Clear Sky Science · de
Interpretierbare Rekonstruktion des Vokaltrakts und der Atmungsdynamik über physik‑informierte neuronale Operatoren
Im Ohr: In die Stimme hineinhören
Wenn wir eine schöne Singstimme hören, denken wir selten an die beweglichen Teile, die sie erzeugen: den sich verwinkelnden Luftweg vom Rachen bis zu den Lippen, die Lungen, die Luft drücken, und die kleinen Muskeln, die jede Note formen. Stimmlehrende und Ärztinnen bzw. Ärzte hingegen interessieren sich sehr für diese verborgenen Bewegungen. Diese Studie stellt eine Methode vor, mit der man den Vokaltrakt und die Lungen „von innen“ betrachten kann – allein aus aufgezeichnetem Schall – und damit eine Brücke zwischen dem, was wir außen hören, und dem, was der Körper innen tut. Schnell genug, um für Echtzeit‑Feedback und künftige intelligente Stimmtrainings‑Tools nützlich zu sein.
Warum die Form des Rachens zählt
Die Färbung und der Charakter einer Stimme – ihr Timbre – entstehen aus einem feinen Zusammenspiel zwischen der Form des Vokaltrakts und dem Luftstrom aus den Lungen. Kleine Verschiebungen von Zunge, Gaumensegel oder Kiefer und subtile Änderungen des Atemdrucks können dieselbe Note hell, dunkel, angespannt oder entspannt klingen lassen. Bestehende Computer‑Modelle können Stimmen nachahmen, verhalten sich dabei aber oft wie Black‑Boxes: Sie geben nicht preis, was physikalisch im Körper geschieht, und versagen häufig, wenn sie auf neue Sprecherinnen und Sprecher mit anderer Anatomie angewendet werden. Diese Arbeit schließt genau diese Lücke, indem sie sich nicht nur aufs Kopieren des Klangs konzentriert, sondern darauf, die zugrunde liegende Geometrie und die Atmungsmuster wiederzugewinnen, die den Klang erzeugen.
Ein reiches Bild aus vielen Signalen
Um das Modell an realer Physiologie zu verankern, erstellten die Forschenden zunächst einen großen Datensatz von 1.000 erwachsenen Freiwilligen, darunter ausgebildete Sänger und Laien. Während sorgfältig gestalteter Stimmaufgaben – gehaltene Vokale und gleitende Tonhöhen – zeichneten sie mehrere Signale gleichzeitig auf: Hochgeschwindigkeits‑Ultraschallbilder von Geweben nahe den Stimmlippen, abdominalen Druck, der zeigt, wie stark die Probanden den Ton stützen, 3D‑Bewegungen von Brust und Bauch sowie hochauflösenden Audio. Alle diese Ströme wurden auf ein gemeinsames Zeitgitter synchronisiert, mit Abständen von nur einer halben Millisekunde. Raffinierte Plausibilitätsprüfungen stellten sicher, dass Ursache und Wirkung physikalisch sinnvoll waren – zum Beispiel mussten Atemdruck‑Impulse Änderungen der Lautstärke mit realistischer Verzögerung vorausgehen, und Schätzungen der Gewebesteifigkeit mussten physiologisch plausibel bleiben. Das Ergebnis ist ein synchronisierter, physikalisch konsistenter Film davon, wie Körper und Klang zusammen evolvieren.
