Clear Sky Science · pt
Inversão interpretável do trato vocal e respiratória via operadores neurais informados pela física
Ouvindo por Dentro da Voz
Quando ouvimos uma voz cantada bonita, raramente pensamos nas partes móveis que a criam: a via aérea sinuosa da garganta aos lábios, os pulmões empurrando o ar e os músculos minúsculos que moldam cada nota. Professores de canto e médicos, porém, se importam profundamente com esses movimentos ocultos. Este estudo apresenta uma maneira de “ver por dentro” o trato vocal e os pulmões usando apenas o som gravado, construindo uma ponte entre o que ouvimos por fora e o que o corpo faz por dentro—rápido o suficiente para ser útil em feedback em tempo real e em futuras ferramentas inteligentes de treino vocal.
Por que a Forma da Garganta Importa
A cor e o caráter de uma voz—seu timbre—decorrem de uma dança delicada entre a forma do trato vocal e a forma como o ar flui dos pulmões. Pequenos deslocamentos da língua, do palato mole ou da mandíbula, e mudanças sutis na pressão do ar, podem fazer a mesma nota soar brilhante, sombria, tensa ou relaxada. Modelos computacionais existentes conseguem imitar vozes, mas geralmente se comportam como caixas‑pretas: não revelam o que está acontecendo fisicamente dentro do corpo e muitas vezes falham quando aplicados a novos falantes com anatomia diferente. Este trabalho aborda essa lacuna ao focar não apenas em copiar o som, mas em recuperar a geometria subjacente e os padrões respiratórios que o produzem.
Construindo um Retrato Rico a Partir de Muitos Sinais
Para ancorar o modelo na fisiologia real, os pesquisadores primeiro criaram um grande conjunto de dados com 1.000 voluntários adultos, incluindo cantores treinados e não profissionais. Durante tarefas vocais cuidadosamente projetadas—vogais sustentadas e varreduras de tom—registraram vários sinais simultaneamente: imagens por ultrassom de alta velocidade dos tecidos próximos às pregas vocais, pressão abdominal mostrando quão fortemente os sujeitos sustentavam o som, movimento 3D do tórax e do abdome, e áudio de alta fidelidade. Todas essas correntes foram alinhadas numa grade temporal comum com apenas meio milissegundo de separação. Verificações sofisticadas garantiram que causa e efeito fizessem sentido físico—por exemplo, pulsos de pressão respiratória tinham de preceder mudanças na sonoridade por um atraso realista, e estimativas de rigidez tecidual tinham de permanecer fisiologicamente plausíveis. O resultado é um filme sincronizado e fisicamente consistente de como o corpo e o som evoluem juntos.
