Clear Sky Science · tr
Fizik tarafından bilgilendirilen sinirsel operatörlerle yorumlanabilir ses yolu ve solunum tersine dönüşümü
Sesin İçini Dinlemek
Güzel bir şan sesini duyduğumuzda, onu oluşturan hareketli parçalar üzerine nadiren düşünürüz: boğazdan dudaklara uzanan dönen hava yolu, havayı iten akciğerler ve her notayı şekillendiren küçük kaslar. Ancak ses eğitmenleri ve doktorlar bu gizli hareketlerle yakından ilgilenir. Bu çalışma, yalnızca kaydedilmiş sesi kullanarak ses yolu ve akciğerlerin içine “bakmanın” bir yolunu tanıtıyor; dışarıda duyduklarımızla vücudun içinde olanlar arasında bir köprü kuruyor—gerçek zamanlı geri bildirim ve geleceğin akıllı vokal eğitim araçları için yeterince hızlı olacak şekilde.
Boğazın Şeklinin Neden Önemi Var
Bir sesin rengi ve karakteri—tınısı—ses yolunun şekli ile akciğerlerden geçen havanın etkileşiminin hassas bir dansından kaynaklanır. Dilin, yumuşak damağın veya çenenin küçük kaymaları ve nefes basıncındaki incelikli değişimler aynı notanın parlak, koyu, gergin veya rahat çıkmasına neden olabilir. Mevcut bilgisayar modelleri sesleri taklit edebilir, ancak genellikle kara kutu gibi davranırlar: vücudun içinde fiziksel olarak neler olduğunu göstermezler ve farklı anatomilere sahip yeni konuşmacılara uygulandığında sıkça başarısız olurlar. Bu çalışma, sadece sesi kopyalamaya odaklanmak yerine, onu üreten temel geometrinin ve solunum kalıplarının geri kazanılmasına odaklanarak bu boşluğu dolduruyor.
Birçok Sinyalden Zengin Bir Resim Oluşturmak
Modeli gerçek fizyolojiye dayandırmak için araştırmacılar önce eğitimli şarkıcılar ve amatörler de dahil 1.000 yetişkin gönüllüden oluşan büyük bir veri seti oluşturdular. Sürdürülmüş ünlüler ve kaydırmalı perdeler gibi özenle tasarlanmış vokal görevler sırasında aynı anda birkaç sinyal kaydedildi: ses tellerine yakın dokuların yüksek hızlı ultrason görüntüleri, deneklerin sesi ne kadar güçlü desteklediklerini gösteren abdominal basınç, göğüs ve karın hareketinin 3B hareket verisi ve yüksek sadakatli ses kaydı. Bu akışların tümü yalnızca yarım milisaniye aralıklarla ortak bir zaman ızgarasında hizalandı. Neden‑sonuç ilişkilerinin fiziksel anlam taşıdığını garanti eden sofistike kontroller uygulandı—örneğin nefes basıncı darbeleri, yüksekliğin değişimlerinden gerçekçi bir gecikme ile önce gelmeli ve doku sertliği tahminleri fizyolojik olarak makul kalmalıydı. Sonuç, vücut ve sesin birlikte nasıl evrildiğinin senkronize, fiziksel olarak tutarlı bir filmi oldu.