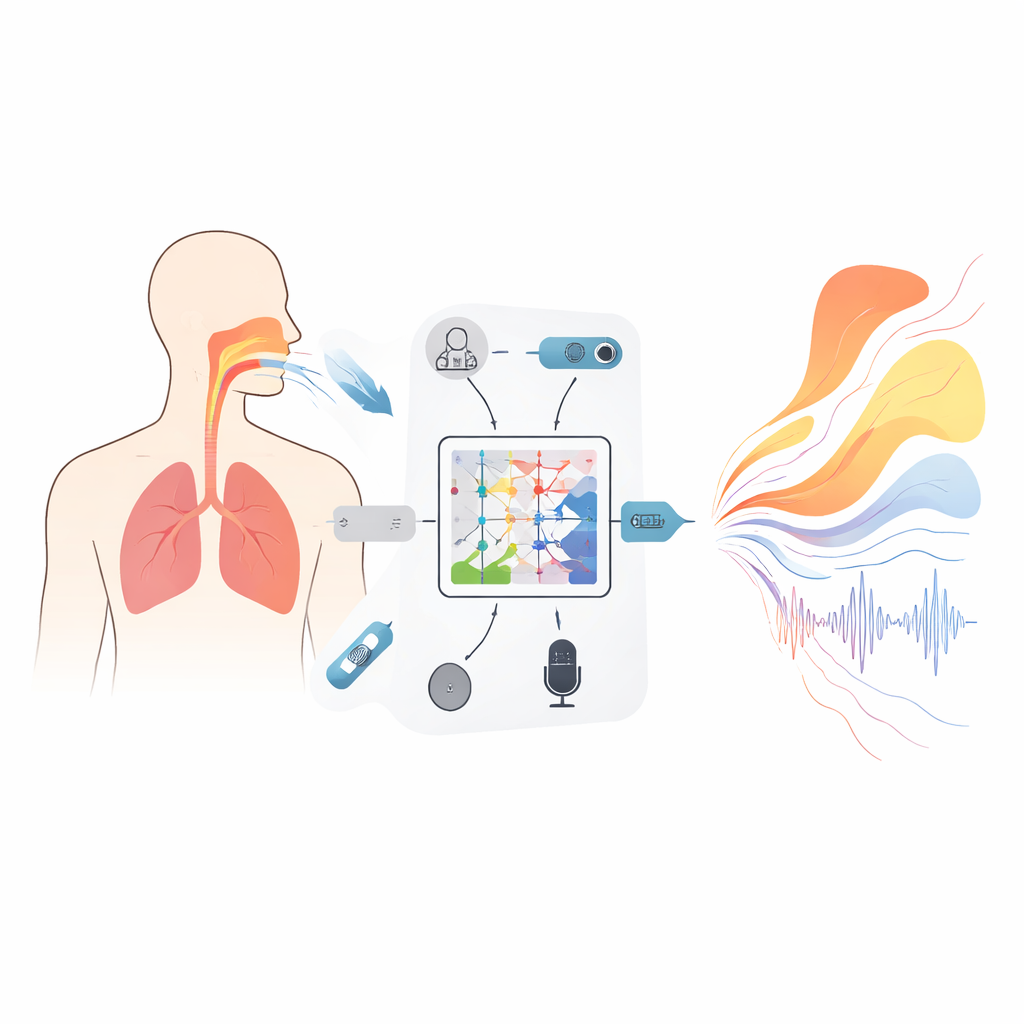
Ein neues Modell, das die Physik respektiert
Im Kern des Rahmens steht ein mathematisches Werkzeug namens Kolmogorov–Arnold‑neuraler (KAN) Operator, hier angepasst, um zu lernen, wie ganze Funktionen auf andere Funktionen abgebildet werden – etwa wie ein Audiospektrum über Frequenz auf eine Kurve abgebildet wird, die den Querschnittsverlauf des Vokaltrakts entlang seiner Länge beschreibt. Anstelle fester Aktivierungsfunktionen verwendet jede Einheit in diesem Netzwerk flexible Spline‑Kurven, die sich biegen können, um feine Details der Beziehung zwischen Klang und Form zu erfassen. Eine dreischichtige, verschachtelte Struktur verfeinert diese Abbildung schrittweise, um die Flächen an 19 Positionen vom Glottis bis zu den Lippen zu schätzen, während zusätzliche Terme in der Trainingszielgröße unmögliche Sprünge oder Verschlüsse entmutigen, die eine Phonation verhindern würden. Ein begleitendes rekurrentes Modul verfolgt, wie sich Druckdifferenzen über das Zwerchfell zeitlich entwickeln, mit eingebauten Beschränkungen, die aus grundlegender Mechanik abgeleitet sind, sodass die abgeleiteten Atmungsmuster sich nicht schneller ändern können, als es reale Muskeln leisten.
