Clear Sky Science · ar
استدلال قابل للتفسير لمسارات الحنجرة والتنفس عبر مؤثرات عصبية مستنيرة بالفيزياء
الاستماع إلى داخل الصوت
عندما نسمع صوت غنائي جميل، نادراً ما نفكر في الأجزاء المتحركة التي تصنعه: الممر الهوائي المتعرج من الحلق إلى الشفاه، والرئتان الدافعتان للهواء، والعضلات الدقيقة التي تشكّل كل نغمة. معلمو الغناء والأطباء، مع ذلك، يهتمون بشدة بهذه الحركات الخفية. تُقدّم هذه الدراسة طريقة «للنظر إلى الداخل» في مجرى الصوت والرئتين باستخدام الصوت المسجّل فقط، لتبني جسراً بين ما نسمعه من الخارج وما يفعله الجسم في الداخل — بسرعة كافية لتكون مفيدة للتغذية الراجعة في الزمن الحقيقي وأدوات تدريب صوتية ذكية مستقبلية.
لماذا شكل الحلق مهم
لون وطابع الصوت — طابعه — ينبعان من تفاعل دقيق بين شكل مجرى الصوت وطريقة تدفق الهواء من الرئتين. تغييرات صغيرة في موضع اللسان أو الحنك الرخو أو الفك، وتغيرات طفيفة في ضغط النفس، يمكن أن تجعل نفس النغمة تبدو مشرقة أو داكنة أو متوترة أو مسترخية. النماذج الحاسوبية الحالية يمكن أن تُحاكي الأصوات، لكنها غالباً ما تعمل كصناديق سوداء: لا تكشف عما يحدث فعلياً داخل الجسم، وغالباً ما تفشل عند تطبيقها على متكلمين جدد ذوي تشريح مختلف. تتعامل هذه الدراسة مع هذه الفجوة من خلال التركيز ليس فقط على نسخ الصوت، بل على استعادة الهندسة وأنماط التنفس الكامنة التي تُنتج هذا الصوت.
بناء صورة غنيّة من إشارات متعددة
لربط النموذج بالفسيولوجيا الحقيقية، أنشأ الباحثون أولاً مجموعة بيانات كبيرة من 1000 متطوع بالغ، شملت مطربين مدرّبين وغير محترفين. أثناء مهام صوتية مصممة بعناية — حروف صوتية مطوّلة وتدرجات لحنية — سجّلوا عدة إشارات في آنٍ واحد: صور بالموجات فوق الصوتية عالية السرعة للأنسجة قرب الحبال الصوتية، وضغط بطني يوضح مدى دعم الشخص للصوت، وحركة ثلاثية الأبعاد للصدر والبطن، وصوت عالي الدقة. تم محاذاة كل هذه التدفقات على شبكة زمنية مشتركة بفواصل زمنية نصف ملّي ثانية فقط. ضمنت فحوصات متقدمة أن السبب والنتيجة يتسقان فيزيائياً — مثلاً، نبضات ضغط النفس يجب أن تسبق تغيّر الشدة بتأخير واقعي، ويجب أن تظل تقديرات صلابة الأنسجة ضمن نطاقات فسيولوجية معقولة. النتيجة فيلم متزامن ومتسق فيزيائياً يظهر كيف يتطوّر الجسم والصوت معاً.
