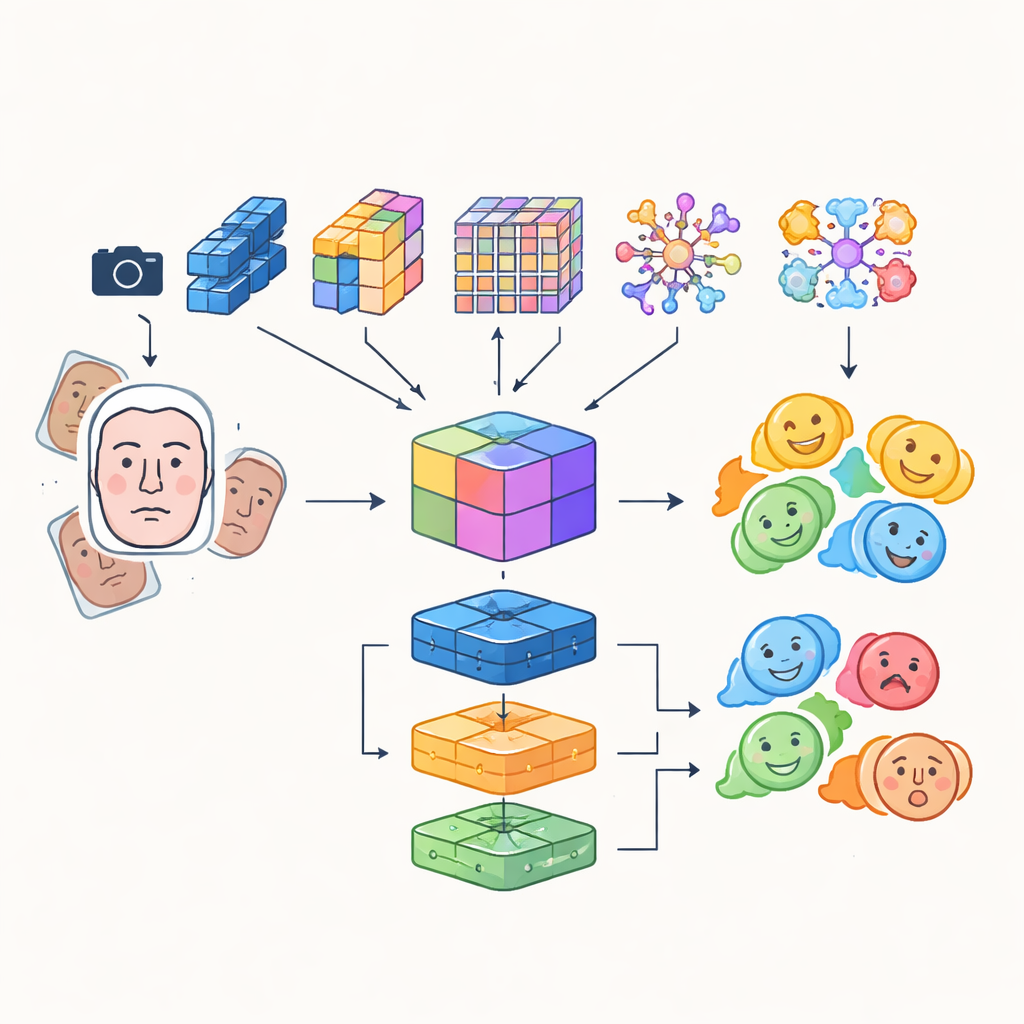
Occhi più acuti e dati di addestramento più intelligenti
Per garantire che il robot si concentri sul volto giusto al momento giusto, il sistema integra un detection transformer, un approccio moderno al rilevamento degli oggetti che tratta la ricerca del volto come un compito di predizione diretta anziché scandire l’immagine con molte scatole sovrapposte. Questo componente impara a individuare i volti in modo affidabile, anche in scene affollate, e passa regioni facciali pulite e ben inquadrate ai moduli di riconoscimento emotivo. Gli autori combinano inoltre caratteristiche apprese automaticamente con descrittori di vecchia generazione progettati a mano che prestano attenzione ai bordi e alla texture locale, creando un set ibrido di feature in grado di resistere meglio ai cambiamenti di illuminazione e alle occlusioni parziali. Per compensare il naturale sbilanciamento delle categorie emotive—molte più facce sorridenti che facce spaventate—implementano forti tecniche di data augmentation ruotando, ribaltando e alterando colore e contrasto, generando così nuovi esempi variati per le espressioni poco rappresentate.
Test su volti reali e difficili
Il team valuta il loro approccio su due database di espressioni facciali ampiamente usati—AffectNet e CK+—oltre a un nuovo dataset creato nel loro laboratorio. Questo dataset personalizzato include volutamente illuminazione dura, sfondi complessi e mutevoli e persone di contesti culturali diversi, imitando meglio le situazioni che un robot potrebbe incontrare sul campo. Su tutti e tre i dataset, il sistema multi-modulo raggiunge elevate accuratezze, superando il 90% sulle raccolte pubbliche e circa il 98% sui dati di laboratorio accuratamente curati. L’augmented data migliora consistentemente le prestazioni, in particolare per emozioni difficili come paura e disgusto, e l’ensemble combinato supera sia le pipeline classiche con feature progettate a mano sia i moderni baselines a rete singola. Importante: centrandosi su una famiglia di modelli efficiente, gli autori mantengono il processo sufficientemente veloce per risposte in tempo reale.
Costruire partner macchine più sensibili
In termini pratici, questo lavoro dimostra che i robot possono essere dotati di un sistema visivo stratificato che non solo trova i volti ma ne legge anche il contenuto emotivo con un livello di affidabilità adatto all’uso quotidiano. Impilando più reti specializzate, aggiungendo un modulo moderno di rilevamento del volto e ampliando e bilanciando con cura i dati di addestramento, il sistema può comprendere un’ampia gamma di emozioni di base anche in condizioni visive difficili. Per i non esperti, la conclusione è semplice: con questo tipo di architettura, i robot e i dispositivi interattivi del futuro sapranno meglio quando qualcuno è felice, turbato, ansioso o indifferente—e adegueranno di conseguenza le loro azioni—rendendo le nostre interazioni con le macchine più naturali, di supporto e umane.
Citazione: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Parole chiave: interazione uomo-robot, riconoscimento delle emozioni, espressioni facciali, deep learning, vision basata su transformer