Clear Sky Science · nl
Een nieuwe multi-module neurale-netwerkstrategie voor het herkennen van menselijke emoties in de mens-robotinteractie
Robots leren onze gevoelens lezen
Nu robots hun intrede doen in woningen, ziekenhuizen en klaslokalen is het niet meer voldoende dat ze alleen instructies opvolgen. Om echt behulpzaam te zijn, moeten ze aanvoelen hoe we ons voelen en hun gedrag daarop aanpassen—bijvoorbeeld een nerveuze patiënt troosten, een overstuurde bestuurder kalmeren of een verlegen leerling aanmoedigen. Dit artikel presenteert een nieuwe manier voor robots om menselijke emoties snel en nauwkeurig uit gezichtsuitdrukkingen te lezen, zelfs in rommelige, realistische situaties waar licht, achtergrondafleiding en gedeeltelijke obstructies vaak systemen in de war brengen.

Waarom emotioneel bewuste robots ertoe doen
Mens–robotinteractie berust op meer dan spraakcommando’s en exacte bewegingen. Mensen geven emoties van nature aan via hun gezichten, en we verwachten dat sociaal intelligente machines dat opmerken en gepast reageren. Bestaande emotierecognitiesystemen werken vaak goed alleen in gecontroleerde laboratoriumomgevingen: gezichten zijn gecentreerd, goed verlicht en duidelijk zichtbaar. In het dagelijks leven daarentegen zijn gezichten gedraaid, gedeeltelijk verborgen of vastgelegd bij slechte belichting, en sommige emoties—zoals angst of walging—verschijnen veel minder vaak in trainingsbeelden. De auteurs willen deze kloof overbruggen door een emotierecognitiesysteem te ontwerpen dat robuust genoeg is voor inzet in de echte wereld, bijvoorbeeld bij veiligheidscontroles, gezondheidszorg, bestuurdersmonitoring en gepersonaliseerd onderwijs.
Het combineren van meerdere hersen-geïnspireerde netwerken
In plaats van te vertrouwen op één enkel kunstmatig neuraal netwerk bouwen de onderzoekers een "multi-module" systeem dat de sterke punten van verschillende geavanceerde beeldanalysemethoden combineert. Vier verschillende convolutionele en transformer-gebaseerde netwerken onderzoeken elk binnen hun eigen aanpak binnenkomende gezichtsbeelden: sommige richten zich op efficiëntie voor realtime gebruik, andere blinken uit in het vastleggen van fijne details of langeafstandrelaties tussen gezichtsregio’s, en één benadrukt cruciale zones zoals ogen en mond. Hun outputs worden samengevoegd tot een rijke gedeelde representatie die zowel subtiele texturen als globale expressiepatronen vastlegt. Deze gefuseerde representatie wordt vervolgens gevoed aan een groep classifiers, waaronder een convolutioneel netwerk, een recurrente eenheid die veranderingen in de tijd in video kan volgen, en een traditionele multi-layer perceptron, waarvan de gecombineerde stem het uiteindelijke emotielabel bepaalt.
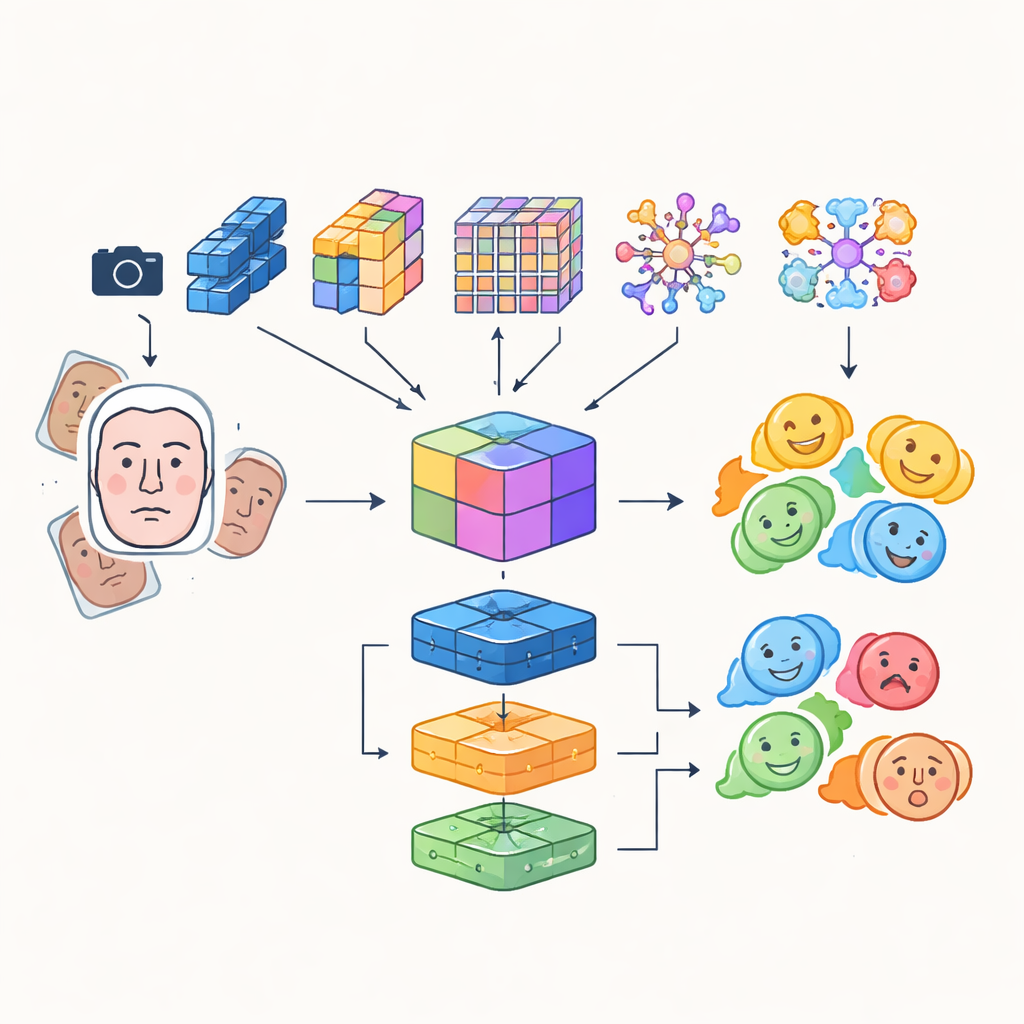
Scherpere blik en slimmer trainingsmateriaal
