Clear Sky Science · sv
Tydliggörbar inversion av talrör och respiration via fysik‑informerade neurala operatorer
Lyssna inuti rösten
När vi hör en vacker sångröst tänker vi sällan på de rörliga delar som skapar den: den slingrande luftvägen från svalg till läppar, lungorna som driver luften och de små musklerna som formar varje ton. Sångpedagoger och läkare bryr sig däremot djupt om dessa dolda rörelser. Denna studie presenterar ett sätt att "titta in" i talröret och lungorna med enbart inspelat ljud, och bygger en bro mellan vad vi hör utifrån och vad kroppen gör inuti — tillräckligt snabbt för att vara användbart för realtidsfeedback och framtida smarta verktyg för röstträning.
Varför formens betydelse i halsen spelar roll
Röstens färg och karaktär — dess klang — uppstår genom ett känsligt samspel mellan talrörets form och hur luften strömmar från lungorna. Små förskjutningar av tungan, den mjuka gommen eller käken, och subtila förändringar i lufttrycket kan få samma ton att låta ljus, mörk, spänd eller avslappnad. Befintliga datoriserade modeller kan efterlikna röster, men de beter sig oftast som svarta lådor: de avslöjar inte vad som händer fysiskt inuti kroppen och misslyckas ofta när de tillämpas på nya talare med annan anatomi. Detta arbete tar itu med den luckan genom att fokusera inte bara på att efterlikna ljudet utan på att återvinna den underliggande geometrin och andningsmönstren som frambringar det.
Bygga en rik bild från många signaler
För att förankra modellen i verklig fysiologi skapade forskarna först en stor datamängd från 1 000 vuxna frivilliga, inklusive både utbildade sångare och icke‑professionella. Under noggrant utformade vokala uppgifter — hållna vokaler och glidande tonhöjder — spelade de in flera signaler samtidigt: högfrekventa ultraljudsbilder av vävnader nära stämbanden, buktryck som visar hur starkt försökspersonerna stödde ljudet, 3D‑rörelser i bröst och buk samt högkvalitativt ljud. Alla dessa strömmar synkroniserades på ett gemensamt tidsraster med endast en halv millisekunds mellanrum. Sofistikerade kontroller säkerställde att orsak och verkan gjorde fysisk mening — till exempel måste lufttryckspulser föregå förändringar i ljudstyrka med en realistisk fördröjning, och uppskattningar av vävnadsstelhet måste förbli fysiologiskt rimliga. Resultatet är en synkroniserad, fysikaliskt konsekvent film av hur kroppen och ljudet utvecklas tillsammans.
