Clear Sky Science · ja
物理インフォームドニューラルオペレータによる解釈可能な声道・呼吸逆問題
声の内部を聴く
美しい歌声を耳にしたとき、私たちはそれを生み出す可動部分――喉から唇までねじれた空気路、空気を押し出す肺、そして一音一音の形を作る小さな筋肉――について考えることはほとんどありません。しかし声楽教師や医師は、これらの隠れた動きに深い関心を持っています。本研究は、録音された音だけから声道と肺の「内部を見る」方法を提示し、外側で聞こえる音と体内で起きていることの間に橋を架けます。リアルタイムのフィードバックや将来のスマートな発声トレーニングツールに十分な速度で動作することを目指しています。
なぜ喉の形が重要なのか
声の色合いや性格――音色(ティンバー)は、声道の形と肺からの気流の繊細な相互作用から生まれます。舌、軟口蓋、顎のわずかな位置変化や呼気圧の微妙な変動が、同じ音を明るく、暗く、張ったように、あるいはリラックスしたように聞かせます。既存のコンピュータモデルは音を模倣できますが、しばしばブラックボックスのように振る舞い、体内で何が物理的に起きているかを明らかにせず、異なる解剖を持つ新しい話者に適用すると失敗することが多いです。本研究は、単に音を再現するだけでなく、それを生み出す基礎となる幾何学と呼吸パターンの復元に重点を置くことで、そのギャップに取り組みます。
多様な信号から豊かな図を構築する
モデルを実際の生理に根づかせるため、研究者たちはまず1,000人の成人参加者(訓練を受けた歌手と非専門家を含む)からなる大規模データセットを作成しました。持続母音やピッチスライドといった慎重に設計された発声課題の最中に、複数の信号を同時に記録しました:声帯付近の組織を撮る高速超音波画像、音を支える力を示す腹部圧力、胸と腹の3D運動、高忠実度オーディオ。これらの全ストリームは共通のタイムグリッド上で0.5ミリ秒刻みという高い時間分解能で整列されました。高度な整合チェックにより因果関係が物理的に妥当であることが保証されます。例えば、呼気圧のパルスは現実的な遅延で大きさ(ラウドネス)の変化に先行しなければならず、組織の剛性推定値は生理的にあり得る範囲にとどまらなければなりません。その結果、身体と音がどのように共進化するかを示す、同期化され物理的一貫性を持ったムービーが得られました。
