Clear Sky Science · zh
通过负热标签编码和类别权重屏蔽实现特征不可区分的机器遗忘
为何教会机器遗忘很重要
从照片标注到医学影像分析,现代应用依赖于使用海量数据训练出的强大图像识别系统。但当有人要求删除其数据,或当某个数据集被发现存在偏见或不安全时,会发生什么?当前的神经网络并没有一个简单的“删除”按钮。本文提出了一种实用方法,使已训练的模型对特定类别的数据“遗忘”,同时在很大程度上保留其对其他任务的能力。
需要抹去影响,而不仅仅是忽视数据
诸如欧盟通用数据保护条例等法律赋予人们“被遗忘权”,这意味着组织可能必须从其模型中消除某些数据的影响,而不仅仅是不再存储这些文件。每次都从头重训练大型神经网络既缓慢又昂贵,有时也不可能,因为原始数据不再完全可用。现有的“机器遗忘”方法可以提供帮助,但它们通常需要访问完整训练集、涉及繁重的数学计算,或明显损害剩余数据上的性能。作者致力于设计一种有针对性、高效且对模型已有有用知识友好的方法。
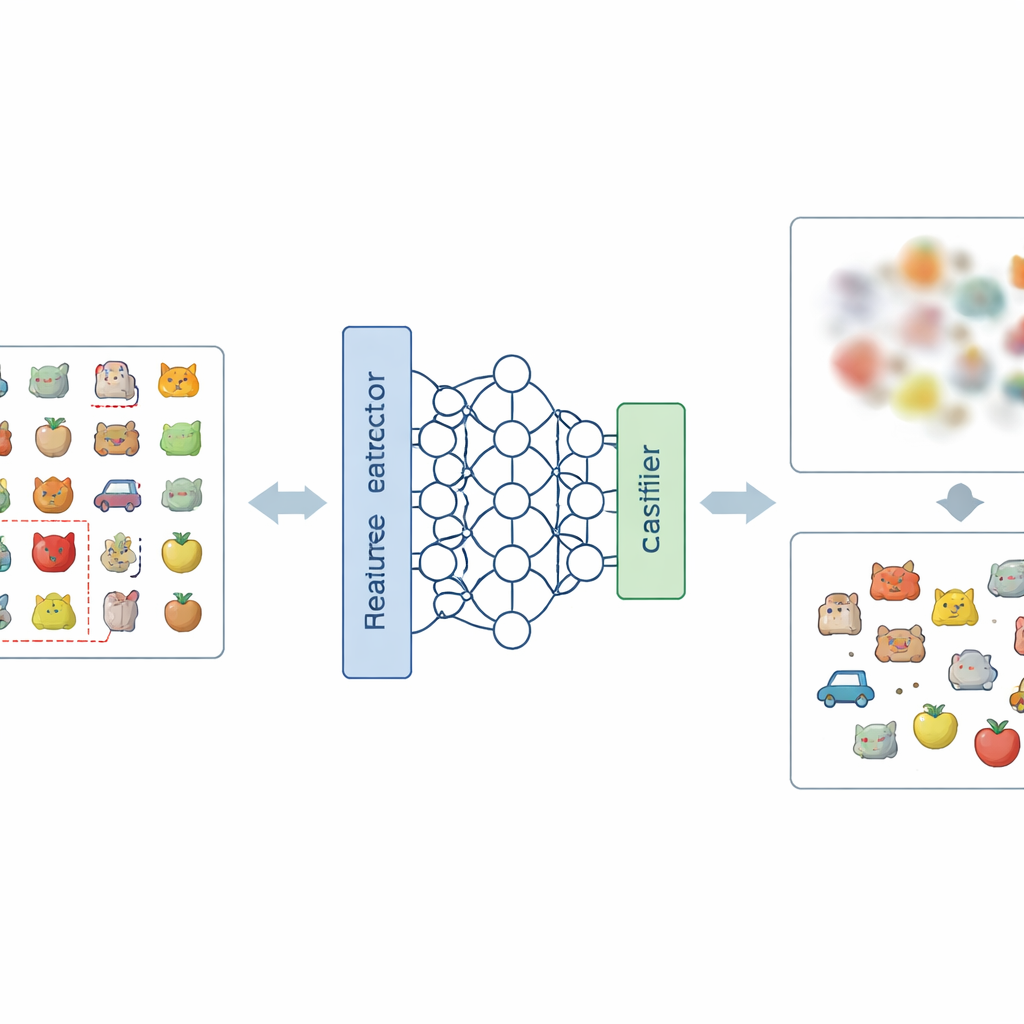
模糊不想要记忆的新方案
论文的核心思路是在两个层面上解决问题:网络如何在内部表示图像,以及如何作出最终决策。在表示层面,作者提出了一种新的标签编码方式,称为负热(Negative-Hot)标签编码。该方案不是强化需要被遗忘的类别,而是将其几乎视为一种“反类”。在短时微调阶段,仅使用来自待删除类别的一小部分图像,网络被引导使这些图像的内部描述变得不那么显著、并更易于与其他类别混杂。在决策层面,他们加入了类别权重屏蔽(Class Weight Masking),有选择地削弱与待遗忘类别相关的最终连接,切断其对输出的直接影响。
负标签如何削弱一个类别
普通图像分类器使用“单热”标签训练:正确类别被强调,其他类别置为零。这推动网络为每个类别划出清晰边界。负热标签编码对我们想要抹去的类别翻转了这种逻辑。在遗忘过程中,该类别被赋予负向贡献,而其余类别获得小的正向贡献。从数学上讲,这会逆转并放大曾使被遗忘类变得显著的梯度更新,逐步将其特征推回到群体中。网络内部特征空间的可视化显示,在这种方案下,来自被遗忘类别的点不再形成紧密、独立的簇,而是融入到周围其他类别的云中。
