Clear Sky Science · it
Inversione interpretabile del tratto vocale e respiratorio tramite operatori neurali informati dalla fisica
Ascoltare dall'interno la voce
Quando sentiamo una voce da canto bella, raramente pensiamo ai pezzi in movimento che la producono: il passaggio d'aria tortuoso dalla gola alle labbra, i polmoni che spingono l'aria e i piccoli muscoli che modellano ogni nota. Insegnanti di canto e medici, tuttavia, sono profondamente interessati a questi moti nascosti. Questo studio introduce un modo per “guardare dentro” il tratto vocale e i polmoni usando solo il suono registrato, costruendo un ponte tra ciò che udiamo all'esterno e ciò che il corpo sta facendo all'interno—abbastanza rapido da risultare utile per un feedback in tempo reale e per futuri strumenti intelligenti di allenamento vocale.
Perché la forma della gola conta
Il colore e il carattere di una voce—il suo timbro—nascono da una danza delicata tra la forma del tratto vocale e il modo in cui l'aria fluisce dai polmoni. Piccoli spostamenti di lingua, velo palatino o mandibola, e sottili variazioni nella pressione dell'aria, possono rendere la stessa nota brillante, scura, tesa o rilassata. I modelli informatici esistenti possono imitare le voci, ma di solito si comportano come scatole nere: non rivelano cosa sta accadendo fisicamente all'interno del corpo e spesso falliscono quando applicati a nuovi parlanti con anatomie diverse. Questo lavoro colma quel vuoto concentrandosi non solo sulla copia del suono, ma sul recupero della geometria sottostante e dei modelli respiratori che lo producono.
Costruire un quadro ricco da molti segnali
Per ancorare il modello alla fisiologia reale, i ricercatori hanno prima creato un ampio set di dati da 1.000 volontari adulti, comprendendo sia cantanti addestrati sia non professionisti. Durante compiti vocali progettati con cura—vocali sostenute e scivolate di intonazione—hanno registrato diversi segnali contemporaneamente: immagini ecografiche ad alta velocità dei tessuti vicino alle corde vocali, pressione addominale che mostra quanto i soggetti supportavano il suono, movimento 3D del torace e dell'addome e audio ad alta fedeltà. Tutte queste serie sono state allineate su una griglia temporale comune con passi di soli mezzo millisecondo. Controlli sofisticati hanno garantito che causa ed effetto avessero senso fisico—forse, per esempio, gli impulsi di pressione del respiro dovevano precedere i cambiamenti di intensità con un ritardo realistico, e le stime della rigidità dei tessuti dovevano rimanere fisiologicamente plausibili. Il risultato è un film sincronizzato e fisicamente coerente di come corpo e suono evolvono insieme.