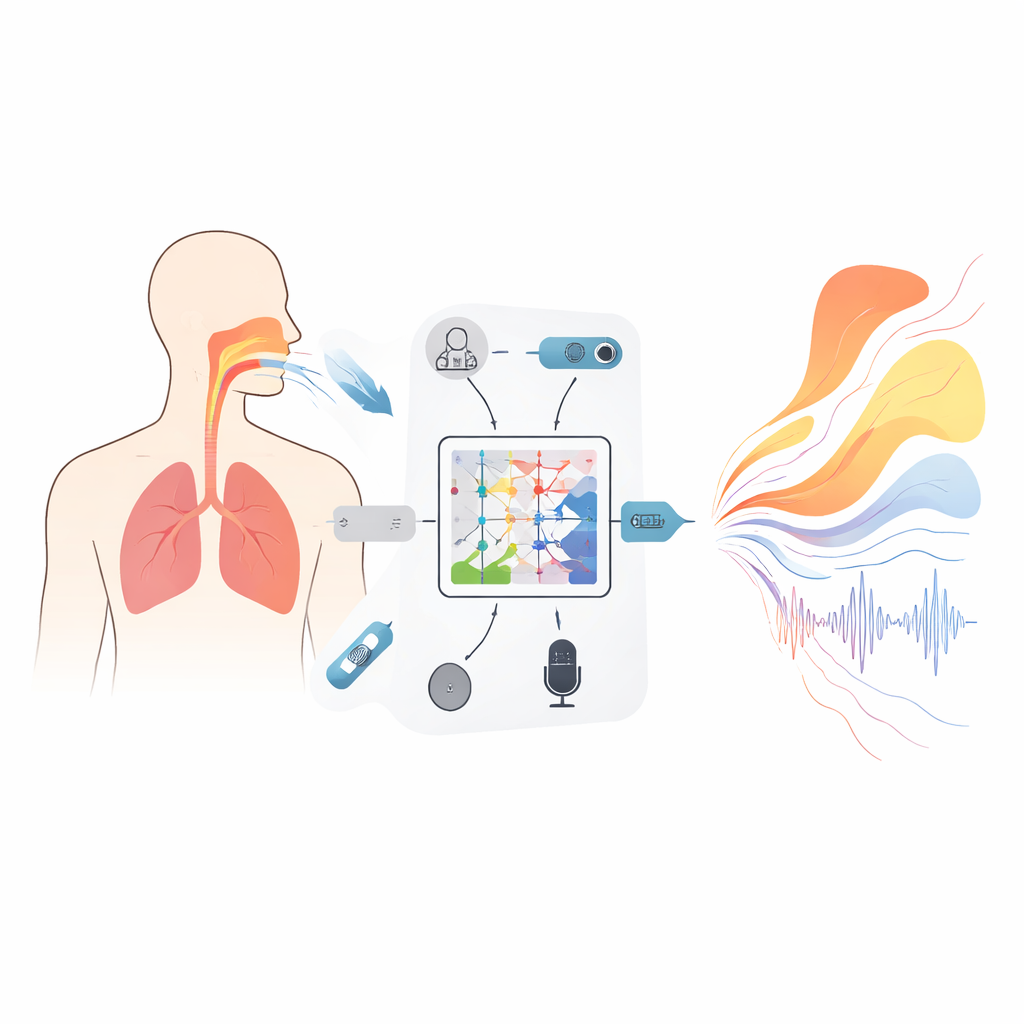
Um Novo Tipo de Modelo que Respeita a Física
No núcleo da estrutura está uma ferramenta matemática chamada operador neural Kolmogorov–Arnold (KAN), adaptada aqui para aprender como funções inteiras mapeiam para outras funções—por exemplo, como um espectro de áudio sobre frequência se mapeia para uma curva que descreve a área da seção transversal do trato vocal ao longo do seu comprimento. Em vez de funções de ativação fixas, cada unidade nesta rede usa curvas spline flexíveis que podem se curvar para capturar detalhes finos da relação entre som e forma. Uma estrutura aninhada de três camadas refina progressivamente esse mapeamento para estimar as áreas em 19 localizações, da glote aos lábios, enquanto termos extras no objetivo de treinamento desencorajam saltos ou fechamentos impossíveis que impediriam a fonação. Um módulo recorrente acompanhante segue como as diferenças de pressão através do diafragma evoluem no tempo, com restrições incorporadas derivadas da mecânica básica para que os padrões respiratórios inferidos não mudem mais rápido do que os músculos reais conseguem responder.
Aproximando‑se do Detalhe da Respiração e do Timbre
Além de reconstruir anatomia e fluxo de ar, o sistema também investiga o grão fino do próprio som. Uma cabeça de predição de “super‑resolução” toma a fisiologia recuperada como entrada e gera um espectro extremamente detalhado, atualizando tão frequentemente quanto a cada décimo de milissegundo. Ao entrelaçar ferramentas de cálculo de ordem fracionária e penalizar violações da equação de onda que governa o som no trato vocal, essa cabeça restaura flutuações minúsculas em altura e intensidade—conhecidas como jitter e shimmer—sem inventar energia não física fora da banda de frequência gravada. Na faixa de 1,2–2,4 kHz, especialmente importante para timbre e identidade vocal, o método reduziu erros espectrais em mais da metade em comparação com vários operadores neurais de referência. Também rodou rápido e leve o suficiente em um dispositivo classe Raspberry Pi para manter atrasos de processamento abaixo de cerca de 20 milissegundos.
