Clear Sky Science · pl
Interpretowalna inwersja dróg głosowych i oddechowych za pomocą fizycznie uświadomionych operatorów neuronowych
Słuchając wnętrza głosu
Kiedy słyszymy piękny głos śpiewający, rzadko myślimy o ruchomych częściach, które go tworzą: skręconej drodze od tchawicy do ust, płucach tłoczących powietrze i drobnych mięśniach kształtujących każdą nutę. Nauczyciele śpiewu i lekarze jednak mocno interesują się tymi ukrytymi ruchami. W tym badaniu przedstawiono sposób „zajrzenia do wnętrza” dróg głosowych i płuc wykorzystując jedynie nagrany dźwięk, budując pomost między tym, co słyszymy na zewnątrz, a tym, co ciało robi wewnątrz — na tyle szybko, by nadawać się do informacji zwrotnej w czasie rzeczywistym i przyszłych inteligentnych narzędzi treningu głosu.
Dlaczego kształt gardła ma znaczenie
Kolor i charakter głosu — jego barwa — powstają z subtelnej relacji między kształtem dróg głosowych a przepływem powietrza z płuc. Małe przesunięcia języka, podniebienia lub żuchwy oraz subtelne zmiany ciśnienia oddechowego mogą sprawić, że ta sama nuta zabrzmi jasno, ciemno, napięcie lub rozluźniona. Istniejące modele komputerowe potrafią naśladować głosy, ale zwykle zachowują się jak czarne skrzynki: nie ujawniają, co fizycznie dzieje się wewnątrz ciała i często zawodzą przy nowych mówcach o innej anatomii. Ta praca wypełnia tę lukę, koncentrując się nie tylko na odtwarzaniu dźwięku, ale na odtworzeniu leżącej u jego podstaw geometrii i wzorców oddychania, które go tworzą.
Budowanie bogatego obrazu z wielu sygnałów
Aby osadzić model w rzeczywistej fizjologii, badacze najpierw stworzyli dużą bazę danych od 1000 dorosłych ochotników, wśród których byli zarówno wytrenowani śpiewacy, jak i osoby nieprofesjonalne. Podczas starannie zaprojektowanych zadań wokalnych — długich samogłosek i przesuwanych wysokości dźwięków — rejestrowali jednocześnie kilka sygnałów: obrazy ultradźwiękowe tkanek przy strunach głosowych w wysokiej prędkości, ciśnienie brzucha pokazujące, jak silne było podparcie dźwięku, trójwymiarowy ruch klatki piersiowej i brzucha oraz wysokiej jakości nagranie audio. Wszystkie strumienie zostały wyrównane do wspólnej siatki czasowej z dokładnością do pół milisekundy. Zaawansowane kontrole zapewniały, że przyczyna i skutek miały fizyczny sens — na przykład impulsy ciśnienia oddechowego musiały poprzedzać zmiany głośności z realistycznym opóźnieniem, a estymaty sztywności tkanek musiały pozostać fizjologicznie wiarygodne. Efektem jest zsynchronizowane, fizycznie spójne „wideo” pokazujące, jak ciało i dźwięk zmieniają się razem.