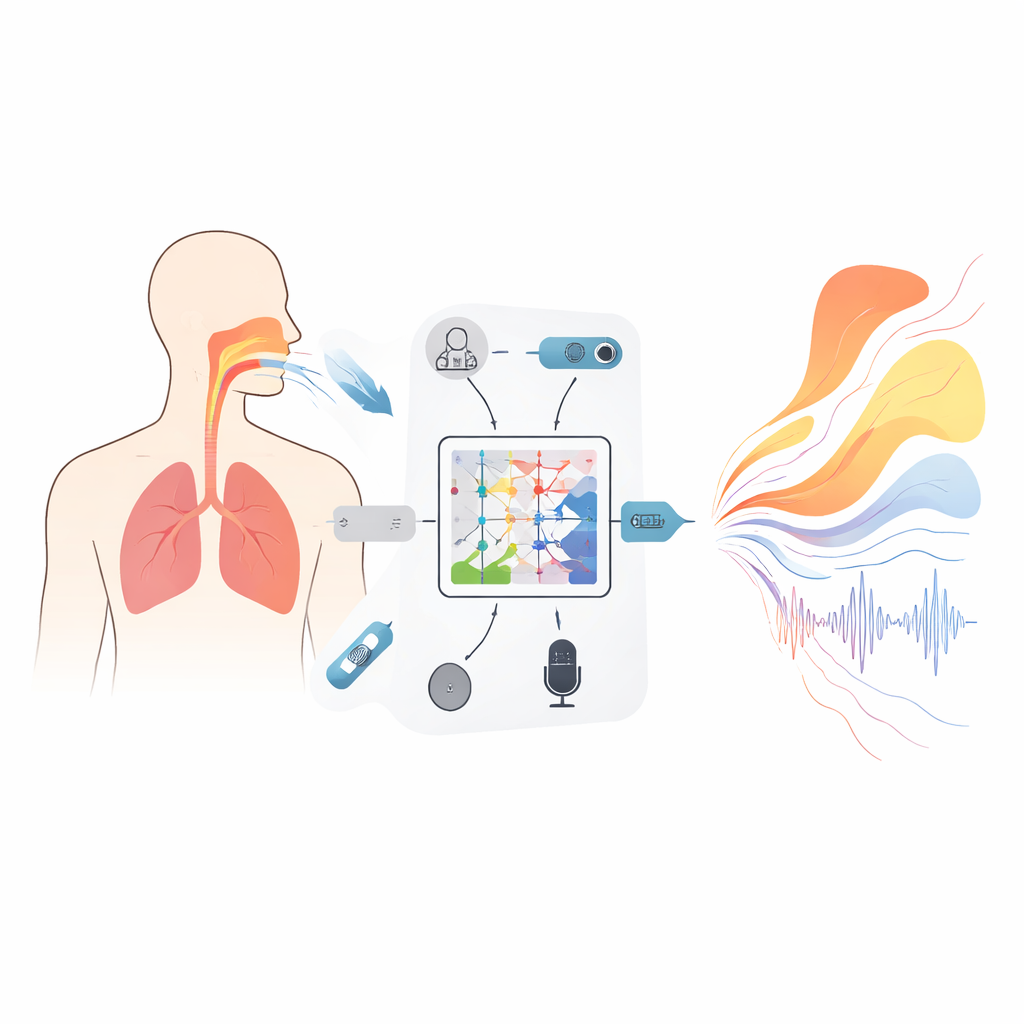
Un nuovo tipo di modello che rispetta la fisica
Al centro del quadro c'è uno strumento matematico chiamato operatore neurale Kolmogorov–Arnold (KAN), adattato qui per apprendere come intere funzioni si mappano su altre funzioni—per esempio, come uno spettro audio in frequenza si mappa su una curva che descrive l'area della sezione trasversale del tratto vocale lungo la sua lunghezza. Invece delle funzioni di attivazione fisse, ogni unità di questa rete usa curve spline flessibili che possono piegarsi per catturare dettagli fini della relazione tra suono e forma. Una struttura annidata a tre strati affina progressivamente questa mappatura per stimare le aree in 19 posizioni dalla glottide alle labbra, mentre termini aggiuntivi nell'obiettivo di addestramento scoraggiano salti o chiusure impossibili che impedirebbero la fonazione. Un modulo ricorrente complementare segue come le differenze di pressione attraverso il diaframma evolvono nel tempo, con vincoli incorporati derivati dalla meccanica di base affinché i modelli respiratori inferiti non cambino più rapidamente di quanto i muscoli reali possano gestire.
Zoom su dettaglio di respiro e timbro
Oltre a ricostruire anatomia e flusso d'aria, il sistema si concentra anche sul grano fine del suono stesso. Una testa di previsione a “super-risoluzione” prende in input la fisiologia recuperata e genera uno spettro estremamente dettagliato, aggiornando fino a ogni decimo di millisecondo. Integrando strumenti della calculo frazionario e penalizzando le violazioni dell'equazione d'onda che governa il suono nel tratto vocale, questa componente ripristina piccole fluttuazioni di intonazione e intensità—note come jitter e shimmer—senza inventare energia non fisica al di fuori della banda di frequenza registrata. Nell'intervallo 1,2–2,4 kHz, particolarmente importante per il timbro e l'identità vocale, il metodo ha ridotto gli errori spettrali di oltre la metà rispetto a diversi operatori neurali di riferimento. Ha inoltre girato in modo abbastanza veloce e leggero su un dispositivo di classe Raspberry Pi mantenendo i ritardi di elaborazione sotto circa 20 millisecondi.