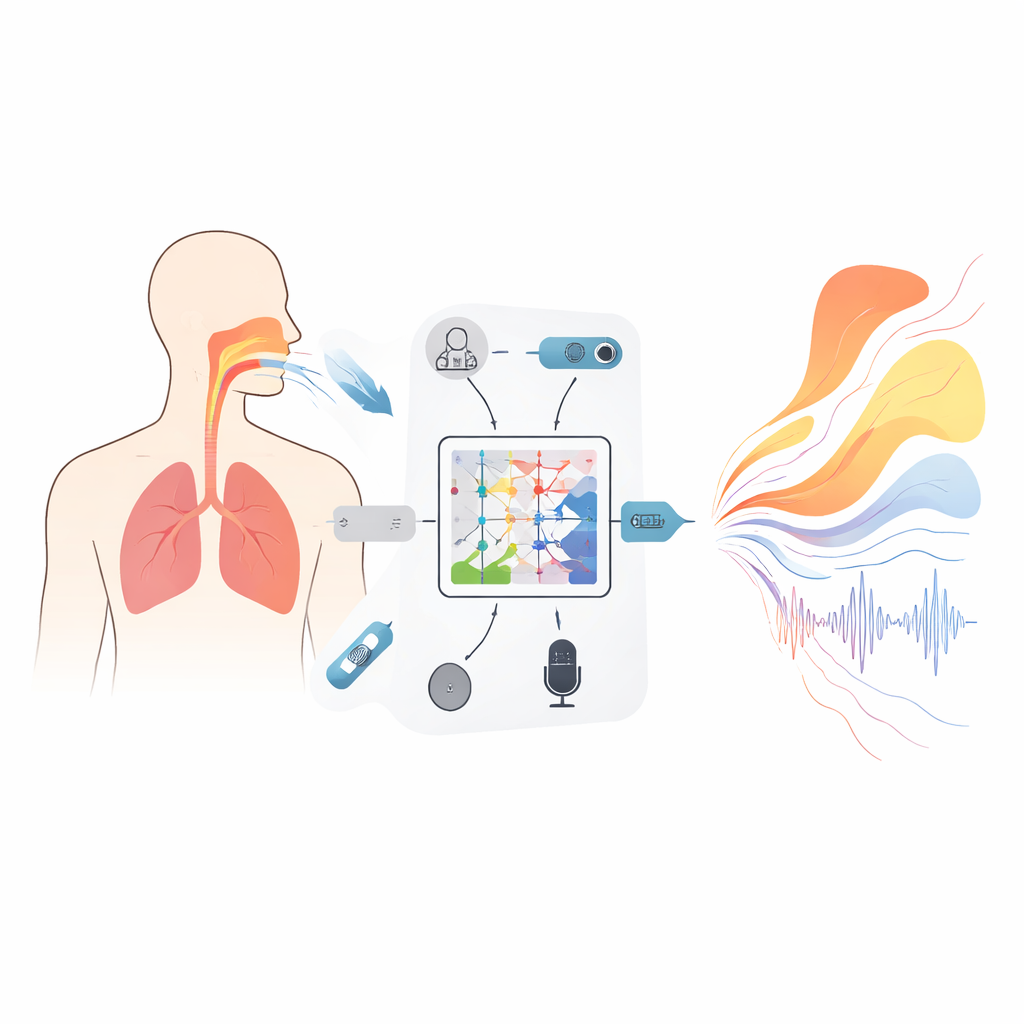
Fiziğe Saygı Gösteren Yeni Bir Model Türü
Çerçeve merkezinde, burada tüm fonksiyonların diğer fonksiyonlara nasıl haritalandığını öğrenmek üzere uyarlanmış Kolmogorov–Arnold sinirsel (KAN) operatörü adlı matematiksel bir araç bulunur—örneğin bir frekans üzerindeki ses spektrumunun ses yolunun uzunluğu boyunca kesit alanını tanımlayan bir eğriye nasıl dönüştüğü gibi. Sabit aktivasyon fonksiyonları yerine, bu ağdaki her bir birim, ses ile şekil arasındaki ilişkinin ince ayrıntılarını yakalamak için bükülebilen esnek spline eğrileri kullanır. Üç katmanlı, iç içe geçmiş yapı bu eşlemeyi kademeli olarak iyileştirerek glottisten dudaklara kadar 19 konumun alanlarını tahmin ederken, eğitim hedefindeki ek terimler fonasyonun mümkün olmasını engelleyecek imkansız sıçramaları veya kapanışları caydırır. Eşlik eden tekrarlayan bir modül diyafram üzerindeki basınç farklarının zaman içinde nasıl evrildiğini izler; içinde temel mekaniğe dayalı kısıtlar gömülü olduğundan çıkarılan solunum kalıpları gerçek kasların yönetebileceğinden daha hızlı değişmez.
Nefes ve Tını Ayrıntısına Yakından Bakmak
Anatomiyi ve hava akışını yeniden oluşturmanın ötesinde, sistem sesin kendisinin ince ayrıntılarına da odaklanır. "Süper çözünürlük" tahmin başlığı, kurtarılan fizyolojiyi girdi olarak alır ve her onda bir milisaniyeye kadar sık güncellenerek son derece ayrıntılı bir spektrum üretir. Kesirli dereceli kalkülüs araçlarını örerek ve ses yolunda sesi yöneten dalga denklemi ihlallerini cezalandırarak, bu başlık perde ve şiddetteki çok küçük dalgalanmaları—jitter ve shimmer olarak bilinen—kayıtlı frekans bandının dışında fiziksel olmayan enerji uydurmadan geri getirir. Tını ve ses kimliği için özellikle önemli olan 1.2–2.4 kHz aralığında, yöntem birkaç önde gelen sinirsel operatör kıyas tabanına kıyasla spektral hataları yarıdan fazla azalttı. Ayrıca Raspberry Pi sınıfı bir cihazda yeterince hızlı ve hafif çalışarak işlem gecikmelerini yaklaşık 20 milisaniyenin altında tuttu.
