Clear Sky Science · ru
Интерпретируемое обратное восстановление формы вокального тракта и дыхания с помощью физически-информированных нейронных операторов
Слушая внутреннюю работу голоса
Когда мы слышим красивый певческий голос, мы редко вспоминаем о движущихся частях, которые его создают: извитом воздушном канале от глотки до губ, легких, выталкивающих воздух, и крошечных мышцах, формирующих каждую ноту. Педагоги по голосу и врачи, однако, очень заинтересованы в этих скрытых движениях. В этом исследовании показан способ «заглянуть внутрь» вокального тракта и легких, имея в распоряжении только записанный звук, создав мост между тем, что мы слышим снаружи, и тем, что происходит внутри тела — достаточно быстро, чтобы это могло пригодиться для обратной связи в реальном времени и будущих умных инструментов для вокальной подготовки.
Почему форма горла имеет значение
Окраска и характер голоса — его тембр — возникают из тонкого взаимодействия между формой вокального тракта и потоком воздуха из легких. Небольшие смещения языка, мягкого неба или челюсти и едва заметные изменения давления дыхания могут заставить одну и ту же ноту звучать ярко, тёмно, напряженно или расслабленно. Существующие компьютерные модели умеют имитировать голоса, но обычно ведут себя как «чёрные ящики»: они не раскрывают, что физически происходит внутри тела, и часто дают сбой при применении к новым исполнителям с другой анатомией. Эта работа закрывает этот пробел, сосредоточившись не только на копировании звука, но и на восстановлении базовой геометрии и дыхательных паттернов, которые его порождают.
Построение детальной картины из множества сигналов
Чтобы привязать модель к реальной физиологии, исследователи сначала собрали большую базу данных от 1000 взрослых добровольцев, включая как подготовленных певцов, так и непрофессионалов. Во время специально разработанных вокальных заданий — протяжных гласных и скользящих высот — они одновременно записывали несколько сигналов: высокоскоростные УЗИ-снимки тканей возле голосовых связок, давление в брюшной полости, показывающее силу поддержания звука, 3D‑движение грудной клетки и живота, а также высококачественный аудиосигнал. Все эти потоки были синхронизированы по единой временной сетке с шагом всего полмиллисекунды. Сложные проверки гарантировали, что причинность и следствие имеют физический смысл — например, импульсы давления дыхания должны предшествовать изменениям громкости с реалистичной задержкой, а оценки жесткости тканей должны оставаться физиологически правдоподобными. В результате получился синхронизированный, физически согласованный «фильм» о том, как тело и звук развиваются вместе.
