Clear Sky Science · zh
通过物理约束神经算子实现可解释的声道与呼吸反演
倾听声音内部
当我们听到优美的歌声时,很少会想到造就它的那些运动部件:从喉到唇的扭曲气道、推动气流的肺部,以及塑造每个音符的微小肌肉。然而,声乐教师与医生却非常在意这些隐藏的运动。本研究提出了一种仅通过录制的声音“看到”声道和肺部内部的方法,搭建了外部听到的声音与体内动作之间的桥梁——速度足够快,能用于实时反馈和未来的智能声乐训练工具。
喉部形状为何重要
声音的色彩和特性——即音色——来自声道形状与肺部气流之间的微妙互动。舌位、软腭或下颌的细微移动,以及呼气压力的轻微变化,都能让同一个音听起来明亮、暗哑、紧绷或放松。现有的计算模型可以模仿声音,但通常像黑箱一样:它们不揭示体内物理发生的情况,而且在应用于具有不同解剖结构的新说话者时常常失效。本项工作弥补了这一差距,关注的不仅是复制声音,而是恢复产生该声音的底层几何结构与呼吸模式。
从多种信号构建丰富图景
为了使模型扎根于真实生理,研究人员首先从1000名成年志愿者(包括受过训练的歌手和非专业者)创建了大型数据集。在精心设计的发声任务中——如持续元音与滑动音高——他们同时记录了多种信号:声带附近组织的高速超声影像、显示受试者如何支撑声音的腹压、胸腹的三维运动,以及高保真音频。所有这些数据流都对齐到共同的时间网格,精度仅半毫秒。复杂的检查确保因果关系在物理上成立——例如,呼吸压力脉冲必须以现实的延迟领先响度变化,组织刚度估计必须保持在生理可接受的范围内。结果是一段同步且物理一致的“电影”,展示了身体与声音如何共同演变。
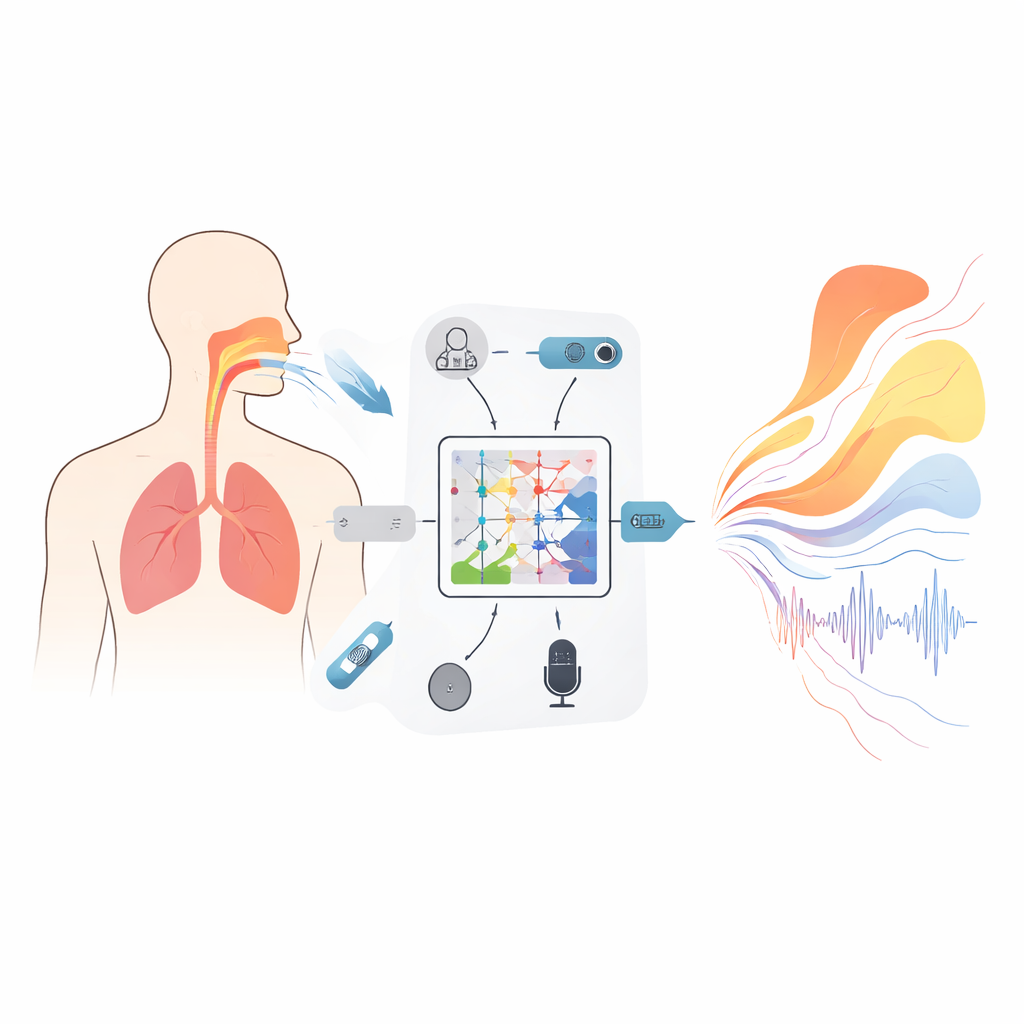
一种尊重物理规律的新型模型
该框架的核心是一个数学工具——Kolmogorov–Arnold神经(KAN)算子,这里被改造用来学习整体函数如何映射到其它函数——例如,一段随频率变化的音频谱如何映射为沿声道长度的横截面积曲线。网络中的每个单元不是使用固定的激活函数,而是采用可变形的样条曲线,以捕捉声音与形状关系的细微差别。一个三层嵌套结构逐步细化该映射,以估计从声门到唇部19个位置的面积,同时在训练目标中加入额外项,以抑制不可能的跳跃或关闭(这些情况会阻止发声)。一个配套的递归模块跟踪横膈膜两侧压差随时间的演化,内置约束源自基础力学,使得推断出的呼吸模式变化不会快于真实肌肉所能达到的速度。