Om ervoor te zorgen dat de robot op het juiste moment op het juiste gezicht focust, integreert het systeem een detection transformer, een moderne objectdetectiebenadering die het vinden van een gezicht behandelt als een directe voorspeltaak in plaats van het scannen van de afbeelding met veel overlappende kaders. Deze component leert gezichten betrouwbaar te lokaliseren, zelfs in drukke scènes, en levert schone, goed ingekaderde gezichtsregio’s aan de emotiemodules. De auteurs combineren ook automatisch geleerde kenmerken met oudere, handgemaakte descriptors die letten op randen en lokale textuur, waardoor een hybride kenmerkenset ontstaat die beter bestand is tegen veranderingen in verlichting en gedeeltelijke occlusie. Om te compenseren voor de natuurlijke onbalans tussen emotiecategorieën—veel meer glimlachende gezichten dan angstige—augmenteren ze de trainingsdata sterk door te roteren, spiegelen en kleur en contrast aan te passen, waardoor effectief nieuwe, gevarieerde voorbeelden van ondervertegenwoordigde expressies worden gegenereerd.
Testen op echte en uitdagende gezichten
Het team evalueert hun aanpak op twee veelgebruikte databases voor gezichtsuitdrukkingen—AffectNet en CK+—en op een nieuwe, in hun lab gemaakte dataset. Deze eigen dataset bevat opzettelijk harde belichting, complexe en wisselende achtergronden en mensen uit diverse culturele omgevingen, waardoor situaties beter worden gesimuleerd die een robot in het wild kan tegenkomen. Over alle drie de datasets behaalt het multi-module systeem hoge nauwkeurigheid, meer dan 90% op de publieke verzamelingen en ongeveer 98% op de zorgvuldig samengestelde labdata. Data-augmentatie verbetert consequent de prestaties, vooral voor lastige emoties zoals angst en walging, en het gecombineerde ensemble presteert beter dan zowel klassieke handgemaakte pipelines als moderne single-network baselines. Belangrijk is dat de ontwerpkeuze voor een efficiënte modelfamilie de verwerking snel genoeg houdt voor realtime reacties.
Het bouwen van sensitievere machinale partners
In praktische termen laat dit werk zien dat robots kunnen worden uitgerust met een gelaagd visionsysteem dat niet alleen gezichten detecteert, maar ook de emotionele inhoud ervan leest met een betrouwbaarheid die geschikt is voor dagelijks gebruik. Door meerdere gespecialiseerde netwerken te stapelen, een moderne gezichtsdetectiemodule toe te voegen en het trainingsmateriaal zorgvuldig uit te breiden en te balanceren, kan het systeem een breed scala aan basale emoties begrijpen, zelfs onder moeilijke visuele omstandigheden. Voor niet-experts is de kernboodschap helder: met dit soort architectuur zullen toekomstige robots en interactieve apparaten beter in staat zijn te signaleren wanneer iemand blij, van streek, angstig of onverschillig is—and hun gedrag daar vervolgens op aan te passen—waardoor onze interacties met machines natuurlijker, ondersteunender en menselijker aanvoelen.
Bronvermelding: Zaman, K., Islam, A.U., Zengkang, G. et al. A novel multi-module neural networks strategy of human emotion recognition in the human-robot interaction. Sci Rep 16, 11433 (2026). https://doi.org/10.1038/s41598-026-40798-8
Trefwoorden: mens-robotinteractie, emotierecognitie, gezichtsuitdrukkingen, deep learning, vision gebaseerd op transformer