Clear Sky Science · ru
Стирание машинной памяти, неотличимое по признакам: отрицательно-горячая кодировка меток и маскирование весов классов
Почему важно учить машины забывать
Современные приложения — от автотегирования фото до анализа медицинских снимков — опираются на мощные системы распознавания изображений, обученные на огромных наборах данных. Но что происходит, когда кто-то требует удалить свои данные, или когда набор данных признают предвзятым или небезопасным? У современных нейросетей нет простой кнопки «удалить». В этой статье предложен практический способ заставить обученную модель «забыть» конкретные категории данных, при этом в значительной степени сохранив её навыки во всём остальном.
Когда данные нужно удалить, а не просто игнорировать
Законы, такие как Общий регламент по защите данных (GDPR) в Европе, предоставляют людям «право быть забытыми», что означает: организациям может потребоваться устранить влияние определённых данных на свои модели, а не просто перестать хранить файлы. Повторная тренировка большой нейросети с нуля каждый раз занимает много времени, дорого обходится и иногда невозможна, потому что исходные данные уже недоступны полностью. Существующие методы «машинного забывания» помогают, но часто требуют доступа ко всему тренировочному набору, включают тяжёлые математические вычисления или заметно ухудшают качество на оставшихся данных. Авторы поставили цель разработать подход, который будет прицельным, эффективным и мягким к уже усвоенным моделью знаниям.
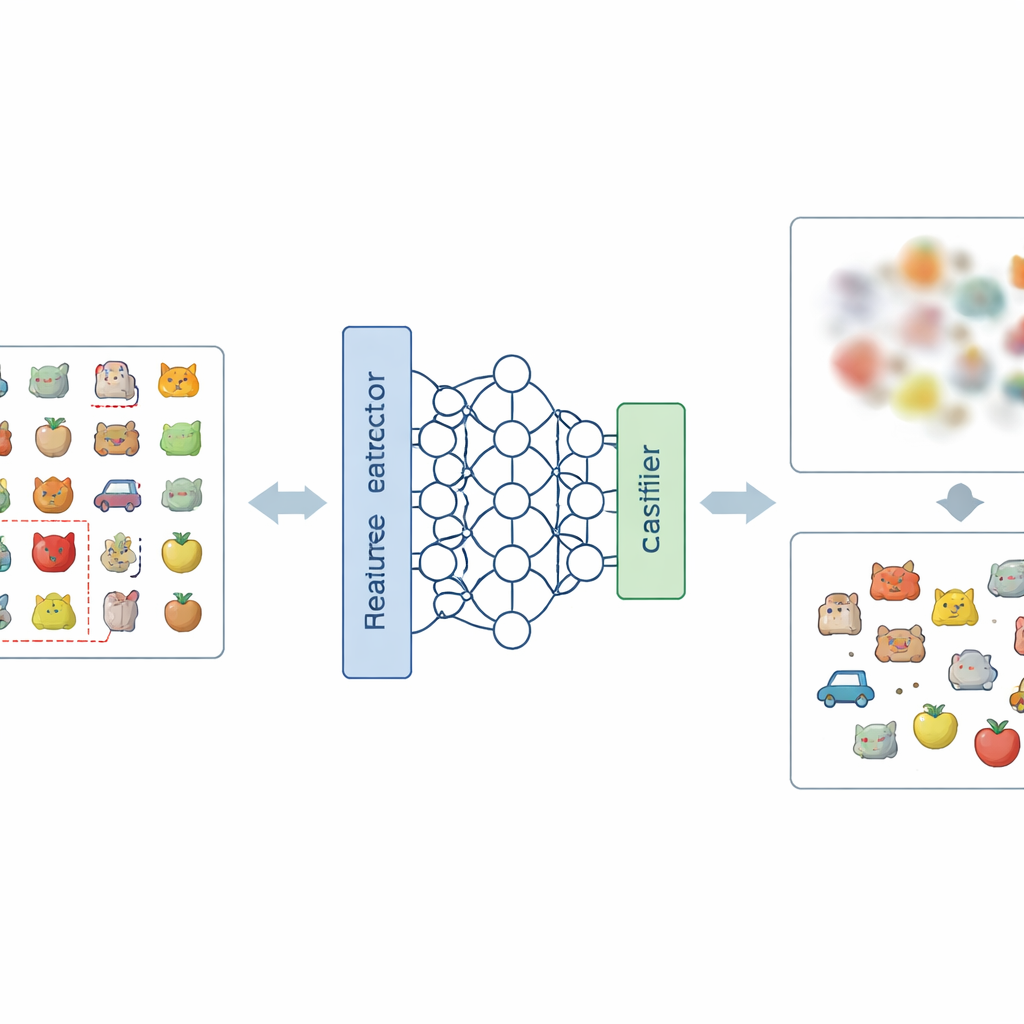
Новый рецепт для размывания нежелательных воспоминаний
Ключевая идея статьи — воздействовать на проблему на двух уровнях: на том, как сеть внутренне представляет изображения, и на том, как она принимает конечные решения. На уровне представлений авторы вводят новый способ кодирования меток, называемый отрицательно-горячей кодировкой меток (Negative-Hot Label Encoding). Вместо того чтобы усиливать категорию, которую нужно забыть, эта схема обращается с ней почти как