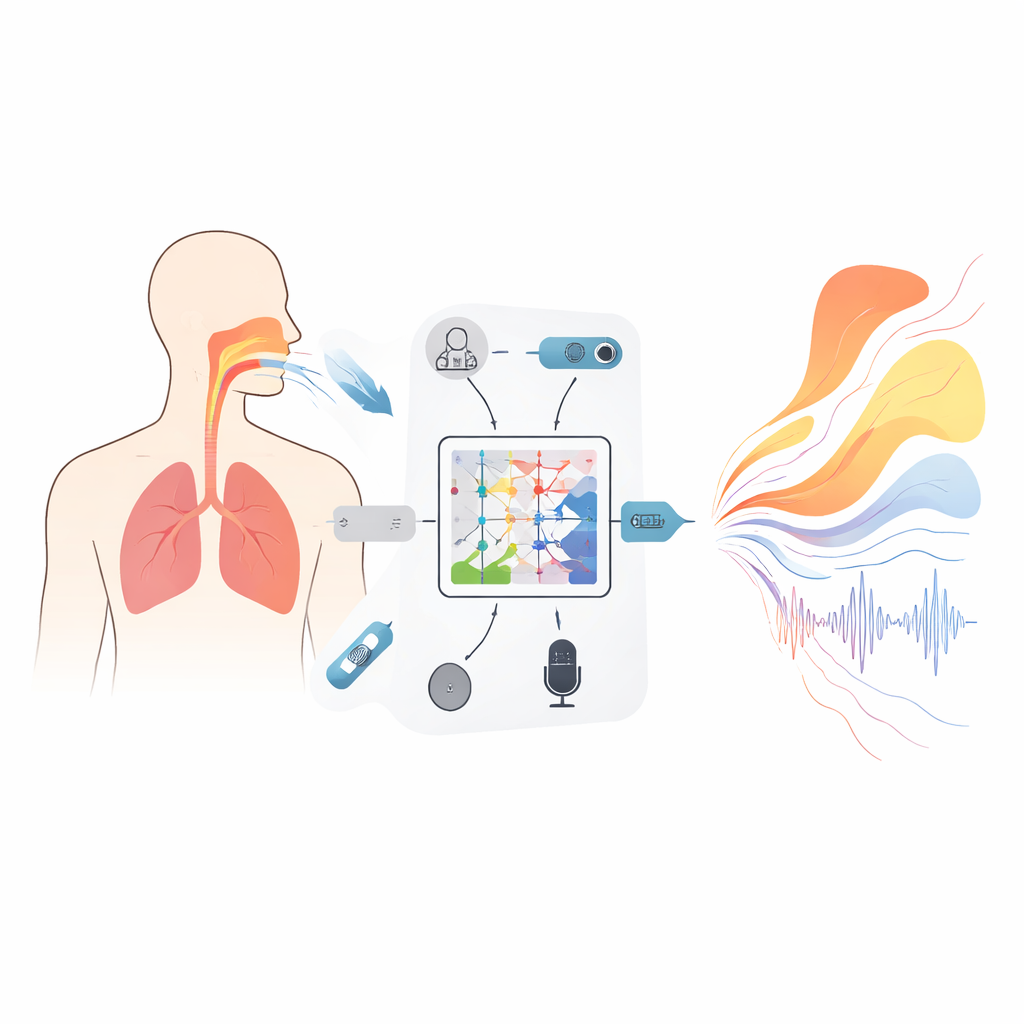
En ny slags modell som respekterar fysiken
I kärnan av ramverket finns ett matematiskt verktyg kallat en Kolmogorov–Arnold‑neural (KAN) operator, här anpassad för att lära sig hur hela funktioner avbildas till andra funktioner — till exempel hur ett ljudspektrum över frekvens avbildas till en kurva som beskriver tvärsnittsarean i talröret längs dess längd. Istället för fasta aktiveringsfunktioner använder varje enhet i detta nätverk flexibla spline‑kurvor som kan böja sig för att fånga finare detaljer i sambandet mellan ljud och form. En trelagrad, nästlad struktur förfinar successivt denna avbildning för att uppskatta areor på 19 platser från glottis till läpparna, medan extra termer i träningsmålfunktionen avskräcker omöjliga hopp eller slutsituationer som skulle omöjliggöra fonation. En medföljande rekurrent modul följer hur tryckskillnader över diafragman utvecklas i tiden, med inbyggda begränsningar härledda från grundläggande mekanik så att de härledda andningsmönstren inte förändras snabbare än vad verkliga muskler kan åstadkomma.
Zooma in på andningens och klangens detaljer
Bortom att rekonstruera anatomi och luftflöde förfinar systemet också ljudets finstruktur. Ett "superupplösnings"‑prediktionhuvud tar den återvunna fysiologin som indata och genererar ett extremt detaljerat spektrum, uppdaterat så ofta som var tionde millisekund. Genom att väva in verktyg från fraktionell‑ordningens kalkyl och genom att straffa brott mot vågekvationen som styr ljud i talröret återställer detta huvud små svängningar i tonhöjd och ljudstyrka — kända som jitter och shimmer — utan att uppfinna ofysisk energi utanför det inspelade frekvensbandet. Över 1,2–2,4 kHz‑intervallet, som är särskilt viktigt för klang och röstidentitet, minskade metoden spektrala fel med mer än hälften jämfört med flera ledande neurala operatorbaser. Den körde också tillräckligt snabbt och lätt på en Raspberry Pi‑klassad enhet för att hålla bearbetningsfördröjningar under ungefär 20 millisekunder.