聚焦呼吸与音色细节
除重建解剖与气流外,该系统还放大了声音本身的细微结构。一个“超分辨率”预测头以恢复的生理参数为输入,生成极为细致的谱图,更新频率可达每十分之一毫秒一次。通过引入分数阶微积分工具并惩罚违反声道内声波方程的情况,该模块能恢复微小的音高与响度波动(即抖动与颤动),而不会在录制频带外虚构不符合物理的能量。在对音色和声音识别尤为重要的1.2–2.4 kHz频段上,该方法相比数个领先的神经算子基线将谱误差削减了一半以上。它在类似Raspberry Pi的设备上也能快速、轻量地运行,使处理延迟保持在大约20毫秒以内。
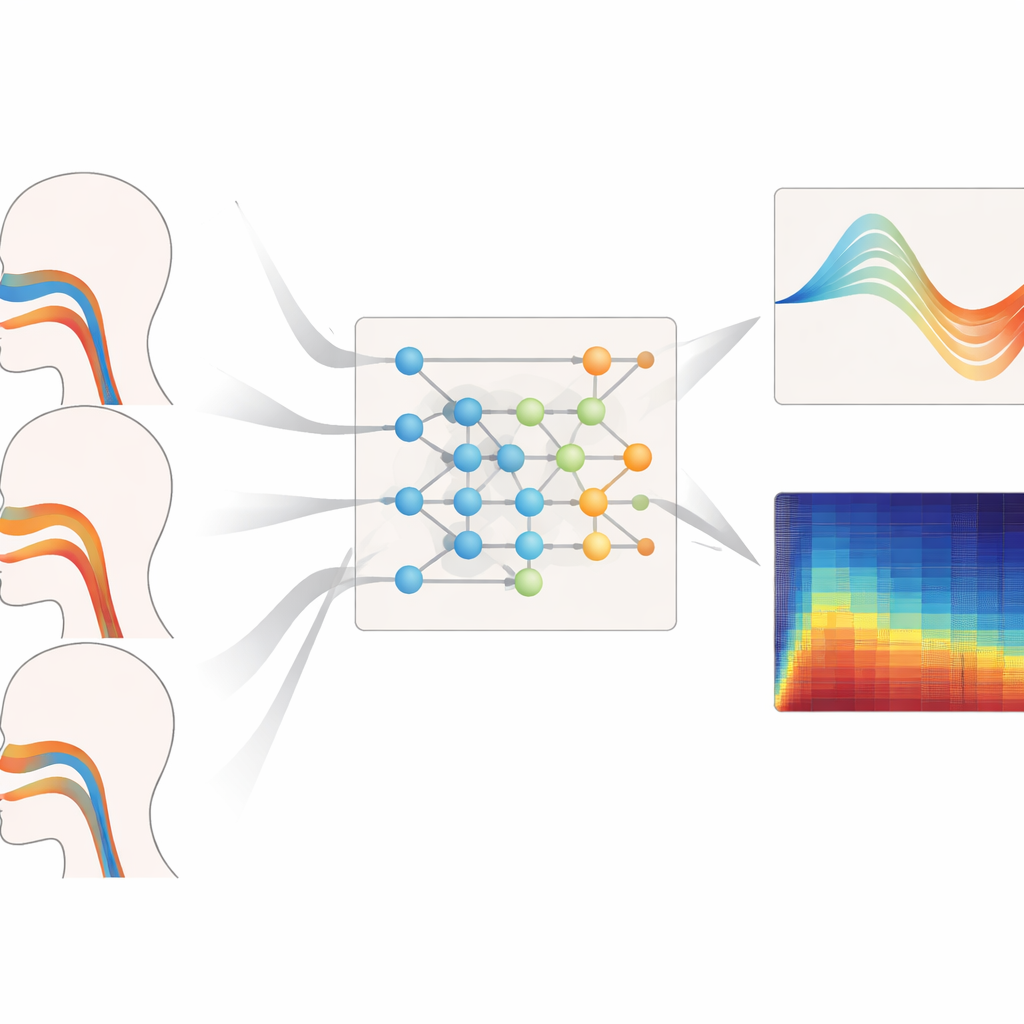
跨声音类型的表现如何
作者在不同音高范围、演唱风格和未见的声源类型上对其框架进行了严格测试。当要求重建低音、中音和高音的声道几何时,该模型在面积误差与与真实形状匹配度方面始终表现最优,尤其在高音区——声道需要更剧烈变形的地方。它在连歌、断句与响度变化的乐句中也给出了最可靠的呼吸压力估计,具有短延迟和平滑且符合肌肉动力学的时间过程。即便在对完全未用于训练的女高音和低音进行评估时,系统仍保持较低的几何与压力误差,表明它学到的是声乐控制的一般原理,而非记忆个别说话者。
对歌手与教师的意义
通俗地说,这项工作表明可以直接从人发出的声音推断其如何塑造喉部与管理呼吸,且这种推断既准确又基于基本物理。该模型将难以捉摸的音色,转化为可解释的曲线:声道各部分的宽度、腹压如何起伏,以及细微的音高和响度波动如何随时间展开。尽管该研究尚未在实际课程中测试学习效果,但它为未来能够提供实时、基于解剖的个性化反馈的工具奠定了技术基础,也为需要非侵入性了解病人发声机制的临床工作提供了可能。
引用: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
关键词: 声道建模, 呼吸动力学, 声音音色分析, 物理约束神经网络, 个性化声乐训练