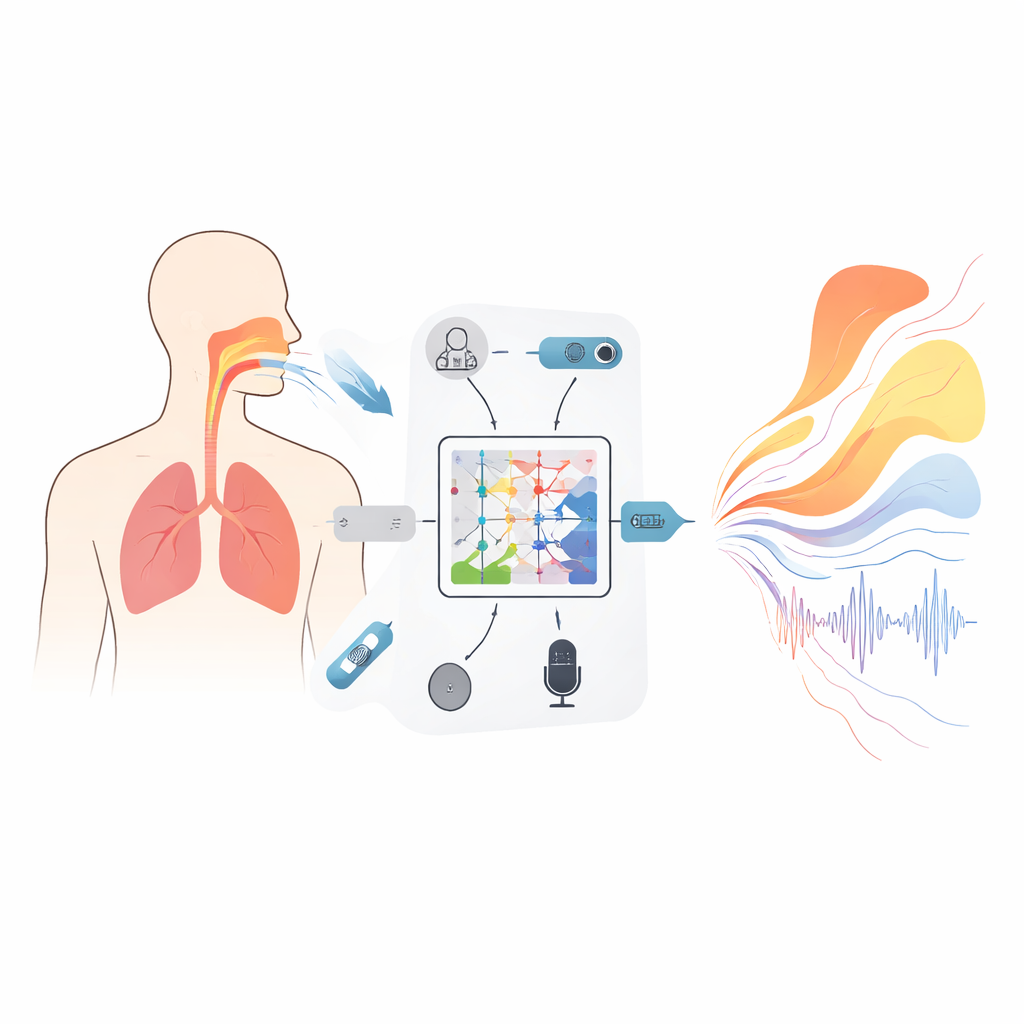
نوع جديد من النماذج يحترم الفيزياء
في جوهر الإطار توجد أداة رياضية تُسمى مؤثر كولموغوروف–أرنولد العصبي (KAN)، مُعدّلة هنا لتعلّم كيفية تحويل دوال كاملة إلى دوال أخرى — على سبيل المثال، كيف يخضع طيف صوتي عبر التردد لتحويل إلى منحنى يصف مساحة المقطع العرضي لمجرى الصوت على طوله. بدلاً من دوال تفعيل ثابتة، يستخدم كل عنصر في هذه الشبكة منحنيات سبلاين مرنة يمكن أن تنحني لالتقاط تفاصيل دقيقة للعلاقة بين الصوت والشكل. بنية ثلاثية الطبقات ومتداخلة تُحسّن تدريجياً هذا التحويل لتقدير مساحات 19 موضعاً من الغلوتيس إلى الشفاه، بينما تُثبط مصطلحات إضافية في هدف التدريب القفزات أو الانسدادات المستحيلة التي تمنع النطق. وحدة متكررة مرافقَة تتتبّع كيف تتطوّر فروق الضغط عبر الحجاب الحاجز زمنياً، مع قيود مدمجة مشتقة من ميكانيكا أساسية بحيث لا تتغير أنماط التنفس المستنتجة أسرع مما تستطيع العضلات الحقيقية أن تفعله.
تكبير تفاصيل النفس والطابع
بعيداً عن إعادة بناء التشريح وتدفق الهواء، يركّز النظام أيضاً على الحبيبات الدقيقة للصوت نفسه. رأس تنبؤ «فائق الدقة» يأخذ الفسيولوجيا المستعادة كمدخل ويولّد طيفاً مفصلاً للغاية، محدثاً بتواتر يصل إلى كل عُشر ملّي ثانية. من خلال دمج أدوات من حساب التفاضل والتكامل من رُتبة كسرية وعن طريق معاقبة انتهاكات معادلة الموجة التي تحكم الصوت في مجرى الصوت، يستعيد هذا الجزئي تقلبات صغيرة في النغمة والشدة — المعروفة بالارتعاش واللمعان (jitter و shimmer) — دون اختراع طاقة غير فيزيائية خارج نطاق التردد المسجل. عبر النطاق 1.2–2.4 كيلوهرتز، المهم بشكل خاص للطابع وهوية الصوت، قلّصت الطريقة الأخطاء الطيفية بأكثر من النصف مقارنة بعدة مؤثرات عصبية رائدة. كما عملت بسرعة وخفة كافية على جهاز من فئة Raspberry Pi ليبقي تأخيرات المعالجة تحت نحو 20 ملّي ثانية.
