Clear Sky Science · pt
Desaprendizado de máquina indistinguível por características via codificação de rótulo negativo-quente e mascaramento de pesos de classe
Por que ensinar máquinas a esquecer importa
Aplicativos modernos — desde marcação de fotos até análise de imagens médicas — dependem de sistemas poderosos de reconhecimento de imagens treinados em grandes conjuntos de dados. Mas o que acontece quando alguém pede que seus dados sejam removidos, ou quando um conjunto de dados é considerado tendencioso ou inseguro? As redes neurais atuais não trazem um simples botão de “excluir”. Este artigo apresenta uma forma prática de fazer um modelo treinado “esquecer” categorias específicas de dados, preservando em grande medida suas habilidades no restante.
Quando os dados devem ser apagados, não apenas ignorados
Leis como o Regulamento Geral sobre a Proteção de Dados da Europa conferem às pessoas o “direito ao esquecimento”, o que implica que organizações podem precisar remover a influência de certos dados de seus modelos, não apenas deixar de armazenar os arquivos. Retreinar uma grande rede neural do zero toda vez que isso ocorre é lento, caro e, às vezes, impossível porque os dados originais já não estão totalmente disponíveis. Métodos existentes de “desaprendizado de máquina” podem ajudar, mas frequentemente exigem acesso ao conjunto de treinamento completo, envolvem cálculos matemáticos pesados ou prejudicam perceptivelmente o desempenho nos dados remanescentes. Os autores propuseram um método que fosse direcionado, eficiente e pouco agressivo ao conhecimento útil do modelo.
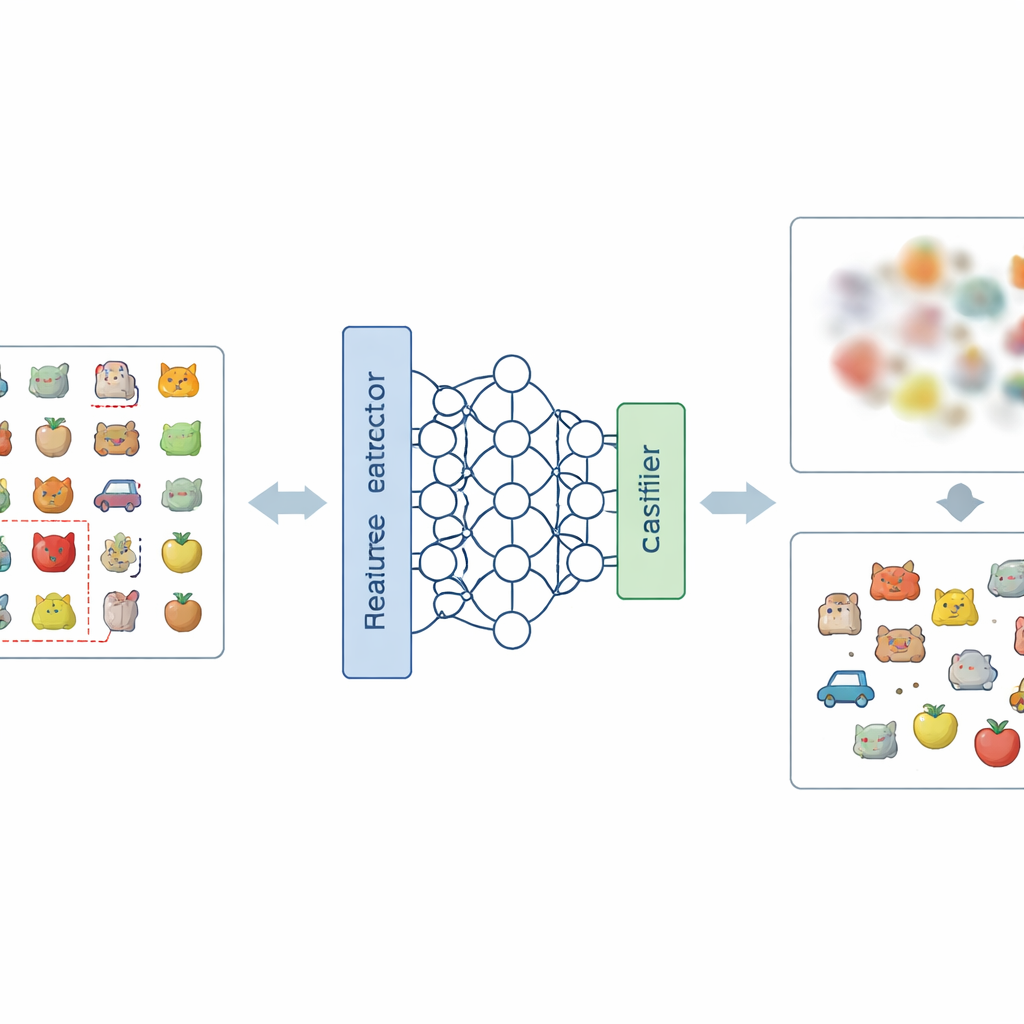
Uma nova receita para borrar memórias indesejadas
A ideia central do artigo é atacar o problema em dois níveis: como a rede representa imagens internamente e como ela toma decisões finais. No nível de representação, os autores introduzem uma nova forma de codificar rótulos, chamada Codificação de Rótulo Negativo-Quente (Negative-Hot Label Encoding). Em vez de reforçar a categoria que deve ser esquecida, esse esquema a trata quase como uma “anti-classe”. Durante uma breve fase de ajuste fino, usando apenas um pequeno conjunto de imagens da categoria a