Genauer Blick auf Atmung und Klangfarbe
Über die Rekonstruktion von Anatomie und Luftstrom hinaus zoomt das System auch in die feine Struktur des Klangs selbst. Ein „Super‑Resolution“‑Vorhersagekopf nimmt die rekonstruierte Physiologie als Eingang und erzeugt ein extrem detailliertes Spektrum, das bis zu jedem Zehntel einer Millisekunde aktualisiert wird. Indem er Werkzeuge der fraktionalen Ordnung (fractional‑order calculus) einwebt und Verstöße gegen die Wellengleichung, die den Schall im Vokaltrakt beschreibt, bestraft, stellt dieser Kopf winzige Schwankungen in Tonhöhe und Lautstärke – bekannt als Jitter und Shimmer – wieder her, ohne unphysikalische Energie außerhalb des aufgezeichneten Frequenzbands zu erfinden. Im Bereich 1,2–2,4 kHz, der besonders wichtig für Timbre und Stimmidentität ist, reduzierte die Methode spektrale Fehler um mehr als die Hälfte gegenüber mehreren führenden neuronalen Operator‑Baselines. Sie lief außerdem schnell und genügsam genug auf einem Raspberry‑Pi‑ähnlichen Gerät, um Verarbeitungsverzögerungen unter etwa 20 Millisekunden zu halten.
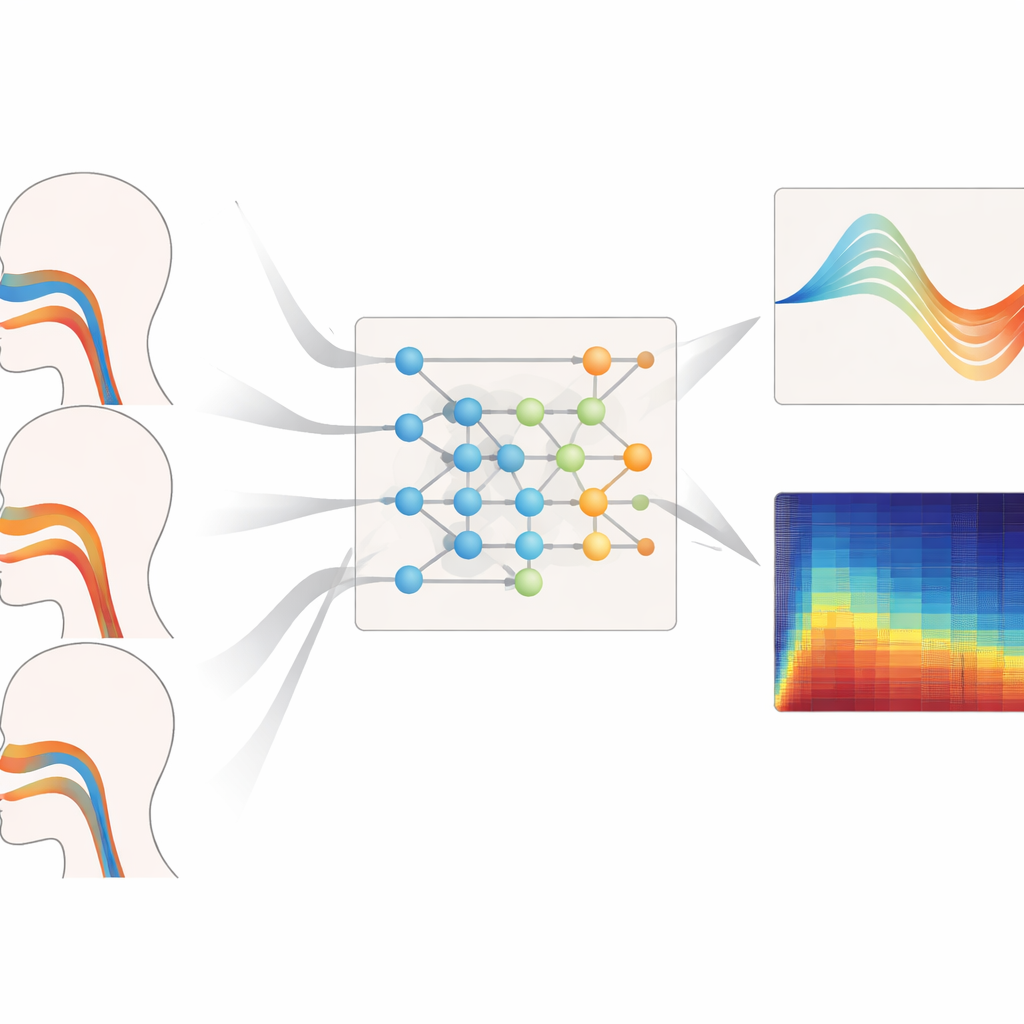
Wie gut es über Stimmen hinweg funktioniert
Die Autorinnen und Autoren testeten ihr Framework über verschiedene Tonlagen, Gesangsstile und unbekannte Stimmtypen hinweg. Bei der Aufgabe, die Vokaltrakt‑Geometrie für Bass-, Mittel‑ und hohe Stimmen zu rekonstruieren, erzeugte ihr Modell durchweg die geringsten Flächenfehler und die beste Übereinstimmung mit den gemessenen Formen, insbesondere bei hohen Tönen, wo sich der Vokaltrakt stärker verformen muss. Ebenso lieferte es die zuverlässigsten Schätzungen