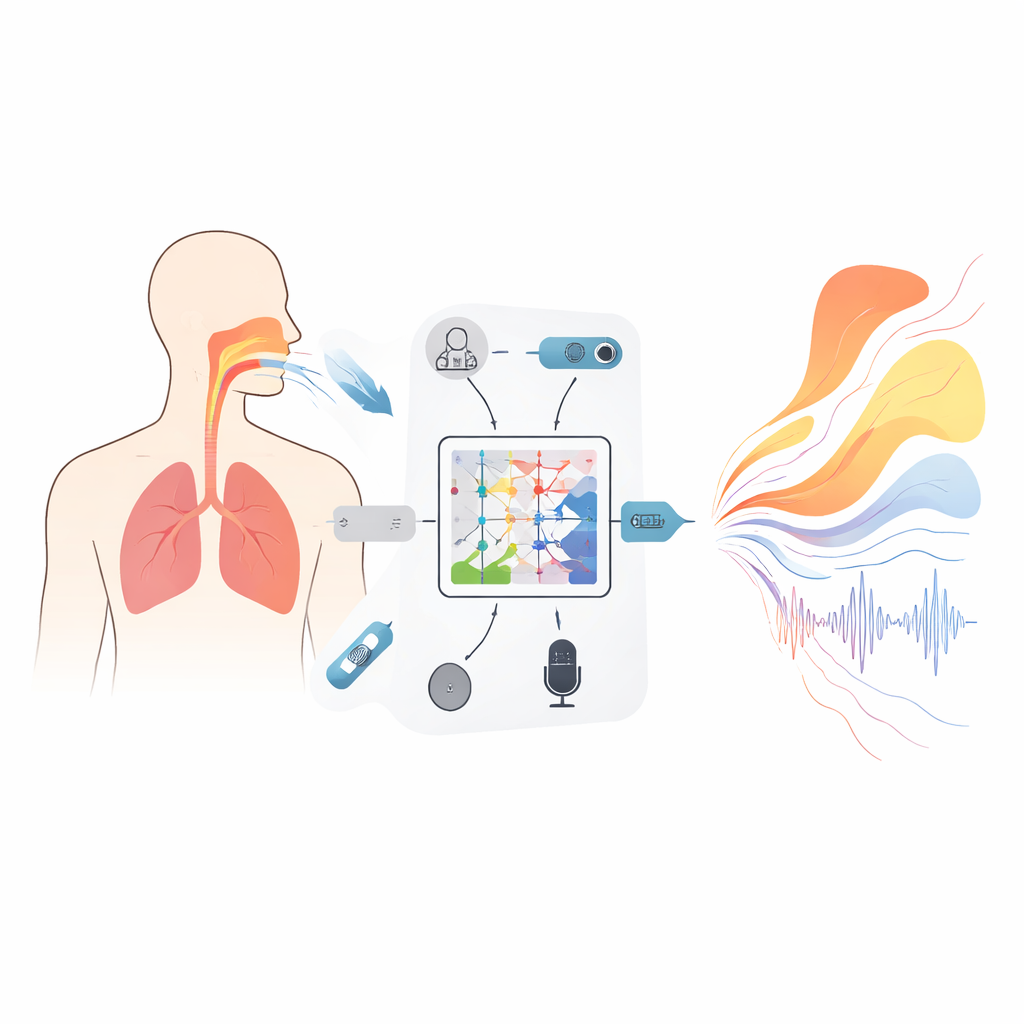
Nowy rodzaj modelu respektujący prawa fizyki
W rdzeniu ramy znajduje się narzędzie matematyczne zwane operatorem neuronowym Kolmogorowa–Arnolda (KAN), zaadaptowane tutaj do uczenia się odwzorowań funkcja–do–funkcji — na przykład, jak spektrum audio w funkcji częstotliwości mapuje się na krzywą opisującą pole przekroju poprzecznego dróg głosowych wzdłuż ich długości. Zamiast stałych funkcji aktywacji, każda jednostka w tej sieci używa elastycznych krzywych sklejanych (spline), które mogą się wyginać, by uchwycić drobne szczegóły związku między dźwiękiem a kształtem. Trójwarstwowa, zagnieżdżona struktura stopniowo udoskonala to odwzorowanie, aby oszacować przekroje w 19 punktach od głośni po usta, podczas gdy dodatkowe składniki w funkcji celu treningu zniechęcają do niemożliwych skoków czy zamknięć uniemożliwiających fonację. Towarzyszący moduł rekurencyjny śledzi, jak różnice ciśnień po obu stronach przepony zmieniają się w czasie, z wbudowanymi ograniczeniami wynikającymi z podstawowej mechaniki, tak by wnioskowane wzorce oddychania nie zmieniały się szybciej, niż pozwalają na to realne mięśnie.
Zbliżenie na szczegóły oddechu i barwy
Poza rekonstrukcją anatomii i przepływu powietrza system przygląda się też drobnym cechom samego dźwięku. Głowica predykcyjna „superrozdzielczości” przyjmuje odzyskaną fizjologię jako wejście i generuje niezwykle szczegółowe spektrum, aktualizowane nawet co dziesiątą milisekundy. Poprzez włączenie narzędzi rachunku ułamkowego rzędu i karanie naruszeń równania falowego opisującego dźwięk w drogach głosowych, głowica ta odtwarza drobne fluktuacje wysokości i głośności — znane jako jitter i shimmer — bez wprowadzania niefizycznej energii poza zarejestrowanym pasmem częstotliwości. W zakresie 1,2–2,4 kHz, który jest szczególnie ważny dla barwy i tożsamości głosu, metoda zredukowała błędy spektralne o ponad połowę w porównaniu z kilkoma wiodącymi bazowymi operatorami neuronowymi. Działała też wystarczająco szybko i lekko na urządzeniu klasy Raspberry Pi, by utrzymać opóźnienia przetwarzania poniżej około 20 milisekund.
