Clear Sky Science · fr
Inversion interprétable du tractus vocal et de la respiration via des opérateurs neuronaux informés par la physique
Écouter à l’intérieur de la voix
Quand nous entendons une belle voix chantée, nous pensons rarement aux éléments en mouvement qui la produisent : l’airway tortueux de la gorge aux lèvres, les poumons qui poussent l’air, et les petits muscles qui sculptent chaque note. Les professeurs de chant et les médecins, en revanche, s’intéressent profondément à ces mouvements cachés. Cette étude présente une méthode pour « regarder à l’intérieur » du tractus vocal et des poumons en n’utilisant que le son enregistré, établissant un lien entre ce que nous percevons à l’extérieur et ce que le corps fait à l’intérieur — et ce, assez rapidement pour être utile en retour d’information en temps réel et pour de futurs outils intelligents de formation vocale.
Pourquoi la forme de la gorge compte
La couleur et le caractère d’une voix — son timbre — résultent d’une danse délicate entre la forme du tractus vocal et la manière dont l’air s’écoule depuis les poumons. De petits déplacements de la langue, du voile du palais ou de la mâchoire, et des variations subtiles de la pression d’air, peuvent faire sonner la même note plus brillante, plus sombre, tendue ou détendue. Les modèles informatiques existants peuvent imiter des voix, mais ils fonctionnent généralement comme des boîtes noires : ils ne révèlent pas ce qui se passe physiquement à l’intérieur du corps et échouent souvent lorsqu’on les applique à de nouveaux locuteurs ayant une anatomie différente. Ce travail comble cette lacune en visant non seulement à reproduire le son, mais à retrouver la géométrie sous‑jacente et les schémas respiratoires qui le produisent.
Construire une image riche à partir de nombreux signaux
Pour ancrer le modèle dans la physiologie réelle, les chercheurs ont d’abord créé un large jeu de données à partir de 1 000 volontaires adultes, incluant chanteurs formés et non‑professionnels. Lors de tâches vocales conçues avec soin — voyelles soutenues et glissandos — ils ont enregistré plusieurs signaux simultanément : images échographiques à grande vitesse des tissus proches des cordes vocales, pression abdominale montrant le support respiratoire, mouvement 3D du thorax et du ventre, et audio haute fidélité. Tous ces flux ont été alignés sur une grille temporelle commune avec des pas d’une demi‑milliseconde. Des vérifications sophistiquées ont assuré que cause et effet respectaient la physique — par exemple, les impulsions de pression respiratoire devaient précéder les changements d’intensité par un délai réaliste, et les estimations de raideur tissulaire devaient rester physiologiquement plausibles. Le résultat est un film synchronisé et physiquement cohérent de l’évolution conjointe du corps et du son.