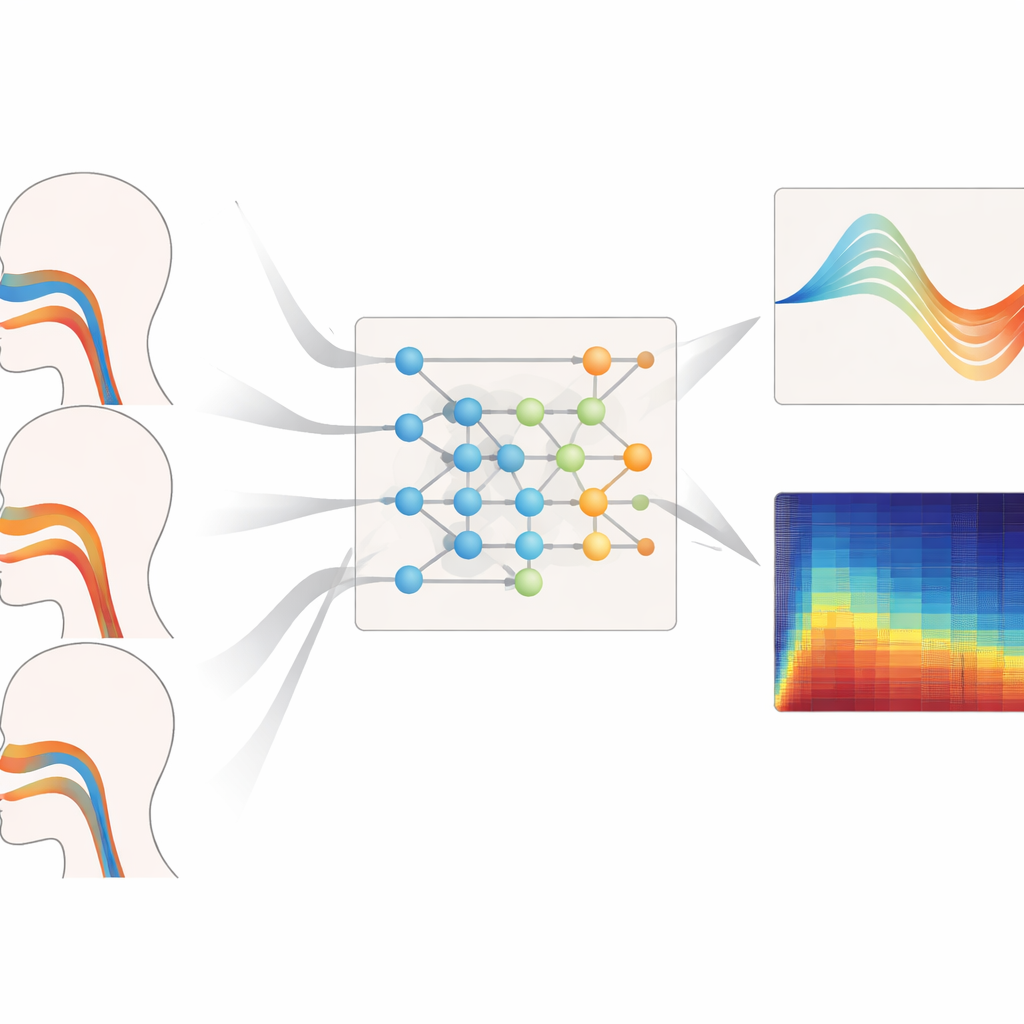
Quanto funziona bene su voci diverse
Gli autori hanno sottoposto il loro quadro a test intensivi su diverse gamme di altezza, stili di canto e tipi di voce non visti. Quando sono stati incaricati di ricostruire la geometria del tratto vocale per voci basse, medie e acute, il loro modello ha prodotto costantemente gli errori di area più piccoli e la corrispondenza più forte con le forme di verità terreno, specialmente alle alte frequenze dove il tratto vocale deve deformarsi più drasticamente. Ha offerto analogamente le stime più affidabili della pressione respiratoria durante frasi legato, staccato e con variazioni di intensità, con ritardi brevi e corsi temporali lisci e realistici a livello muscolare. Anche valutato su soprani e bassi i cui dati erano completamente esclusi dall'addestramento, il sistema ha mantenuto bassi errori di geometria e pressione, suggerendo di aver appreso principi generali del controllo vocale anziché memorizzare parlanti individuali.
Cosa significa per cantanti e insegnanti
In termini quotidiani, questo lavoro mostra che è possibile inferire come una persona modella la gola e gestisce il respiro direttamente dal suono che produce, in modo sia accurato sia radicato nella fisica di base. Il modello trasforma la qualità elusiva del timbro in curve interpretabili: quanto è ampia ogni parte del tratto vocale, come la pressione nell'addome sale e scende e come sottili increspature di intonazione e intensità si sviluppano nel tempo. Pur non testando ancora gli esiti dell'apprendimento in lezioni reali, pone le basi tecniche per futuri strumenti che potrebbero fornire ai cantanti un feedback in tempo reale, consapevole dell'anatomia e tarato sul loro corpo, e per i clinici che necessitano di approfondimenti non invasivi su come vengono prodotte le voci dei pazienti.
Citazione: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Parole chiave: modellazione del tratto vocale, dinamica respiratoria, analisi del timbro vocale, reti neurali informate dalla fisica, allenamento vocale personalizzato