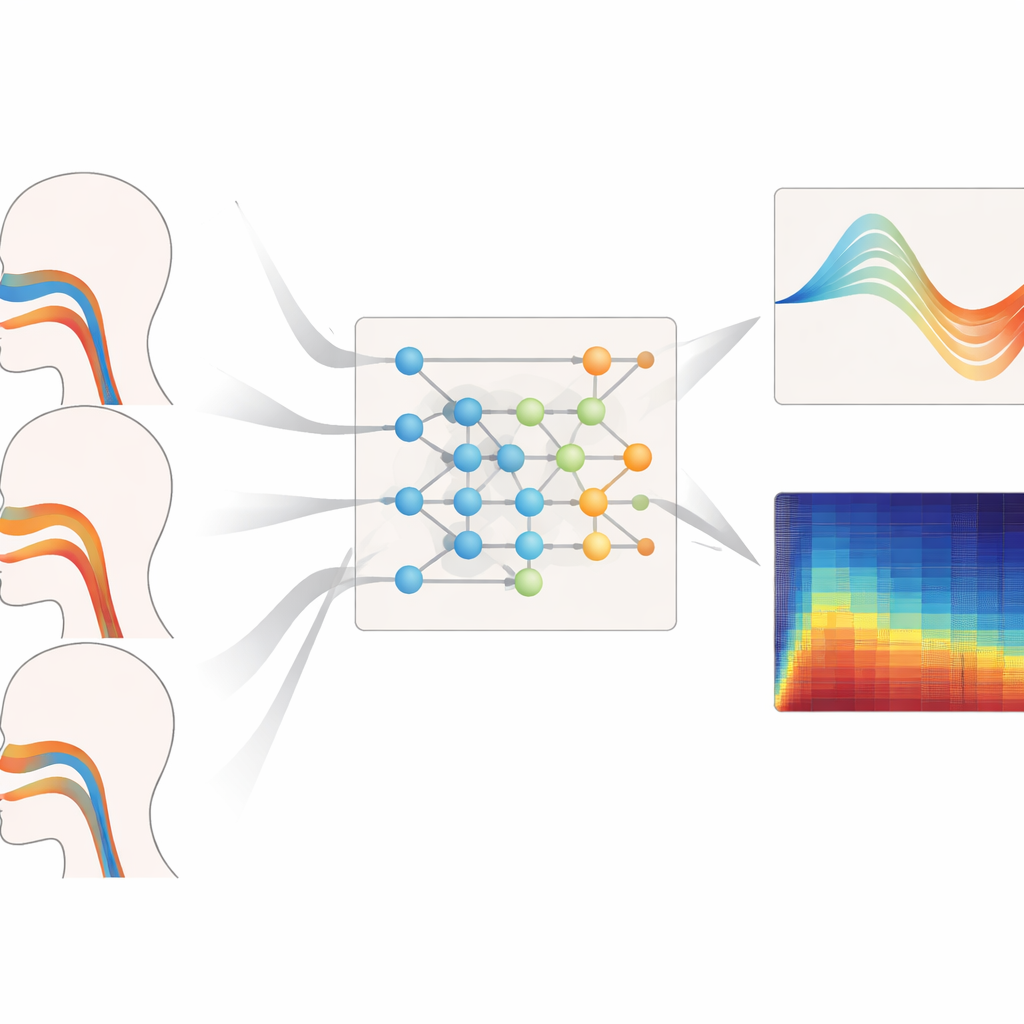
Hur väl det fungerar över olika röster
Författarna utsatte sitt ramverk för stressprov över olika tonregister, sångstilar och icke‑sedda rösttyper. När det fick i uppgift att rekonstruera talrörsgeometrin för bas-, mellan‑ och högstämda röster producerade deras modell konsekvent de minsta areafelen och den starkaste överensstämmelsen med sanningens former, särskilt vid höga toner där talröret måste deformeras mer dramatiskt. Den erbjöd likaledes de mest tillförlitliga uppskattningarna av andningstryck under legato, staccato och fraser med varierande styrka, med korta fördröjningar och mjuka, muskelrealistiska tidsförlopp. Även när den utvärderades på sopraner och basar vars data helt undanhållits under träning bibehöll systemet låga geometriska och tryckrelaterade fel, vilket tyder på att det lärt sig allmänna principer för röstkontroll snarare än att memorerat enskilda talare.
Vad detta betyder för sångare och lärare
I vardagliga termer visar detta arbete att det är möjligt att härleda hur en person formar sin hals och hanterar sin andning direkt från det ljud de producerar, på ett sätt som både är korrekt och förankrat i grundläggande fysik. Modellen omvandlar det svårfångade begreppet klang till tolkbara kurvor: hur brett varje del av talröret är, hur trycket i buken stiger och faller, och hur subtila ton‑ och ljudstyrkesvängningar utvecklas över tid. Även om studien ännu inte testar inlärningsresultat i faktiska lektioner, lägger den den tekniska grunden för framtida verktyg som skulle kunna ge sångare realtids‑, anatomi‑medveten feedback anpassad till deras egna kroppar, och för kliniker som behöver icke‑invasiv insikt i hur patienters röster produceras.
Citering: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Nyckelord: modellering av talrör, respiratorisk dynamik, analys av röstklang, fysik‑informerade neurala nätverk, personlig röstträning