с «антиклассом». Во время короткого этапа дообучения, используя лишь небольшое число изображений из категории, подлежащей удалению, сеть аккуратно настраивают так, чтобы её внутреннее представление этих изображений становилось менее отличительным и более перепутанным с другими классами. На уровне решений добавляют маскирование весов классов (Class Weight Masking), которое выборочно ослабляет конечные связи модели, связанные с категорией, от которой нужно избавиться, снижая её прямое влияние на выход.
Как отрицательные метки ослабляют категорию
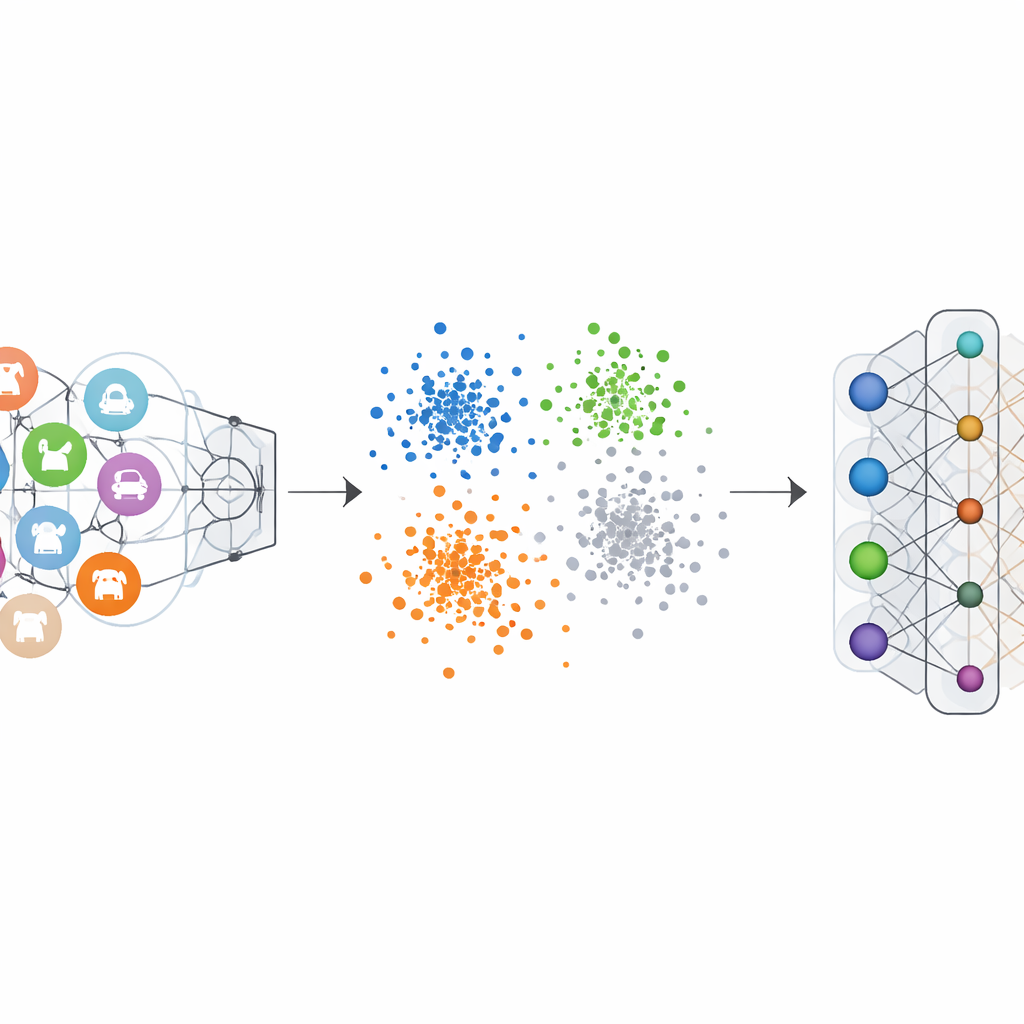
Обычные классификаторы изображений обучают с «one-hot» метками: правильный класс подчёркивают, а остальные ставят в ноль. Это заставляет сеть выделять чёткие границы для каждой категории. Отрицательно-горячая кодировка меток переворачивает эту логику для категории, которую хотят стереть. Во время процесса забывания этой категории придают отрицательный вклад, в то время как оставшимся классам дают небольшие положительные вклады. Математически это обращает и усиливает градиентные обновления, которые ранее делали забываемый класс настолько отличительным, постепенно возвращая его признаки обратно в общий поток. Визуализации внутреннего пространства признаков сети показывают, что при этой схеме точки из забываемого класса перестают образовывать плотный, отдельный кластер и вместо этого смешиваются с окружающим облаком других классов.
Отрубание связей решений при защите остального
Изменение меток само по себе недостаточно, потому что корректировка ранних слоёв сети может непреднамеренно нарушить распознавание других категорий. Маскирование весов классов даёт прямую и недорогую защиту. После короткого дообучения с отрицательными метками метод выявляет и приглушает компоненты модели, наиболее связанные с забываемой категорией в последнем слое классификатора. Этот шаг резко снижает способность модели выделять эту категорию, без необходимости сложных глобальных вычислений или доступа ко всем примерам обучения. Вдвоём эти шаги формируют рамку NHLE–CWM: первый размывает нежелательное «воспоминание» в пространстве признаков, второй отрезает его оставшееся влияние на решения, причём оба настраиваются, используя только небольшое число образцов из классов, подлежащих удалению.