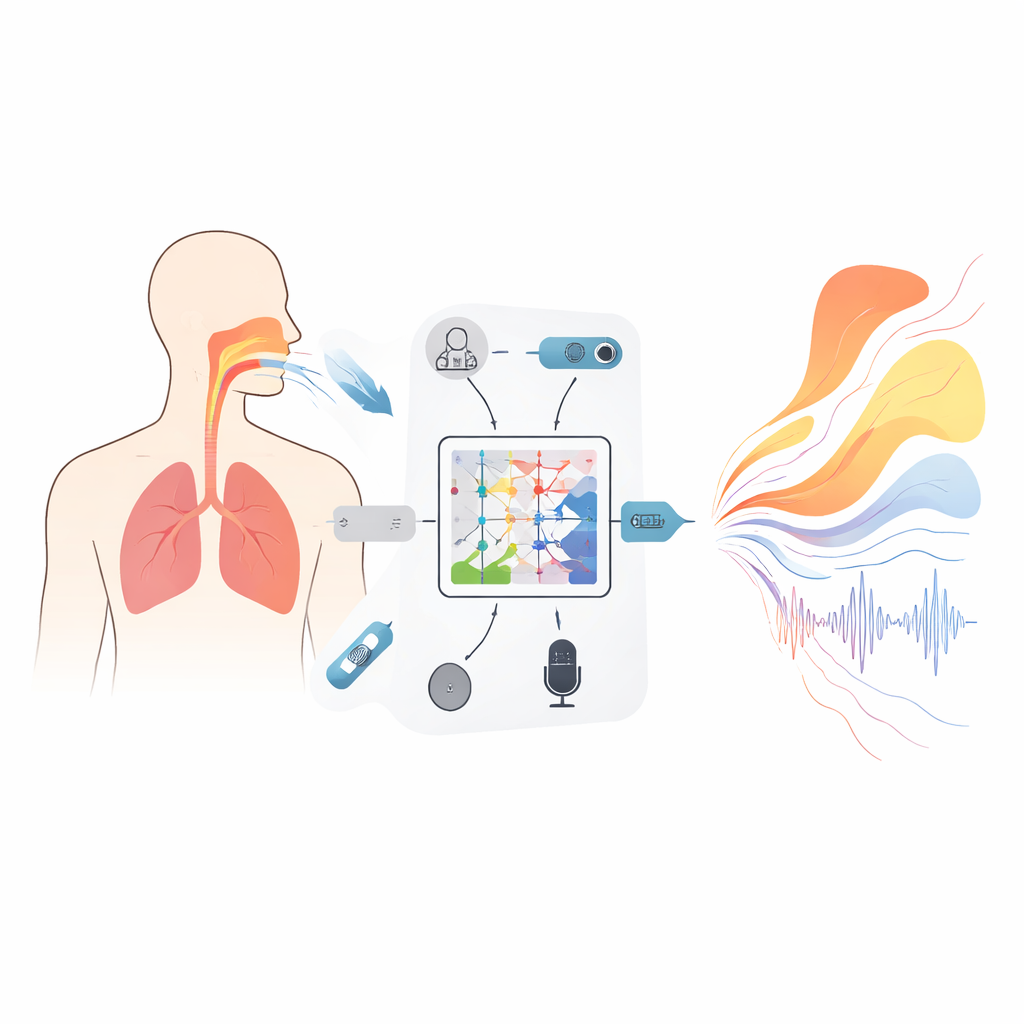
Un nouveau type de modèle qui respecte la physique
Au cœur du cadre se trouve un outil mathématique appelé opérateur neural de Kolmogorov–Arnold (KAN), adapté ici pour apprendre comment des fonctions entières se mappent sur d’autres fonctions — par exemple, comment un spectre audio en fréquence se transforme en une courbe décrivant l’aire de la section transversale du tractus vocal le long de sa longueur. Au lieu de fonctions d’activation fixes, chaque unité de ce réseau utilise des courbes spline flexibles qui peuvent se plier pour capturer des détails fins de la relation entre le son et la forme. Une structure imbriquée à trois couches affine progressivement cette cartographie pour estimer les aires en 19 positions, de la glotte aux lèvres, tandis que des termes supplémentaires dans l’objectif d’entraînement pénalisent les sauts impossibles ou les fermetures qui empêcheraient la phonation. Un module récurrent compagnon suit l’évolution temporelle des différences de pression à travers le diaphragme, avec des contraintes intégrées dérivées de la mécanique de base afin que les schémas respiratoires inférés n’évoluent pas plus vite que ce que les muscles réels peuvent produire.
Approfondir le détail du souffle et du timbre
Au‑delà de la reconstruction de l’anatomie et de l’écoulement d’air, le système s’attache aussi aux détails fins du son lui‑même. Une tête de prédiction « super‑résolution » prend en entrée la physiologie récupérée et génère un spectre extrêmement détaillé, mis à jour aussi souvent que toutes les dixièmes de millisecondes. En intégrant des outils de calcul fractionnaire et en pénalisant les violations de l’équation d’onde qui régit le son dans le tractus vocal, cette tête restaure de petites fluctuations de hauteur et d’intensité — connues sous les noms de jitter et shimmer — sans inventer d’énergie non physique en dehors de la bande de fréquence enregistrée. Dans la gamme 1,2–2,4 kHz, particulièrement importante pour le timbre et l’identité vocale, la méthode a réduit les erreurs spectrales de plus de moitié par rapport à plusieurs opérateurs neuronaux de référence. Elle a aussi tourné assez rapidement et légèrement sur un dispositif de type Raspberry Pi pour maintenir les délais de traitement sous environ 20 millisecondes.
