Clear Sky Science · en
Interpretable vocal tract and respiratory inversion via physics-informed neural operators
Listening Inside the Voice
When we hear a beautiful singing voice, we rarely think about the moving parts that create it: the twisting airway from throat to lips, the lungs pushing air, and the tiny muscles that shape every note. Voice teachers and doctors, however, care deeply about these hidden motions. This study introduces a way to “look inside” the vocal tract and lungs using only recorded sound, building a bridge between what we hear outside and what the body is doing inside—fast enough to be useful for real‑time feedback and future smart vocal‑training tools.
Why the Shape of the Throat Matters
The color and character of a voice—its timbre—come from a delicate dance between the shape of the vocal tract and the way air flows from the lungs. Small shifts of the tongue, soft palate, or jaw, and subtle changes in breath pressure, can make the same note sound bright, dark, tense, or relaxed. Existing computer models can imitate voices, but they usually behave like black boxes: they do not reveal what is happening physically inside the body, and they often fail when applied to new speakers with different anatomy. This work tackles that gap by focusing not just on copying the sound, but on recovering the underlying geometry and breathing patterns that produce it.
Building a Rich Picture from Many Signals
To ground the model in real physiology, the researchers first created a large dataset from 1,000 adult volunteers, including both trained singers and non‑professionals. During carefully designed vocal tasks—sustained vowels and sliding pitches—they recorded several signals at once: high‑speed ultrasound images of tissues near the vocal cords, abdominal pressure showing how strongly the subjects were supporting the sound, 3D motion of the chest and belly, and high‑fidelity audio. All of these streams were aligned on a common time grid only half a millisecond apart. Sophisticated checks ensured that cause and effect made physical sense—for example, breath‑pressure pulses had to lead changes in loudness by a realistic delay, and tissue stiffness estimates had to remain physiologically plausible. The result is a synchronized, physically consistent movie of how the body and sound evolve together.