Доказательства — многочисленные тесты на бенчмарках по зрению
Авторы протестировали свою рамку на нескольких хорошо известных наборах изображений, включая рукописные цифры, номера домов с уличных вывесок, изображения одежды и цветные фотографии объектов, используя разнообразные популярные архитектуры нейросетей. В сценариях забывания одного класса и нескольких классов метод снижал точность по забываемым классам почти до нуля, фактически делая модель неспособной их распознавать. Что важно, точность по сохраняемым классам падала максимум на несколько процентных пунктов, а в некоторых случаях даже слегка улучшалась. Сравнения с ведущими методами забывания показали, что новый подход достигает более сильного забывания при меньшем ущербе для оставшейся производительности, при этом требуя лишь небольшого набора примеров из забываемых классов и избегая тяжёлых вычислений.
Что это значит для повседневного ИИ
Проще говоря, эта работа показывает, что возможно дооснастить нейросети контролируемым «стиранием памяти» для конкретных типов данных. Умелое изменение использования меток во время краткого этапа дообучения и маскирование целевых весов решений делает представление модели о забываемой категории одновременно размытым и неактивным. Для пользователей и регуляторов это означает более реалистичный путь к исполнению права на забвение без уничтожения ценных моделей. Для практиков это даёт масштабируемый и вычислительно лёгкий инструмент для удаления предвзятых, устаревших или чувствительных классов, сохраняя при этом остальную часть системы нетронутой.
Цитирование: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Ключевые слова: машинное забывание, конфиденциальность данных, глубокое обучение, классификация изображений, забывание модели