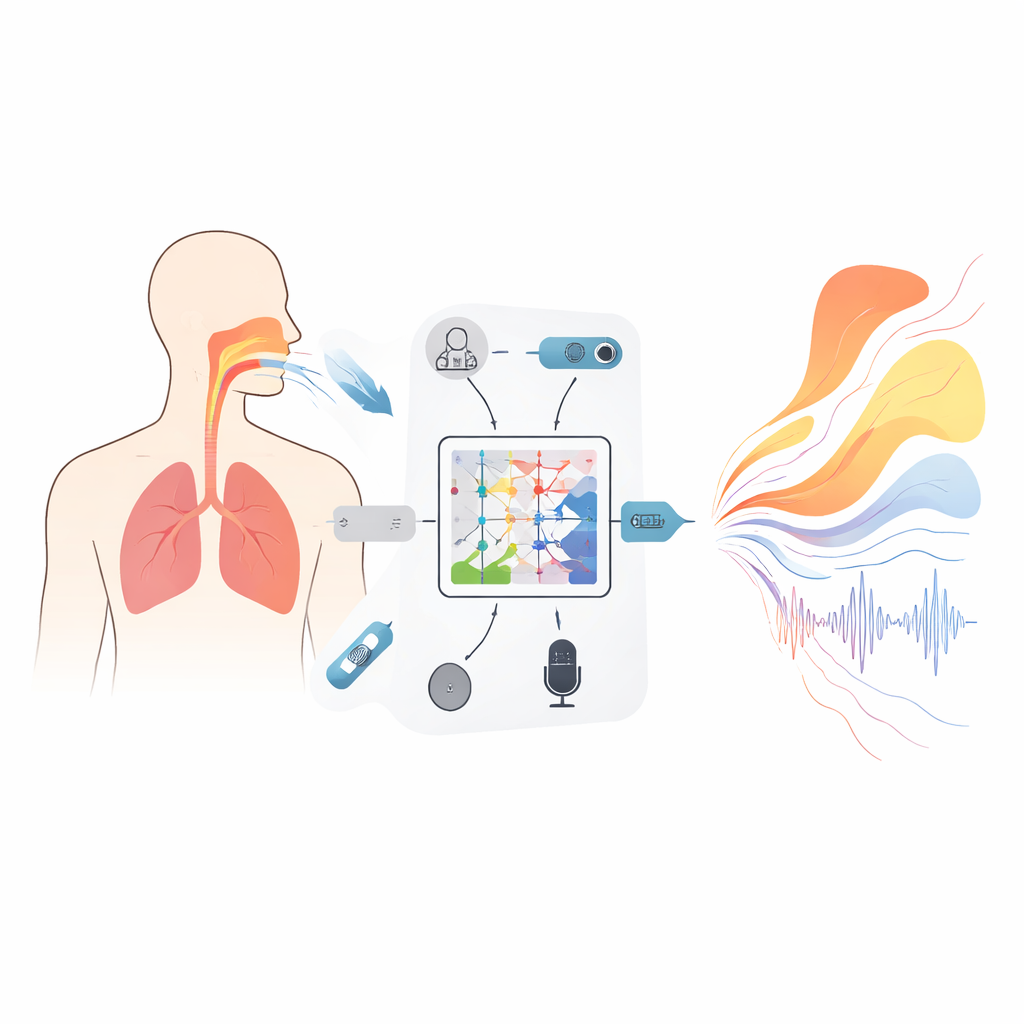
物理を尊重する新しい種類のモデル
この枠組みの中心には、Kolmogorov–Arnoldニューラル(KAN)オペレータと呼ばれる数学的道具があり、ここでは関数全体から別の関数への写像を学習するように適用されています。例えば、周波数に対するオーディオスペクトルが、声道長に沿った横断面積を記述する曲線へどのように対応するかを学びます。固定的な活性化関数の代わりに、このネットワークの各ユニットは関係性の微細な部分を捉えるために曲げられる柔軟なスプライン曲線を用います。三層の入れ子構造が段階的にこの写像を精緻化し、声門から唇までの19か所の面積を推定します。訓練目的関数には、発声を不可能にするような不連続な飛躍や閉塞を抑制する項も含まれます。付随する再帰モジュールは横隔膜を越える圧力差が時間とともにどのように変化するかを追い、基本的な力学に由来する制約を組み込むことで、推定される呼吸パターンが実際の筋肉が扱える速さ以上に変化しないようにしています。
呼吸と音色の細部にズームイン
解剖学と気流の再構築を超えて、システムは音そのものの微細な粒度にも着目します。回復した生理情報を入力として受け取り、極めて詳細なスペクトルを生成する「超解像」予測ヘッドは、最短で0.1ミリ秒ごとに更新します。分数階微分を含む解析ツールを織り込み、声道内の音を支配する波動方程式の違反を罰することで、このヘッドはピッチやラウドネスの微小な揺らぎ(ジッターやシマー)を、記録された周波数帯外に非物理的なエネルギーを生み出すことなく復元します。特に音色や声の個性に重要な1.2–2.4 kHzの帯域では、主要なニューラルオペレータのベースラインと比べてスペクトル誤差を半分以上削減しました。さらに、処理遅延を約20ミリ秒以下に保てるほど軽量かつ高速にRaspberry Piクラスのデバイス上でも動作しました。