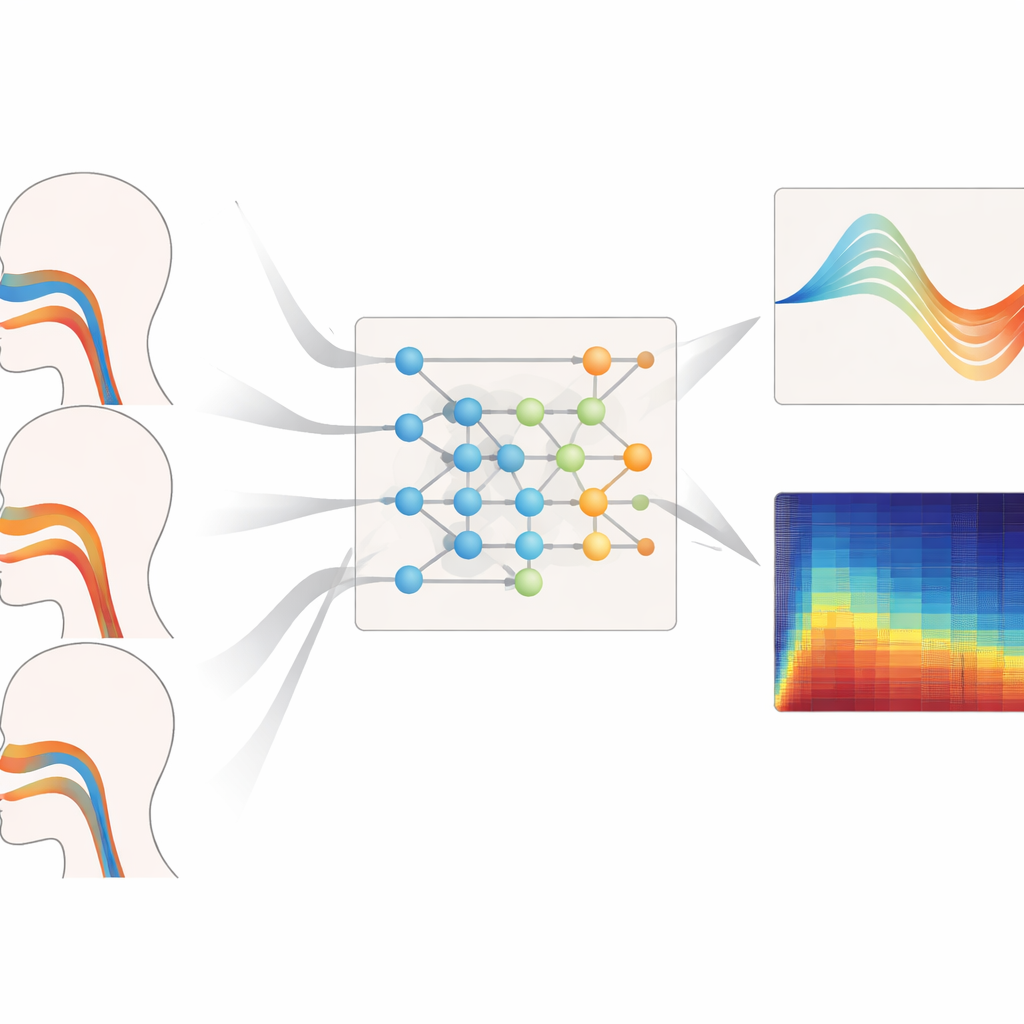
Farklı Seslerde Ne Kadar İyi İşliyor
Yazarlar çerçevelerini farklı perde aralıklarına, şarkı stillerine ve görülmemiş ses tiplerine karşı zorladı. Bas, orta ve yüksek perdeli sesler için ses yolu geometrisini yeniden oluşturma görevi verildiğinde modelleri tutarlı şekilde en küçük alan hatalarını ve özellikle ses yolunun daha dramatik şekilde deforme olması gereken yüksek perdelerde gerçek şekillerle en güçlü uyuşmayı üretti. Aynı şekilde legato, staccato ve dinamik değişen sesli pasajlarda solunum basıncının en güvenilir tahminlerini sundu; kısa gecikmeler ve kas‑gerçekçi düz, zaman seyirleri sağladı. Verileri eğitim sırasında tamamen hariç tutulmuş sopranolar ve baslar üzerinde bile değerlendirildiğinde, sistem geometri ve basınç hatalarını düşük tuttu; bu da modelin bireysel konuşmacıları ezberlemek yerine vokal kontrolün genel ilkelerini öğrendiğini gösteriyor.
Bu Şarkıcılar ve Eğitmenler İçin Ne Anlama Geliyor
Günlük ifadeyle, bu çalışma bir kişinin boğazını nasıl şekillendirdiğini ve nefesini nasıl yönettiğini ürettikleri sesten doğrudan, hem doğru hem de temel fizikçe temellendirilmiş bir şekilde çıkarabilmenin mümkün olduğunu gösteriyor. Model tını gibi zor tanımlanabilen niteliği yorumlanabilir eğrilere dönüştürüyor: ses yolunun her bölümünün ne kadar geniş olduğu, karın içi basıncın nasıl yükselip düştüğü ve ince perde ile şiddet dalgalanmalarının zaman içinde nasıl açığa çıktığı. Çalışma henüz gerçek derslerde öğrenme çıktılarını test etmese de, kendi vücuduna göre uyarlanmış, anatomiyi gözeten gerçek zamanlı geri bildirim verebilecek gelecekteki araçlar ile hastaların seslerinin nasıl üretildiğine dair invazif olmayan içgörüye ihtiyaç duyan klinisyenler için teknik temeli atıyor.
Atıf: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Anahtar kelimeler: ses yolu modellenmesi, solunum dinamikleri, sesin tını analizi, fizikten beslenen sinir ağları, kişiselleştirilmiş vokal eğitim