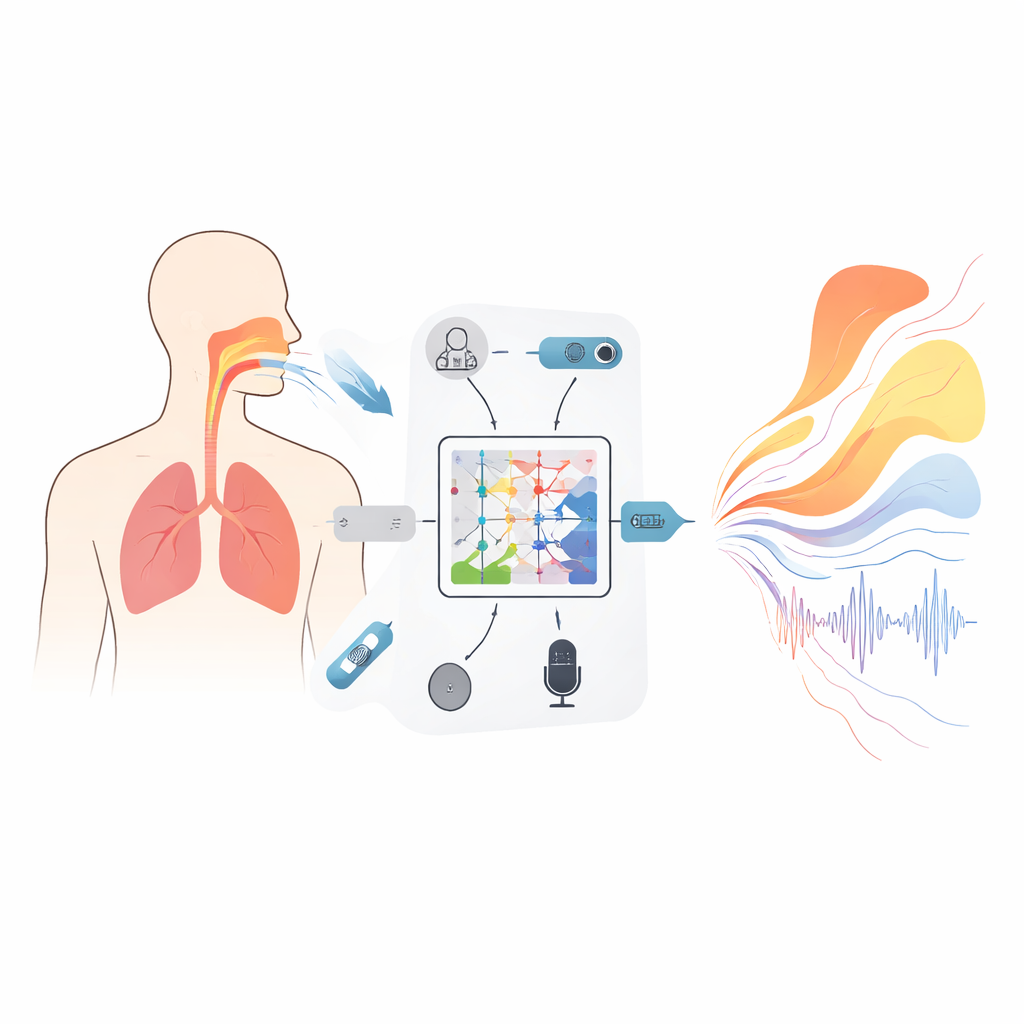
A New Kind of Model That Respects Physics
At the core of the framework is a mathematical tool called a Kolmogorov–Arnold neural (KAN) operator, adapted here to learn how whole functions map to other functions—for instance, how an audio spectrum over frequency maps to a curve describing the cross‑sectional area of the vocal tract along its length. Instead of fixed activation functions, each unit in this network uses flexible spline curves that can bend to capture fine details of the relationship between sound and shape. A three‑layer, nested structure progressively refines this mapping to estimate the areas of 19 locations from the glottis to the lips, while extra terms in the training objective discourage impossible jumps or closures that would not allow phonation. A companion recurrent module follows how pressure differences across the diaphragm evolve in time, with built‑in constraints derived from basic mechanics so the inferred breathing patterns change no faster than real muscles can manage.
Zooming In on Breath and Timbre Detail
Beyond reconstructing anatomy and airflow, the system also zooms in on the fine grain of the sound itself. A “super‑resolution” prediction head takes the recovered physiology as input and generates an extremely detailed spectrum, updating as often as every tenth of a millisecond. By weaving in tools from fractional‑order calculus and by penalizing violations of the wave equation that governs sound in the vocal tract, this head restores tiny fluctuations in pitch and loudness—known as jitter and shimmer—without inventing unphysical energy outside the recorded frequency band. Across the 1.2–2.4 kHz range, which is especially important for timbre and voice identity, the method cut spectral errors by more than half compared with several leading neural operator baselines. It also ran fast and light enough on a Raspberry Pi‑class device to keep processing delays under about 20 milliseconds.