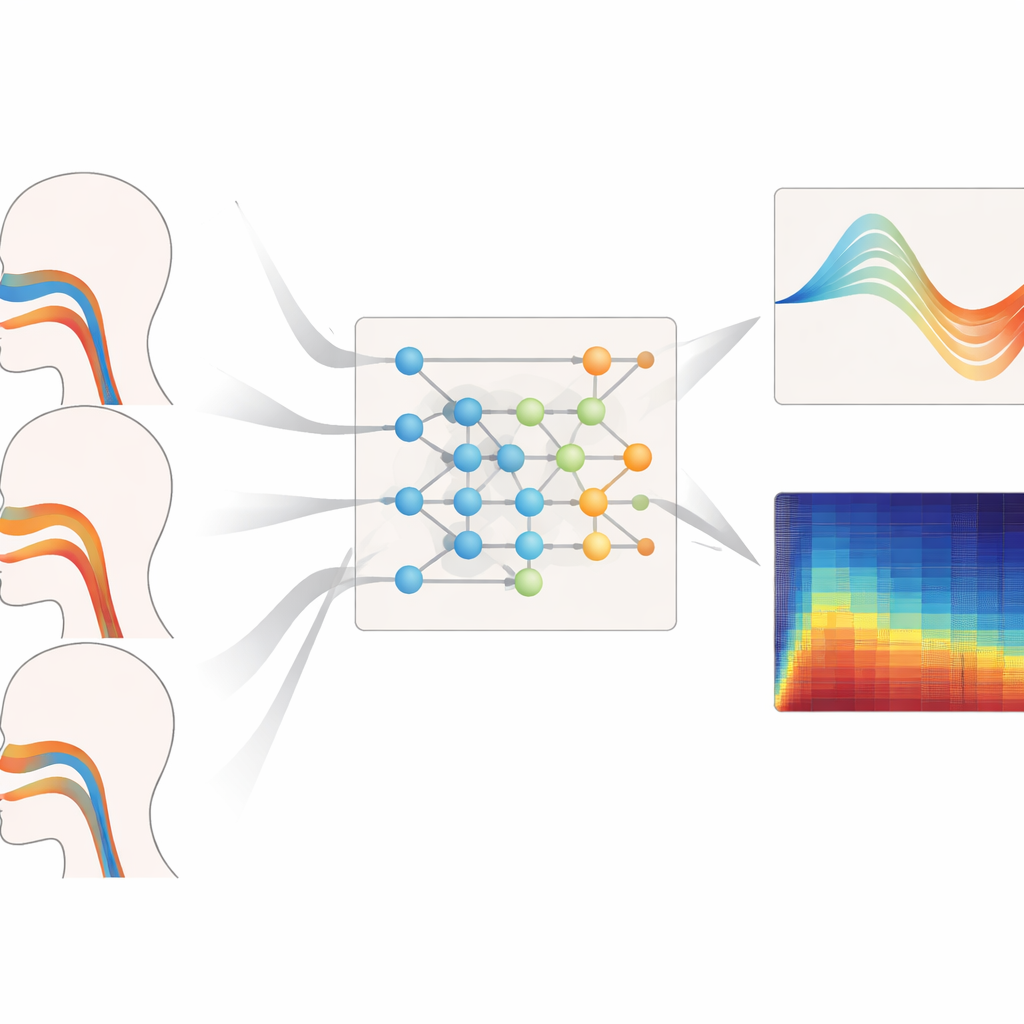
Quelle est son efficacité à travers les voix
Les auteurs ont soumis leur cadre à des tests intensifs sur différentes tessitures, styles de chant et types de voix non vues. Lors de la reconstruction de la géométrie du tractus vocal pour des voix de basse, de registre médian et aigu, leur modèle a systématiquement produit les plus faibles erreurs d’aire et la meilleure correspondance aux formes de référence, en particulier pour les hautes fréquences où le tractus vocal doit se déformer plus fortement. Il a de même fourni les estimations les plus fiables de la pression respiratoire pendant des phrases legato, staccato et à intensité variable, avec de courts délais et des trajectoires temporelles lisses et réalistes musculo‑squelettiquement. Même évalué sur des sopranos et des basses dont les données avaient été complètement exclues de l’entraînement, le système a conservé de faibles erreurs de géométrie et de pression, ce qui suggère qu’il a appris des principes généraux du contrôle vocal plutôt que de mémoriser des individus.
Ce que cela signifie pour les chanteurs et les enseignants
En termes concrets, ce travail montre qu’il est possible d’inférer comment une personne façonne sa gorge et gère sa respiration directement à partir du son qu’elle produit, de manière à la fois précise et ancrée dans la physique élémentaire. Le modèle transforme la qualité insaisissable du timbre en courbes interprétables : la largeur de chaque portion du tractus vocal, la façon dont la pression abdominale monte et descend, et la manière dont de subtiles ondulations de hauteur et d’intensité se déroulent dans le temps. Si l’étude ne teste pas encore les résultats d’apprentissage dans de véritables leçons, elle jette les bases techniques d’outils futurs pouvant fournir aux chanteurs un retour en temps réel, conscient de l’anatomie et adapté à leur propre corps, ainsi qu’aux cliniciens nécessitant un aperçu non invasif de la production vocale de leurs patients.
Citation: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Mots-clés: modélisation du tractus vocal, dynamique respiratoire, analyse du timbre vocal, réseaux neuronaux informés par la physique, formation vocale personnalisée