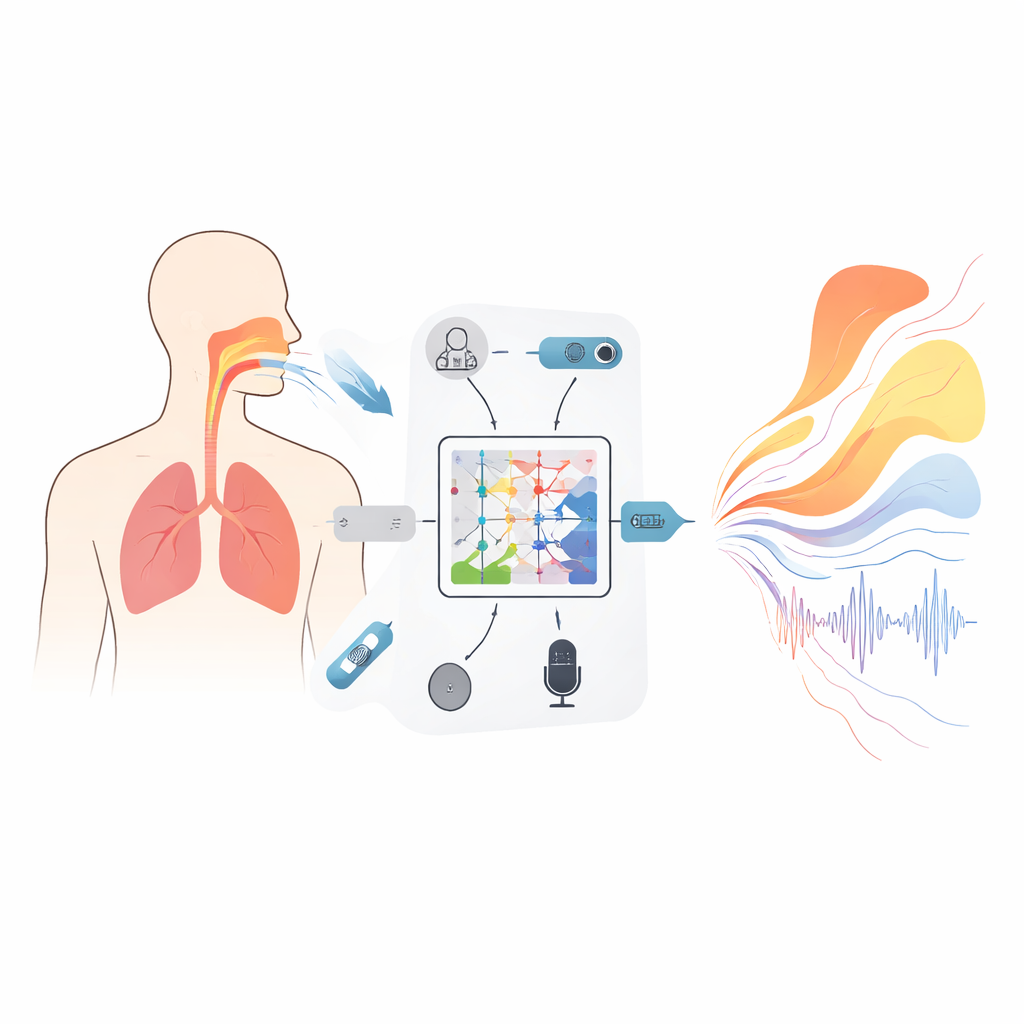
Новый тип модели, уважающей законы физики
В основе фреймворка лежит математический инструмент, называемый нейронным оператором Колмогорова–Арнольда (KAN), адаптированный здесь для обучения отображения целых функций в другие функции — например, того, как спектр аудиосигнала по частоте отображается в кривую, описывающую площадь поперечного сечения вокального тракта вдоль его длины. Вместо фиксированных функций активации каждый узел в этой сети использует гибкие сплайновые кривые, которые могут изгибаться, чтобы уловить тонкие детали связи между звуком и формой. Трёхслойная вложенная структура шаг за шагом уточняет это отображение, оценивая площади в 19 точках от голосовой щели до губ, а дополнительные члены в целевой функции обучения препятствуют невозможным скачкам или смыканиям, которые не позволили бы фонации. Сопровождающий рекуррентный модуль отслеживает, как изменяются с течением времени перепады давления через диафрагму, с встроенными ограничениями, выведенными из базовой механики, чтобы выведенные дыхательные шаблоны не менялись быстрее, чем это способны сделать реальные мышцы.
Уточнение деталей дыхания и тембра
Помимо восстановления анатомии и потока воздуха, система также вникает в тонкую структуру самого звука. Голова предсказания «сверхразрешения» принимает восстановленную физиологию на входе и генерирует чрезвычайно детализированный спектр, обновляя его с частотой до одной десятичной миллисекунды. Включив инструменты дробно-порядкового исчисления и штрафуя нарушения волнового уравнения, управляющего звуком в вокальном тракте, эта часть восстанавливает крошечные флуктуации высоты и громкости — известные как джиттер и шиммер — не создавая нефизической энергии за пределами записанной полосы частот. В диапазоне 1.2–2.4 кГц, особенно важном для тембра и идентичности голоса, метод сократил спектральные ошибки более чем вдвое по сравнению с несколькими ведущими нейронными операторами. Он также работал достаточно быстро и экономично на устройствах класса Raspberry Pi, удерживая задержки обработки примерно ниже 20 миллисекунд.