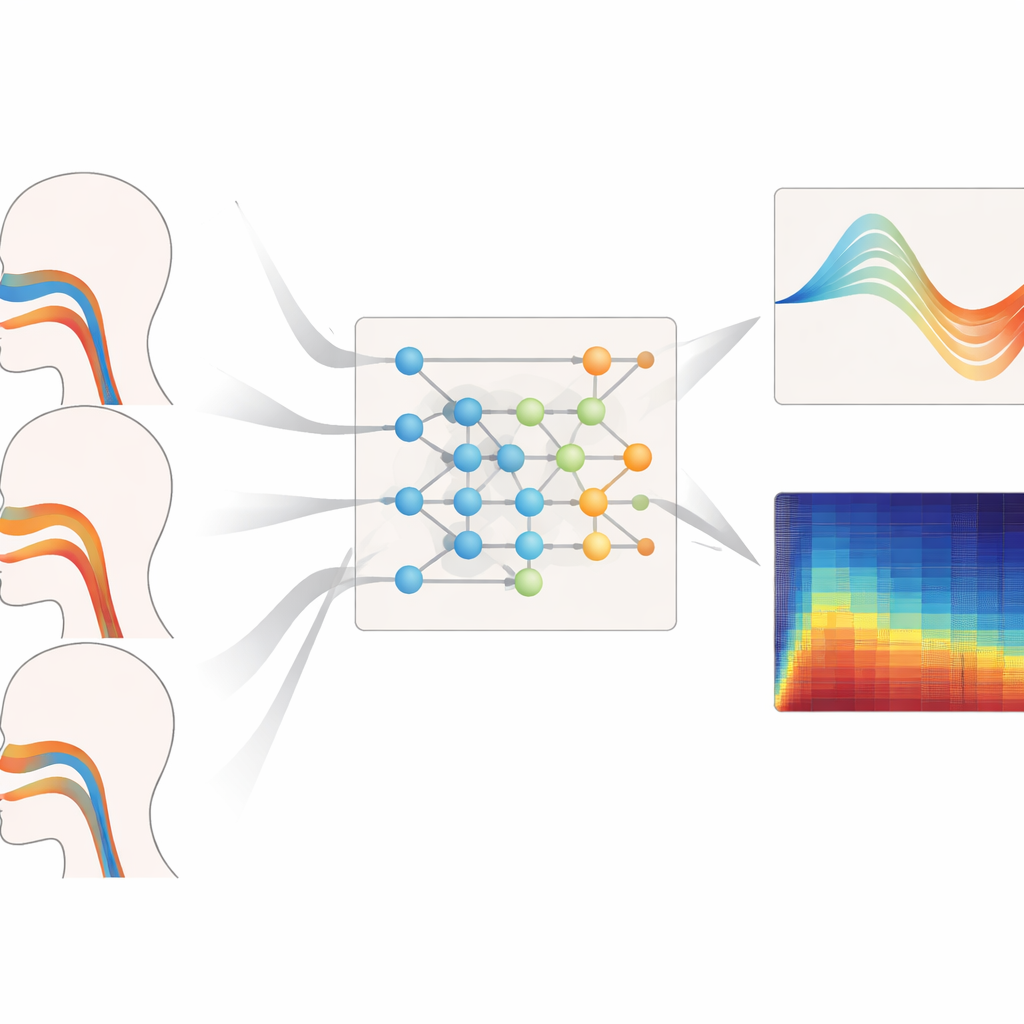
How Well It Works Across Voices
The authors stress‑tested their framework across different pitch ranges, singing styles, and unseen voice types. When tasked with reconstructing the vocal tract geometry for bass, mid‑range, and high‑pitched voices, their model consistently produced the smallest area errors and the strongest match to ground‑truth shapes, especially at high pitches where the vocal tract must deform more dramatically. It likewise offered the most reliable estimates of breathing pressure during legato, staccato, and changing‑loudness phrases, with short delays and smooth, muscle‑realistic time courses. Even when evaluated on sopranos and basses whose data were completely withheld during training, the system maintained low geometry and pressure errors, suggesting it had learned general principles of vocal control rather than memorizing individual speakers.
What This Means for Singers and Teachers
In everyday terms, this work shows that it is possible to infer how a person is shaping their throat and managing their breath directly from the sound they produce, in a way that is both accurate and grounded in basic physics. The model transforms the elusive quality of timbre into interpretable curves: how wide each part of the vocal tract is, how pressure in the abdomen rises and falls, and how subtle pitch and loudness ripples unfold over time. While the study does not yet test learning outcomes in actual lessons, it lays the technical foundation for future tools that could give singers real‑time, anatomy‑aware feedback tailored to their own bodies, and for clinicians who need non‑invasive insight into how patients’ voices are produced.
Citation: Deng, M., Liu, C. & Yang, Z. Interpretable vocal tract and respiratory inversion via physics-informed neural operators. Sci Rep 16, 11401 (2026). https://doi.org/10.1038/s41598-026-40470-1
Keywords: vocal tract modeling, respiratory dynamics, voice timbre analysis, physics-informed neural networks, personalized vocal training