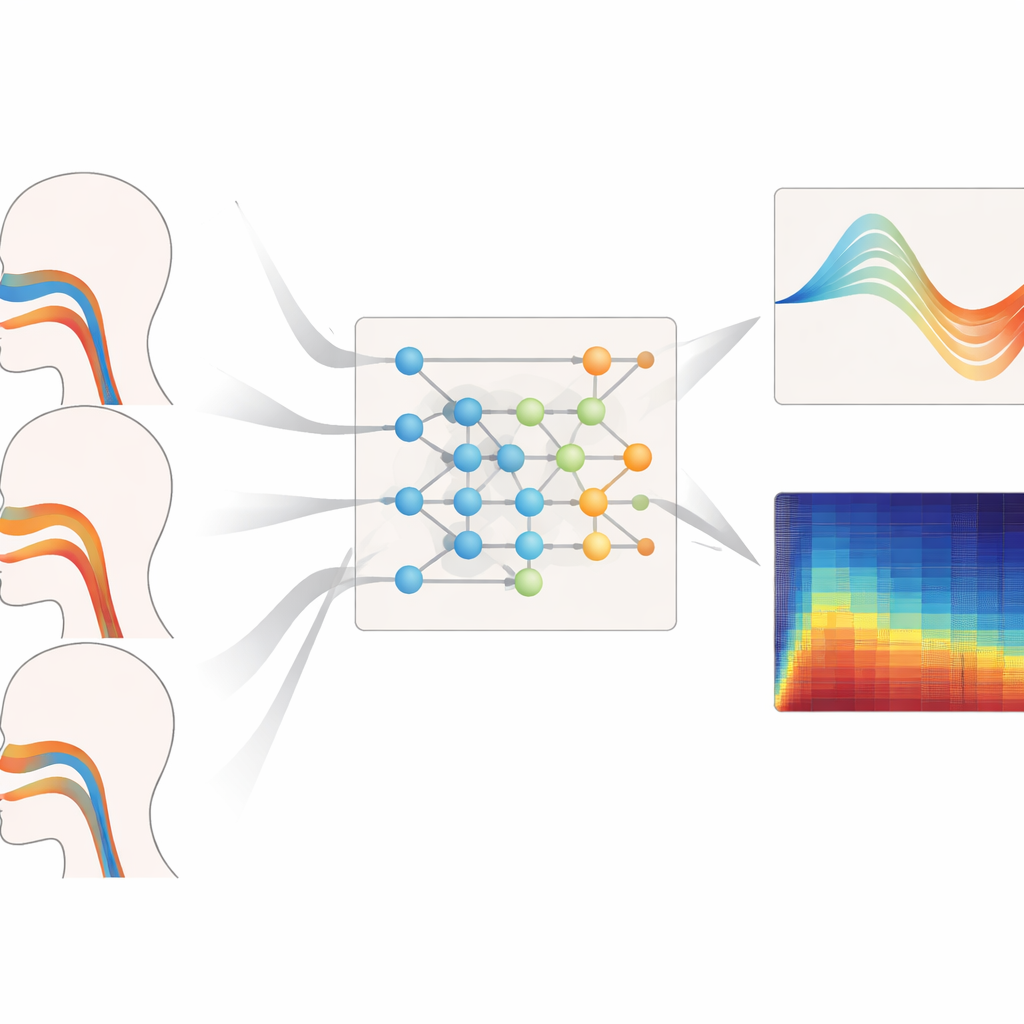
مدى فاعليته عبر الأصوات المختلفة
اختبر المؤلفون إطارهم بقسوة عبر نطاقات نغمية مختلفة، وأساليب غناء، وأنواع أصوات غير مرئية أثناء التدريب. عند تكليفهم بإعادة بناء هندسة مجرى الصوت لأصوات الباص والمتوسط والعالي النغمة، أنتج نموذجهم باستمرار أقل أخطاء في المساحة وأقوى تطابق مع الأشكال الحقيقية، خاصة عند النغمات العالية حيث يجب أن يتشوه مجرى الصوت بدرجة أكبر. كما قدم أدق التقديرات لضغط النفس أثناء العبارات المستمرة (legato) والمتقطعة (staccato) والعبارات ذات تغيّر الشدة، مع تأخيرات قصيرة ومسارات زمنية ناعمة وواقعية عضلياً. حتى عند تقييمه على سورانو وباسات لم تُستخدم بياناتهم أثناء التدريب، حافظ النظام على أخطاء هندسية وضغط منخفضة، مما يوحي بأنه تعلم مبادئ عامة للتحكم الصوتي بدل حفظ بيانات المتكلمين الفردية.
ما يعنيه هذا للمطربين والمعلمين
بمصطلحات يومية، تُظهر هذه الدراسة أنه من الممكن الاستدلال على كيفية تشكيل الشخص لحلقه وإدارة أنفاسه مباشرة من الصوت الذي يصدره، بطريقة دقيقة ومرتكزة على فيزياء أساسية. يحوّل النموذج خاصية الطابع السحرية إلى منحنيات قابلة للتفسير: مدى اتساع كل جزء من مجرى الصوت، كيف يرتفع وينخفض ضغط البطن، وكيف تتكشف تموجات طفيفة في النغمة والشدة عبر الزمن. بينما لا تختبر الدراسة بعد نتائج التعلم في دروس فعلية، فإنها تضع الأساس التقني لأدوات مستقبلية قد تقدّم للمطربين تغذية راجعة فورية وواعية للتشريح ومفصّلة حسب أجسامهم، وللممارسين السريريين الذين يحتاجون إلى رؤى غير جراحية حول كيفية إنتاج أصوات المرضى.
الاستشهاد: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
الكلمات المفتاحية: نمذجة مجرى الصوت, ديناميكيات الجهاز التنفسي, تحليل طابع الصوت, الشبكات العصبية المستنيرة بالفيزياء, تدريب صوتي مخصص