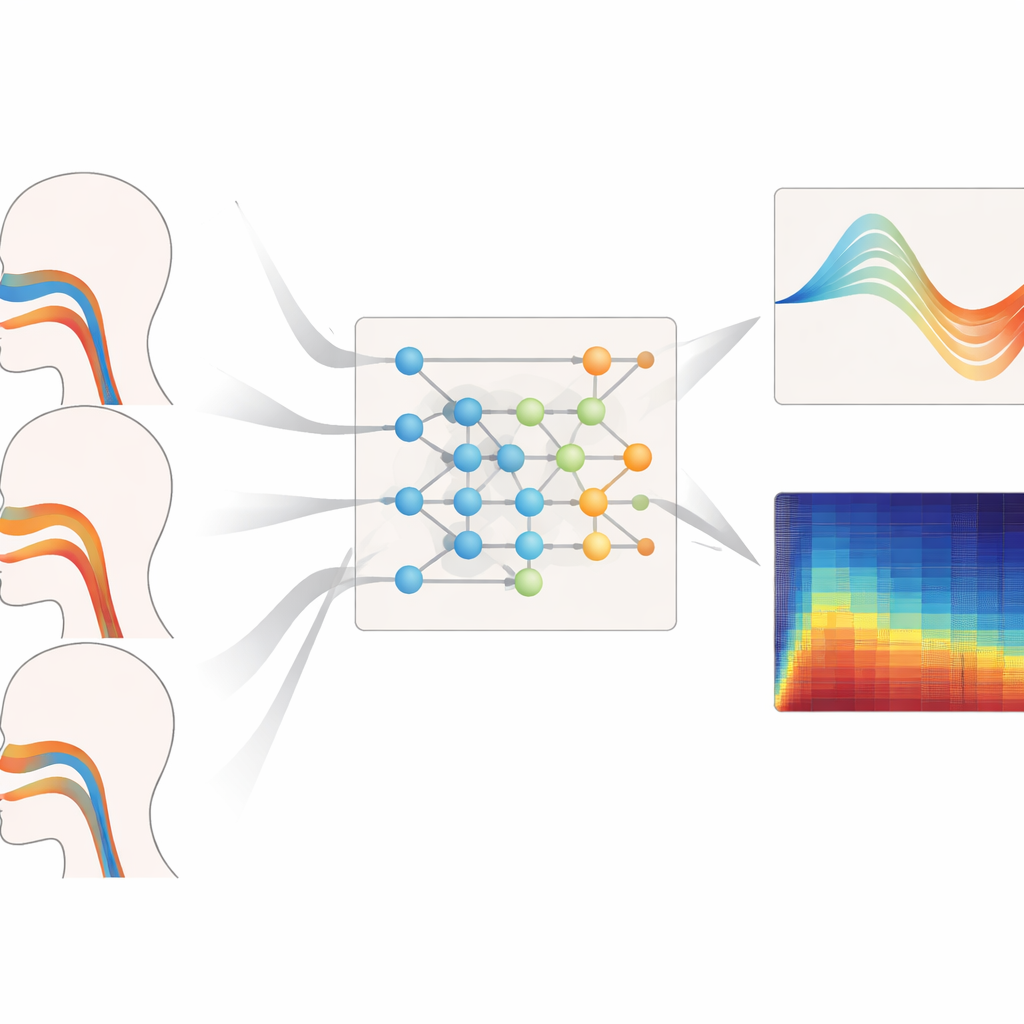
Quão Bem Funciona Entre Diferentes Vozes
Os autores testaram rigorosamente sua estrutura em diferentes faixas de pitch, estilos de canto e tipos de vozes não vistos. Ao reconstruir a geometria do trato vocal para vozes graves, de média e agudas, seu modelo consistentemente produziu os menores erros de área e a maior correspondência com formas de referência, especialmente em pitches altos onde o trato vocal precisa se deformar mais dramaticamente. Ofereceu igualmente as estimativas mais confiáveis da pressão respiratória durante trechos legato, staccato e frases com variação de intensidade, com atrasos curtos e cursos temporais suaves e realistas para músculos. Mesmo quando avaliado em sopranos e baixos cujos dados foram completamente retidos durante o treinamento, o sistema manteve erros baixos de geometria e pressão, sugerindo que aprendeu princípios gerais de controle vocal em vez de memorizar indivíduos.
O Que Isso Significa para Cantores e Professores
Em termos práticos, este trabalho mostra que é possível inferir como uma pessoa está moldando sua garganta e controlando sua respiração diretamente a partir do som que produz, de maneira precisa e fundamentada na física básica. O modelo transforma a qualidade elusiva do timbre em curvas interpretáveis: quão larga é cada parte do trato vocal, como a pressão abdominal sobe e desce, e como ondulações sutis de altura e intensidade se desenrolam ao longo do tempo. Embora o estudo ainda não teste resultados de aprendizagem em aulas reais, ele estabelece a base técnica para futuras ferramentas que poderiam fornecer a cantores feedback em tempo real e consciente da anatomia, adaptado aos próprios corpos, e para clínicos que precisam de visão não invasiva sobre como as vozes dos pacientes são produzidas.
Citação: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Palavras-chave: modelagem do trato vocal, dinâmica respiratória, análise do timbre vocal, redes neurais informadas pela física, treinamento vocal personalizado