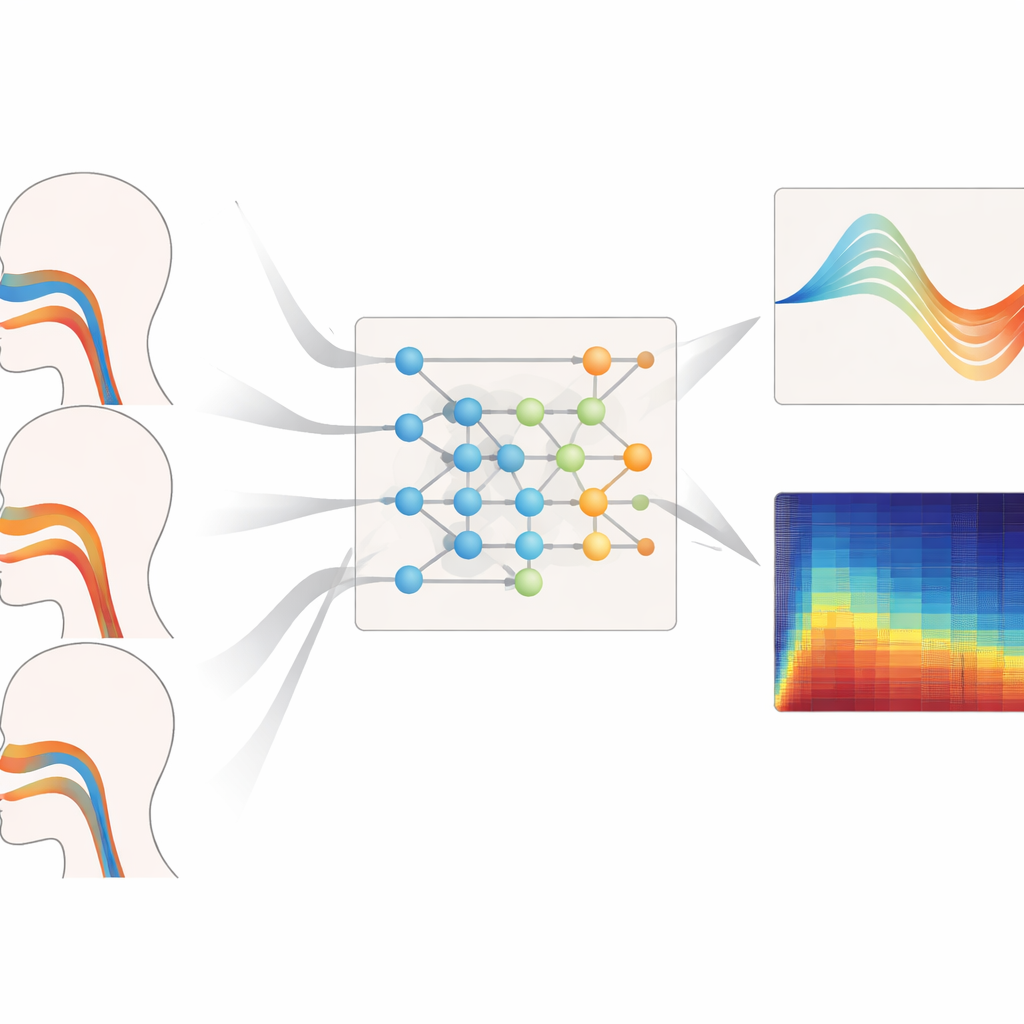
Jak dobrze działa w różnych głosach
Autorzy poddali swoje rozwiązanie próbom w różnych zakresach wysokości, stylach śpiewu i nieznanych wcześniej typach głosów. Przy zadaniu rekonstrukcji geometrii dróg głosowych dla basów, głosów środkowych i wysoko brzmiących model konsekwentnie osiągał najmniejsze błędy pól przekrojów i najsilniejsze dopasowanie do rzeczywistych kształtów, zwłaszcza przy wysokich dźwiękach, gdzie drogi głosowe muszą deformować się bardziej dramatycznie. Oferował również najbardziej wiarygodne estymaty ciśnienia oddechowego podczas legato, staccato i fraz ze zmienną głośnością, z krótkimi opóźnieniami i płynnymi przebiegami czasowymi realistycznymi dla mięśni. Nawet gdy oceniano go na sopranistkach i basistach, których dane były całkowicie wyłączone z treningu, system utrzymywał niskie błędy geometrii i ciśnienia, co sugeruje, że nauczył się ogólnych zasad kontroli głosu, a nie zapamiętywał poszczególnych wykonawców.
Co to znaczy dla śpiewaków i nauczycieli
W codziennym rozumieniu ta praca pokazuje, że możliwe jest wnioskowanie, jak osoba kształtuje gardło i kontroluje oddech bezpośrednio z dźwięku, który wydaje, w sposób zarówno dokładny, jak i osadzony w podstawowych prawach fizyki. Model przekształca ulotną cechę barwy w interpretowalne krzywe: jak szeroka jest każda część dróg głosowych, jak ciśnienie w jamie brzusznej rośnie i opada oraz jak subtelne ripple w wysokości i głośności rozwijają się w czasie. Choć badanie jeszcze nie testuje efektów uczenia się w rzeczywistych lekcjach, kładzie techniczne podstawy pod przyszłe narzędzia, które mogłyby dostarczać śpiewakom informacji zwrotnej w czasie rzeczywistym, uwzględniającej anatomię i dopasowane do ich ciał, oraz dla klinicystów potrzebujących nieinwazyjnego wglądu w to, jak powstają głosy pacjentów.
Cytowanie: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Słowa kluczowe: modelowanie dróg głosowych, dynamika oddechowa, analiza barwy głosu, sieci neuronowe z uwzględnieniem praw fizyki, spersonalizowany trening głosu