ser removida, a rede é deslocada para que sua descrição interna dessas imagens se torne menos distinta e mais entrelaçada com as outras classes. No nível de decisão, eles adicionam o Mascaramento de Pesos de Classe (Class Weight Masking), que enfraquece seletivamente as conexões finais do modelo associadas à categoria a ser esquecida, cortando sua influência direta na saída.
Como rótulos negativos enfraquecem uma categoria
Classificadores de imagem comuns são treinados com rótulos “one-hot”: a classe correta é enfatizada e as demais são zeradas. Isso força a rede a traçar uma fronteira clara para cada categoria. A Codificação de Rótulo Negativo-Quente inverte essa lógica para a categoria que queremos apagar. Durante o desaprendizado, essa categoria recebe uma contribuição negativa, enquanto as categorias restantes recebem pequenas contribuições positivas. Matematicamente, isso inverte e amplifica as atualizações de gradiente que antes tornavam a classe esquecida tão distinta, empurrando gradualmente suas características de volta para a multidão. Visualizações do espaço de características interno da rede mostram que, sob esse esquema, pontos da classe esquecida deixam de formar um cluster separado e compacto e passam a se misturar à nuvem circundante de outras classes.
Cortando ligações de decisão enquanto protege o que resta
Apenas alterar rótulos não é suficiente, porque ajustar as camadas iniciais da rede pode perturbar involuntariamente como ela reconhece outras categorias. O Mascaramento de Pesos de Classe fornece uma salvaguarda direta e barata. Após o curto ajuste fino com rótulos negativos, o método identifica e silencia os componentes do modelo mais ligados à categoria esquecida na camada final do classificador. Essa etapa reduz fortemente a capacidade do modelo de detectar essa categoria, sem exigir cálculos globais complexos ou acesso a todos os exemplos de treinamento. Juntas, as duas etapas formam a estrutura NHLE–CWM: a primeira desfoca a memória indesejada no espaço de características, a segunda corta sua influência remanescente nas decisões, e ambas são ajustadas usando apenas um pequeno número de imagens de exemplo das classes a serem removidas.