des Atemdrucks während Legato‑, Staccato‑ und Lautstärkewechsel‑Phrasen, mit kurzen Verzögerungen und glatten, muskelrealistischen Zeitverläufen. Selbst bei Sopranistinnen und Bässen, deren Daten während des Trainings vollständig zurückgehalten wurden, hielt das System geringe Geometrie‑ und Druckfehler aufrecht, was darauf hindeutet, dass es allgemeine Prinzipien der Stimmkontrolle gelernt hat, statt einzelne Sprecher zu memorieren.
Was das für Sängerinnen, Sänger und Lehrende bedeutet
Alltagssprachlich zeigt diese Arbeit, dass es möglich ist, daraus abzuleiten, wie eine Person ihren Rachen formt und ihren Atem steuert, allein aus dem von ihr erzeugten Klang – auf eine Weise, die sowohl genau als auch in grundlegender Physik verankert ist. Das Modell verwandelt die schwer fassbare Qualität des Timbres in interpretierbare Kurven: wie breit jeder Abschnitt des Vokaltrakts ist, wie der Druck im Abdomen steigt und fällt und wie subtile Pitch‑ und Lautstärke‑Wellen sich über die Zeit entfalten. Zwar untersucht die Studie noch nicht die Lernwirkung in realen Unterrichtsstunden, sie legt jedoch die technische Grundlage für künftige Werkzeuge, die Sängerinnen und Sängern in Echtzeit anatomiebewusstes Feedback geben könnten, zugeschnitten auf ihren eigenen Körper, und für Klinikerinnen und Kliniker, die nichtinvasive Einblicke darin benötigen, wie die Stimmen von Patientinnen und Patienten erzeugt werden.
Zitation: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Schlüsselwörter: Modellierung des Vokaltrakts, Atmungsdynamik, Analyse der Stimmfarbe, physik‑informierte neuronale Netzwerke, personalisierte Stimm‑Schulung