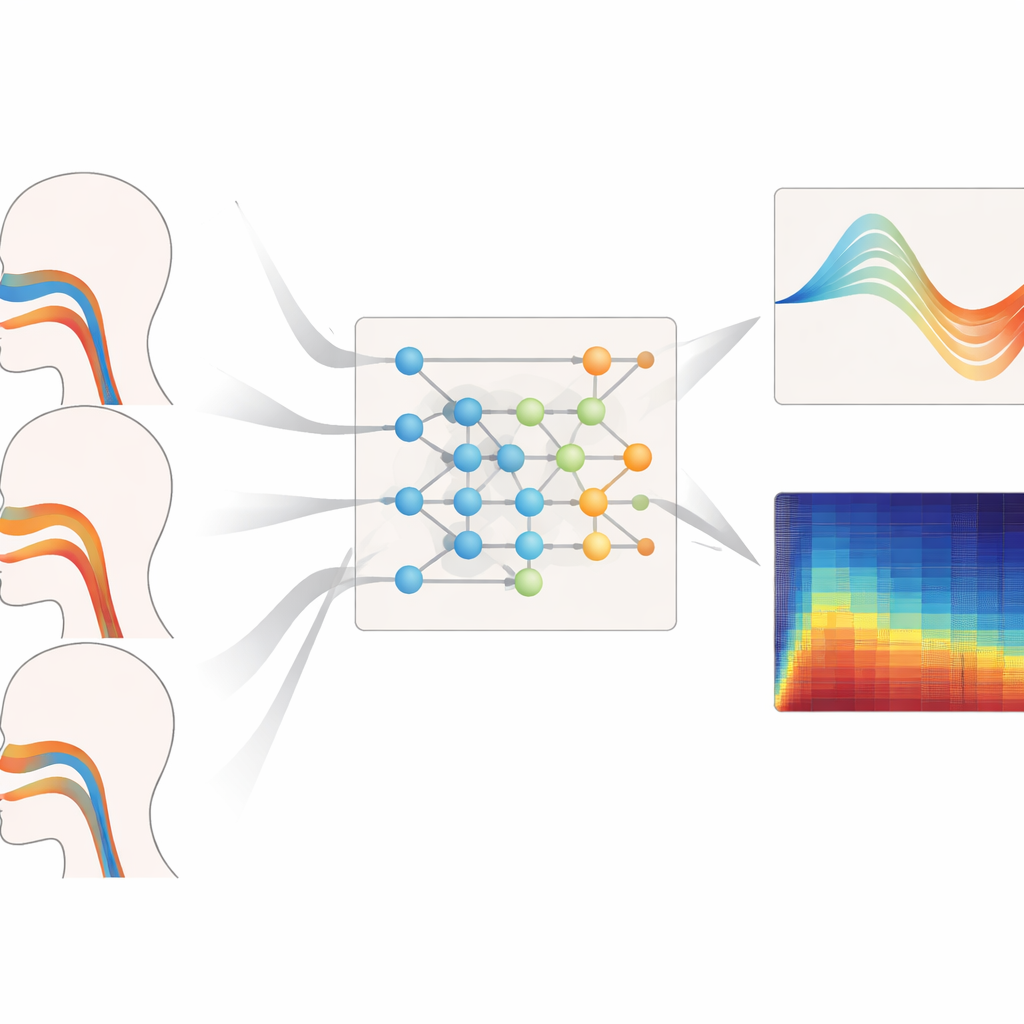
声種を超えた性能
著者らは、異なるピッチ帯、歌唱スタイル、未見の声種に対してフレームワークを厳しく試験しました。低音域、中音域、高音域の声に対して声道幾何の再構成を課した際、同モデルは一貫して最小の面積誤差と基準形状との最も強い一致を示しました。特に声道がより劇的に変形する高音域で顕著でした。同様に、レガート、スタッカート、音量変化を伴うフレーズにおける呼気圧の推定でも、短い遅延と滑らかで筋肉の挙動に現実的な時間経過を示す最も信頼できる推定を提供しました。訓練時に完全に除外されたソプラノやバスのデータで評価しても、幾何学や圧力の誤差は低いままでした。これは、モデルが個々の話者を単に記憶するのではなく、発声制御の一般原理を学習していることを示唆します。
歌手と教師にとっての意義
日常的な言葉で言えば、この研究は人が作り出す音から直接、喉の形づくりや呼吸の扱いを正確かつ基本的な物理に根ざして推定できることを示しています。モデルは捉えどころのない音色を解釈可能な曲線に変換します:声道の各部位がどれだけ広いか、腹部の圧力がどのように上がり下がりするか、そしてピッチやラウドネスの微妙な揺らぎが時間経過でどのように展開するか。本研究はまだ実際のレッスンでの学習成果を検証していませんが、将来的に歌手へ自分の体に合わせた解剖学的に配慮したリアルタイムフィードバックを提供するツールや、患者の声がどのように生み出されるかを非侵襲的に理解したい臨床家のための技術的基盤を築きます。
引用: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
キーワード: 声道モデリング, 呼吸力学, 声の音色解析, 物理情報を組み込んだニューラルネットワーク, 個別化された発声トレーニング