在保护其余部分的同时切断决策链接
仅改变标签并不足够,因为调整网络的早期层可能无意中扰动其识别其他类别的方式。类别权重屏蔽提供了一种直接且低成本的保障。在用负标签进行短时微调后,该方法识别并静音最终分类器层中与被遗忘类别最相关的模型组件。这一步骤显著降低了模型识别该类别的能力,而无需复杂的全局计算或访问所有训练样本。两步合力形成了NHLE–CWM框架:第一步在特征空间中模糊不想要的记忆,第二步切断其在决策上的残余影响,且两者都只使用来自待删除类别的一小部分示例进行调优。
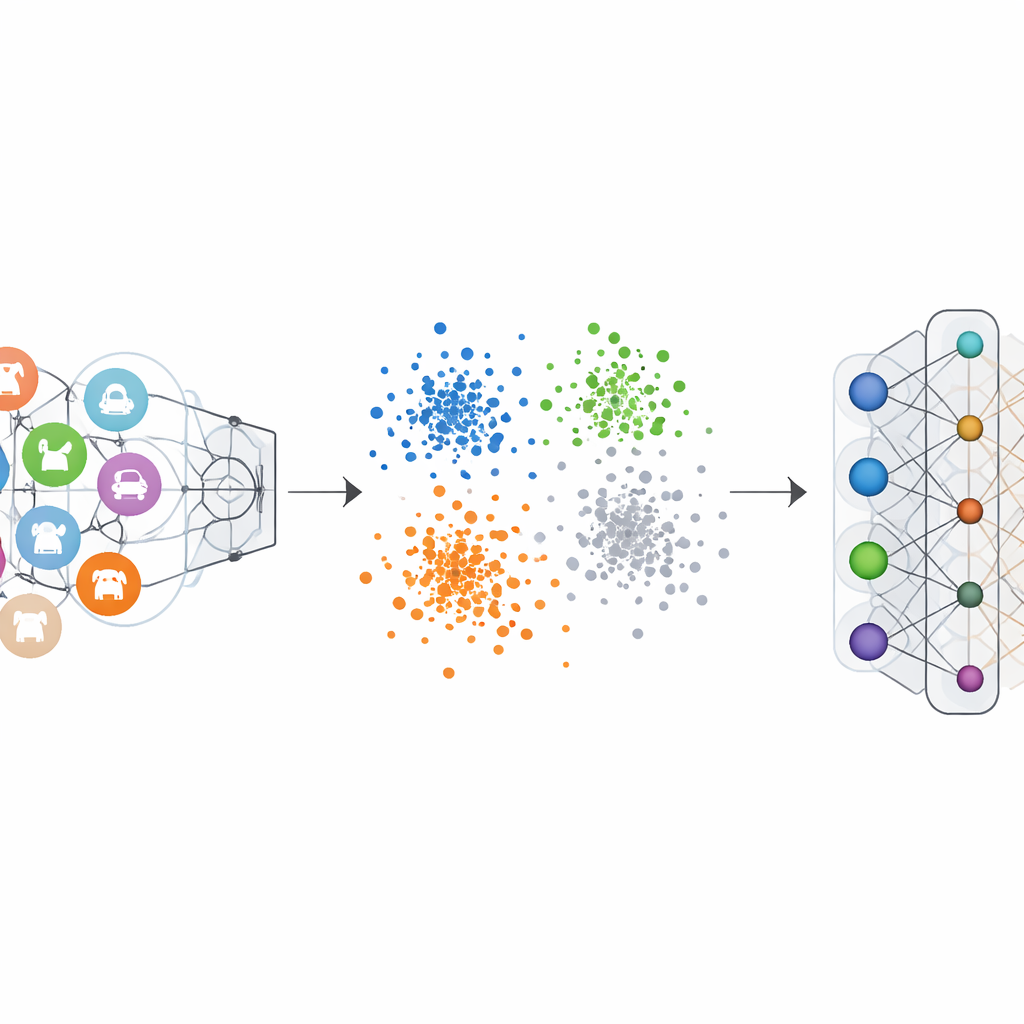
在多个视觉基准上的大量测试证明
作者在若干知名图像数据集上测试了他们的框架,包括手写数字、街景门牌号、服装图像和多彩物体照片,并采用了多种流行的神经网络架构。在单类和多类遗忘场景中,该方法将被遗忘类别的准确率降至几乎为零,使模型基本无法识别这些类别。关键是,保留类别的准确率最多仅下降了几个百分点,且在某些情况下甚至略有提升。与领先的遗忘方法比较表明,这种新方法在对剩余性能造成更小损害的同时实现了更强的遗忘效果,而且只需少量来自被遗忘类别的样本并避免了繁重计算。
对日常人工智能的意义
简单来说,这项工作表明可以为神经网络加装一个可控的“记忆擦除器”以针对特定类型的数据。通过在短暂的再训练步骤中巧妙改变标签的使用方式并屏蔽目标决策权重,NHLE–CWM框架使模型对被遗忘类别的表征既模糊又失去活性。对用户和监管方而言,这意味着在不丢弃有价值模型的情况下,更现实地实现被遗忘权。对实践者而言,它提供了一个可扩展且计算负担轻的工具,用于移除有偏、过时或敏感的类别,同时保持系统其余部分的完整性。
引用: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
关键词: 机器遗忘, 数据隐私, 深度学习, 图像分类, 模型遗忘