Clear Sky Science · nl
Interpreterbare inversie van het vocale kanaal en de ademhaling via physics-informed neural operators
Luisteren in de stem
Wanneer we een prachtige zangstem horen, denken we zelden aan de bewegende onderdelen die haar creëren: de kronkelende luchtweg van keel tot lippen, de longen die lucht aandrijven en de kleine spieren die elke noot vormen. Zangdocenten en artsen geven daar echter veel om. Deze studie introduceert een manier om uitsluitend via opgenomen geluid in het vocale kanaal en de longen te "kijken", en bouwt zo een brug tussen wat we van buiten horen en wat het lichaam van binnen doet — snel genoeg om bruikbaar te zijn voor realtime feedback en toekomstige slimme vocaletrainingshulpmiddelen.
Waarom de vorm van de keel ertoe doet
De kleur en karakteristiek van een stem — het timbre — ontstaan uit een delicate wisselwerking tussen de vorm van het vocale kanaal en de manier waarop lucht uit de longen stroomt. Kleine verschuivingen van de tong, het zachte gehemelte of de kaak, en subtiele veranderingen in ademdruk kunnen dezelfde noot helder, donker, gespannen of ontspannen laten klinken. Bestaande computermodellen kunnen stemmen imiteren, maar gedragen zich vaak als black boxes: ze tonen niet wat fysiek binnen in het lichaam gebeurt en falen vaak bij nieuwe sprekers met een andere anatomie. Dit werk pakt die kloof aan door zich niet alleen te richten op het kopiëren van geluid, maar op het terugwinnen van de onderliggende geometrie en ademhalingspatronen die het geluid produceren.
Een rijk beeld opbouwen uit veel signalen
Om het model aan echte fysiologie te verankeren, maakten de onderzoekers eerst een grote dataset van 1.000 volwassen vrijwilligers, waaronder zowel getrainde zangers als niet‑professionals. Tijdens zorgvuldig ontworpen vocale taken — aangehouden klinkers en glijdende toonhoogtes — registreerden zij meerdere signalen gelijktijdig: hogesnelheids‑echobeelden van weefsels nabij de stemplooien, abdominale druk die laat zien hoe sterk de proefpersonen het geluid ondersteunden, 3D‑beweging van borst en buik, en hoogkwalitatieve audio. Al deze stromen werden op een gemeenschappelijk tijdgrid uitgelijnd met stappen van slechts een halve milliseconde. Geavanceerde controles zorgden ervoor dat oorzaak en gevolg fysiek logisch waren — bijvoorbeeld dat ademdrukpulsen veranderingen in luidheid met een realistische vertraging vooraf moesten gaan, en dat schattingen van weefselstijfheid fysiologisch plausibel moesten blijven. Het resultaat is een gesynchroniseerde, fysisch consistente film van hoe lichaam en geluid samen evolueren.