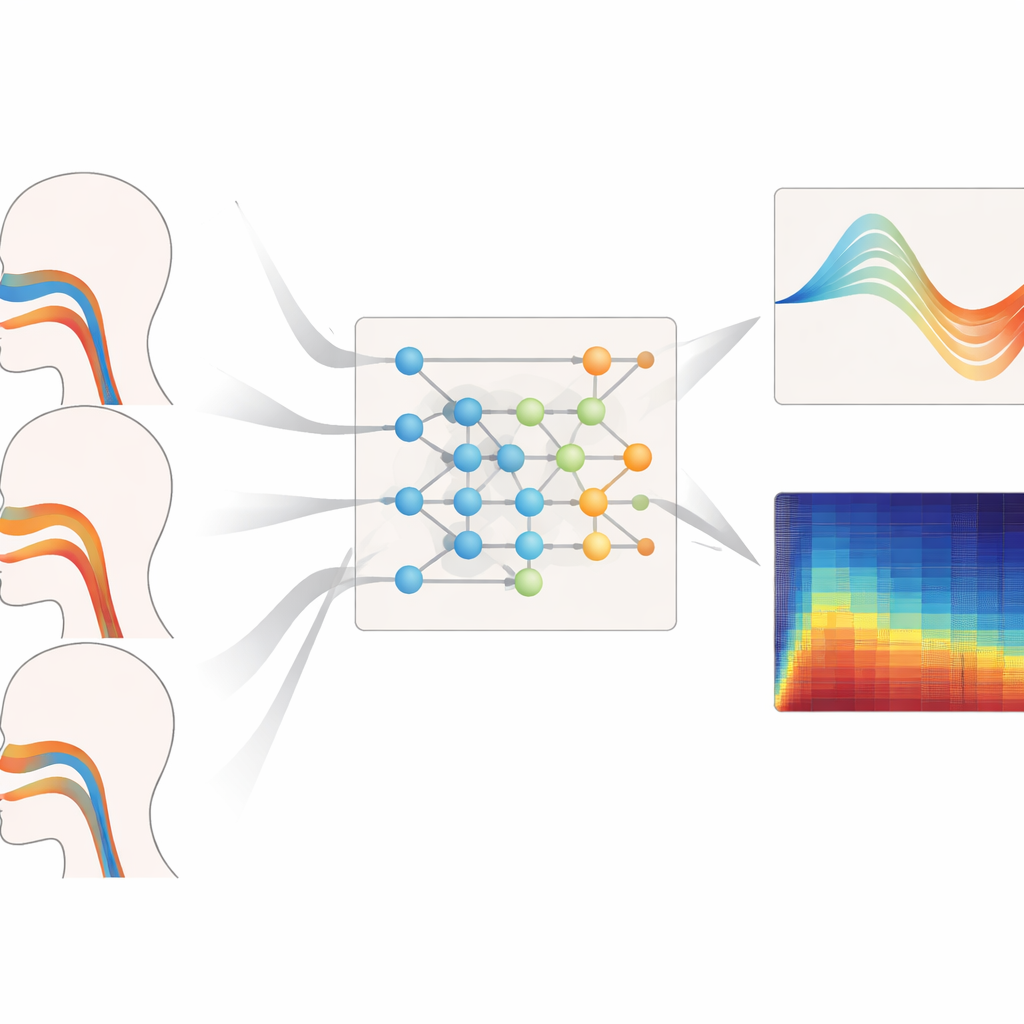
Эффективность на разных голосах
Авторы подвергли своё решение стресс‑тестам в различных диапазонах высоты, стилях пения и на невидимых типах голосов. При задаче восстановить геометрию вокального тракта для басов, теноров среднего диапазона и высоких голосов их модель последовательно давала наименьшие ошибки площадей и наилучшее совпадение с эталонными формами, особенно в высоких регистрах, где вокальный тракт должен деформироваться более драматично. Она также давала наиболее надежные оценки дыхательного давления при легато, стаккато и фразах со сменой громкости, с короткими задержками и плавными, мышечно‑реалистичными временными профилями. Даже при оценке сопрано и басов, чьи данные полностью исключались из обучения, система сохраняла низкие ошибки по геометрии и давлению, что указывает на то, что она усвоила общие принципы контроля голоса, а не запомнила отдельных исполнителей.
Что это значит для певцов и педагогов
Проще говоря, эта работа показывает, что можно восстановить, как человек формирует горло и управляет дыханием, прямо по звуку, который он издаёт, и сделать это точно и в соответствии с базовой физикой. Модель превращает неуловимое качество тембра в интерпретируемые кривые: насколько широко раскрыта каждая часть вокального тракта, как в брюшной полости поднимается и опускается давление и как разворачиваются тонкие волны высоты и громкости во времени. Хотя в исследовании пока не проверяли учебные результаты в реальных уроках, оно закладывает техническую основу для будущих инструментов, которые могли бы предоставлять певцам обратную связь в реальном времени, учитывающую анатомию конкретного человека, а также для клиницистов, которым нужна неинвазивная информация о механизмах производства голоса у пациентов.
Цитирование: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Ключевые слова: моделирование вокального тракта, динамика дыхания, анализ тембра голоса, нейронные сети с учетом физики, персонализированная вокальная тренировка