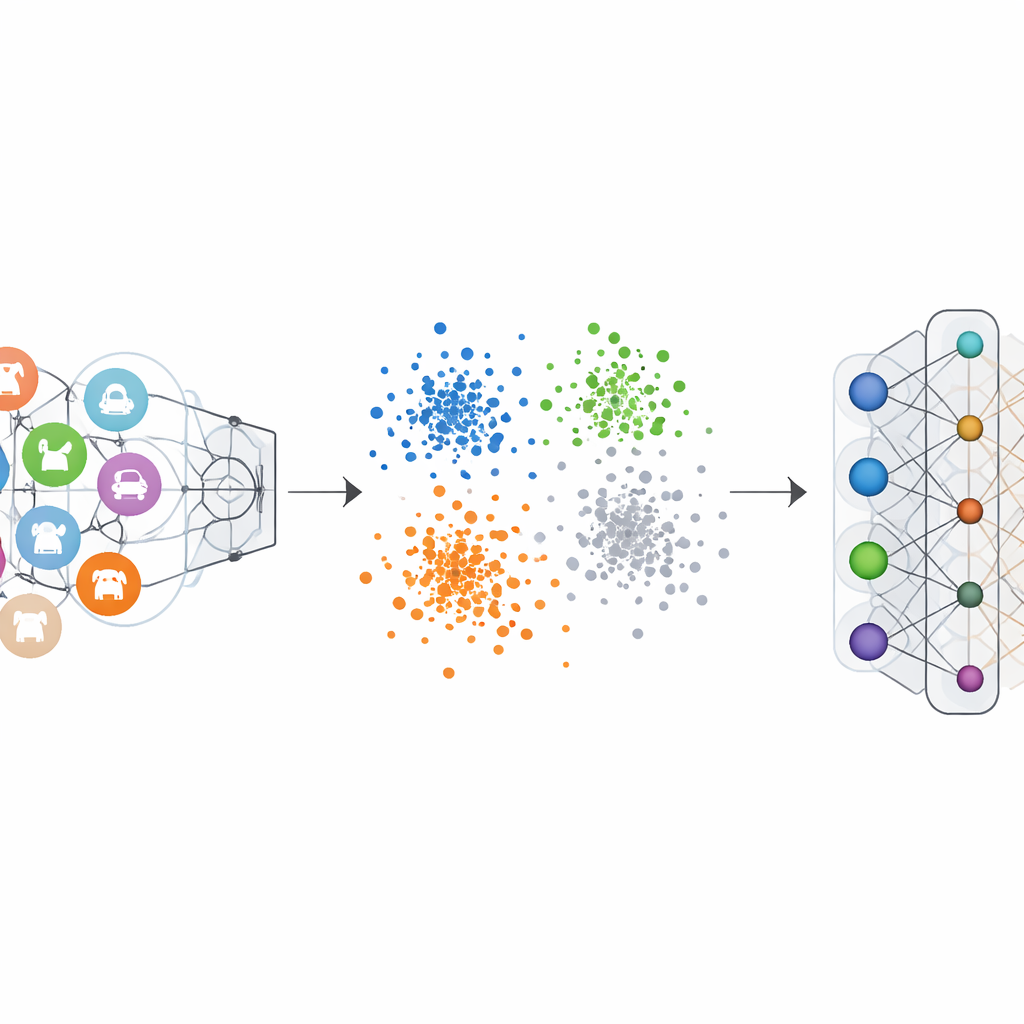
Prova a partir de muitos testes em benchmarks de visão
Os autores testaram sua estrutura em vários conjuntos de imagens bem conhecidos, incluindo dígitos manuscritos, números de casas em vistas de rua, imagens de vestuário e fotos coloridas de objetos, usando uma variedade de arquiteturas neurais populares. Em cenários de esquecimento de classe única e múltipla, o método levou a acurácia nas classes esquecidas quase a zero, tornando o modelo incapaz de reconhecê-las. Crucialmente, a acurácia nas classes mantidas caiu no máximo alguns pontos percentuais e, em alguns casos, até melhorou ligeiramente. Comparações com métodos de desaprendizado líderes mostraram que essa nova abordagem alcançou um esquecimento mais forte com menos dano ao desempenho remanescente, tudo isso exigindo apenas um pequeno conjunto de exemplos das classes a esquecer e evitando cálculos pesados.
O que isso significa para a IA do dia a dia
Em termos simples, este trabalho mostra que é possível adaptar redes neurais com um “apagador de memória” controlado para tipos específicos de dados. Ao mudar de forma inteligente como os rótulos são usados durante uma breve etapa de retreinamento e ao mascarar pesos de decisão direcionados, a estrutura NHLE–CWM torna a representação da categoria esquecida pelo modelo ao mesmo tempo borrada e inativa. Para usuários e reguladores, isso significa um caminho mais realista para aplicar o direito ao esquecimento sem descartar modelos valiosos. Para praticantes, oferece uma ferramenta escalável e computacionalmente leve para remover classes tendenciosas, desatualizadas ou sensíveis, preservando o restante do sistema intacto.
Citação: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Palavras-chave: desaprendizado de máquina, privacidade de dados, aprendizado profundo, classificação de imagens, esquecimento de modelo