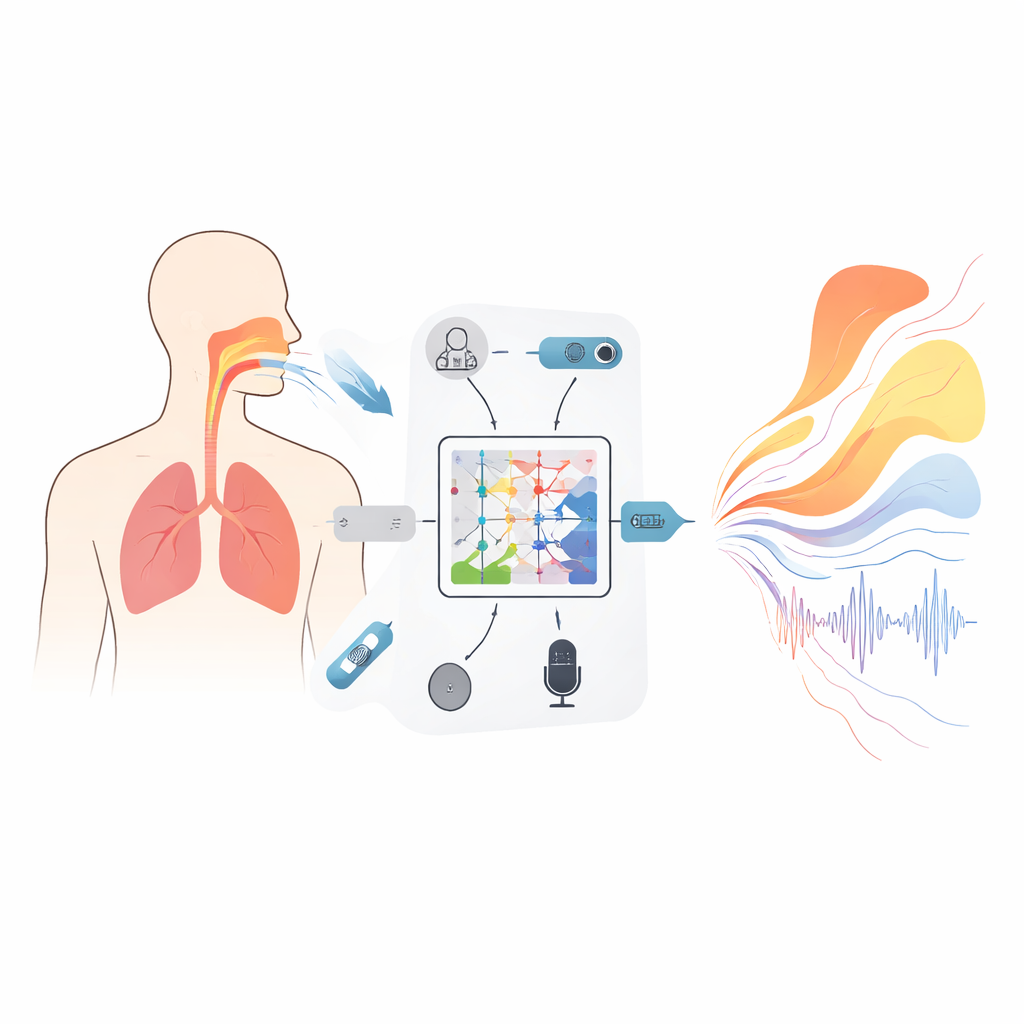
Een nieuw soort model dat de natuurwetten respecteert
Centraal in het framework staat een wiskundig instrument dat een Kolmogorov–Arnold neural (KAN) operator wordt genoemd, hier aangepast om te leren hoe volledige functies naar andere functies worden afgebeeld — bijvoorbeeld hoe een audiospectrum over frequentie wordt omgezet in een curve die de doorsnede‑oppervlakte van het vocale kanaal langs de lengte beschrijft. In plaats van vaste activatiefuncties gebruikt elke eenheid in dit netwerk flexibele spline‑curves die kunnen buigen om fijne details van de relatie tussen geluid en vorm vast te leggen. Een driedelige, genestelde structuur verfijnt deze afspiegeling stapsgewijs om de oppervlakten op 19 locaties van de glottis tot de lippen te schatten, terwijl extra termen in het trainingsdoel onmogelijke sprongen of sluitingen ontmoedigen die fonatie zouden verhinderen. Een begeleidende recurrente module volgt hoe drukverschillen over het diafragma in de tijd evolueren, met ingebouwde beperkingen afgeleid van basale mechanica zodat de afgeleide ademhalingspatronen niet sneller veranderen dan echte spieren kunnen bijbenen.
Inzoomen op adem en timbre‑detail
Naast het reconstrueren van anatomie en luchtstroming zoomt het systeem ook in op het fijne detail van het geluid zelf. Een "super‑resolutie" predictiekop neemt de teruggewonnen fysiologie als invoer en genereert een uiterst gedetailleerd spectrum, met updates zo vaak als elke tiende van een milliseconde. Door instrumenten uit de fractie‑orde calculus te verweven en door overtredingen van de golfvergelijking die het geluid in het vocale kanaal beheerst te bestraffen, herstelt deze kop kleine fluctuaties in toonhoogte en luidheid — bekend als jitter en shimmer — zonder niet‑fysieke energie buiten de opgenomen frequentieband te verzinnen. In het bereik van 1,2–2,4 kHz, dat bijzonder belangrijk is voor timbre en stemidentiteit, halveerde de methode de spectrale fouten vergeleken met verschillende toonaangevende neurale operator‑baselines. Het draaide ook snel en licht genoeg op een Raspberry Pi‑klasse apparaat om verwerkingsvertragingen onder ongeveer 20 milliseconden te houden.
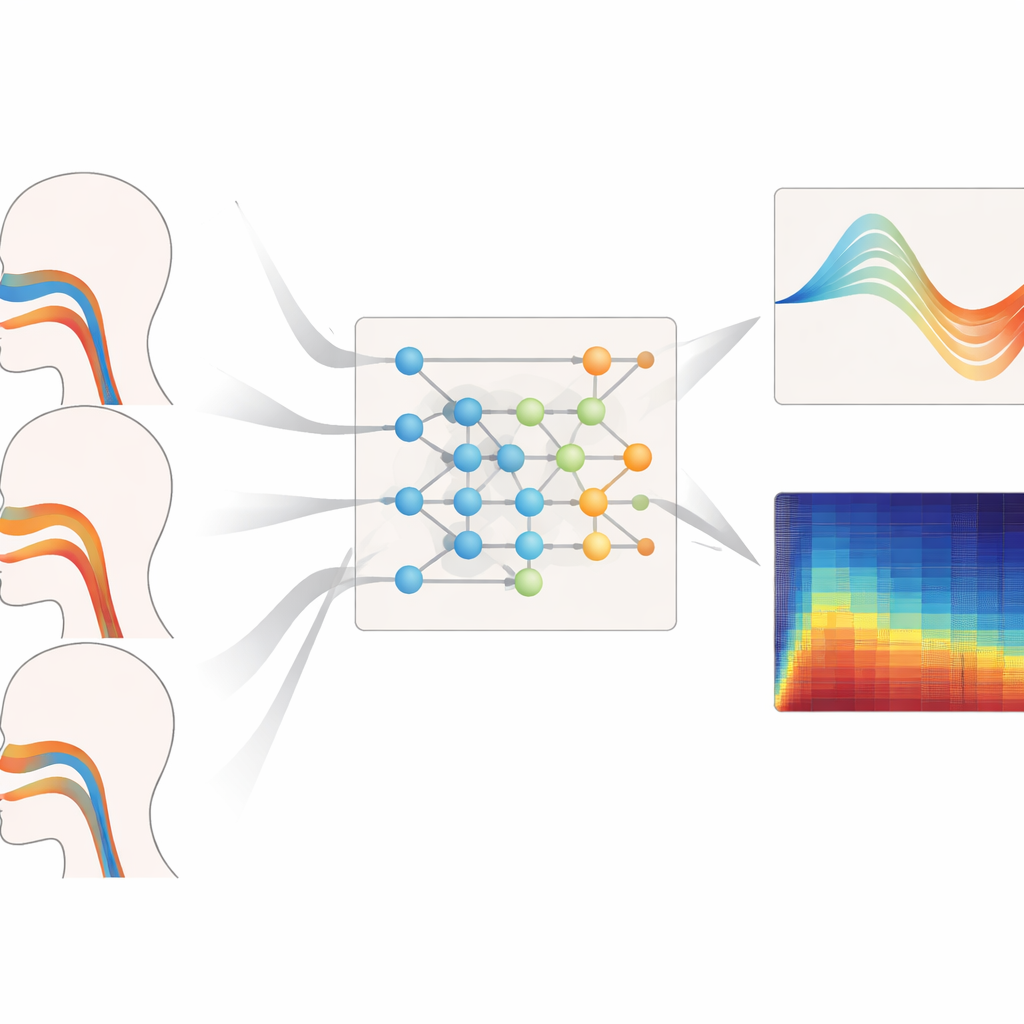
Hoe goed het werkt over verschillende stemmen
De auteurs voerden extreme tests uit met hun framework over uiteenlopende toonhoogtebereiken, zangstijlen en ongeziene stemtypes. Bij de taak om de geometrie van het vocale kanaal te reconstrueren voor lage bassen, middentonende en hoge stemmen, produceerde hun model consequent de kleinste oppervlakteschatterrors en de beste overeenkomst met de grondwaarheidsvormen, vooral bij hoge tonen waar het vocale kanaal dramatischer moet vervormen. Het leverde ook de meest betrouwbare schattingen van ademdruk tijdens legato, staccato en fraseringen met veranderende luidheid, met korte vertragingen en vloeiende, spierrealistische tijdsverlopen. Zelfs bij evaluatie op sopranen en bassen waarvan de data volledig waren weggelaten tijdens training, behield het systeem lage geometrie‑ en drukfouten, wat suggereert dat het algemene principes van vocale controle heeft geleerd in plaats van individuele sprekers te memoriseren.
Wat dit betekent voor zangers en docenten
In gewone bewoordingen toont dit werk dat het mogelijk is af te leiden hoe iemand zijn keel vormt en zijn adem beheert rechtstreeks uit het geluid dat hij produceert, op een manier die zowel nauwkeurig als geworteld in fundamentele natuurkunde is. Het model zet de vluchtige kwaliteit van timbre om in interpreteerbare krommen: hoe breed elk deel van het vocale kanaal is, hoe de druk in de buik stijgt en daalt, en hoe subtiele toonhoogte‑ en luidheidsrimpels zich in de tijd ontvouwen. Hoewel de studie nog geen leeruitkomsten in echte lessen test, legt zij de technische basis voor toekomstige hulpmiddelen die zangers realtime, anatomie‑bewuste feedback op maat van hun eigen lichaam kunnen geven, en voor clinici die niet‑invasief inzicht nodig hebben in hoe de stemmen van patiënten worden geproduceerd.
Bronvermelding: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Trefwoorden: modellering van het vocale kanaal, ademhalingsdynamica, analyse van vocale timbre, physics-informed neurale netwerken, gepersonaliseerde vocale training