Clear Sky Science · nl
Machine-unlearning ononderscheidbaar in kenmerken via negative-hot label-encodering en class weight masking
Waarom het belangrijk is machines te leren vergeten
Moderne toepassingen — van fototagging tot medische beeldanalyse — vertrouwen op krachtige beeldherkenningssystemen die zijn getraind op enorme datasets. Maar wat gebeurt er wanneer iemand vraagt zijn gegevens te laten verwijderen, of wanneer een dataset als vooringenomen of onveilig wordt aangemerkt? Hedendaagse neurale netwerken hebben geen eenvoudige “verwijder”-knop. Dit artikel introduceert een praktische manier om een getraind model specifieke categorieën data te laten “vergeten”, terwijl de rest van zijn vaardigheden grotendeels behouden blijft.
Wanneer gegevens gewist moeten worden, niet alleen genegeerd
Wetten zoals de Europese Algemene Verordening Gegevensbescherming geven mensen het “recht om te worden vergeten”, wat betekent dat organisaties mogelijk de invloed van bepaalde gegevens uit hun modellen moeten verwijderen, en niet alleen hoeven te stoppen met het opslaan van bestanden. Het helemaal opnieuw trainen van een groot neuraal netwerk telkens dit nodig is, is traag, duur en soms onmogelijk omdat de oorspronkelijke data niet meer volledig beschikbaar zijn. Bestaande methoden voor “machine unlearning” kunnen helpen, maar vragen vaak toegang tot de volledige trainingsset, vereisen zware wiskundige berekeningen of schaden merkbaar de prestaties op de overgebleven data. De auteurs wilden een aanpak ontwerpen die doelgericht, efficiënt en zacht voor de nuttige kennis van het model is.
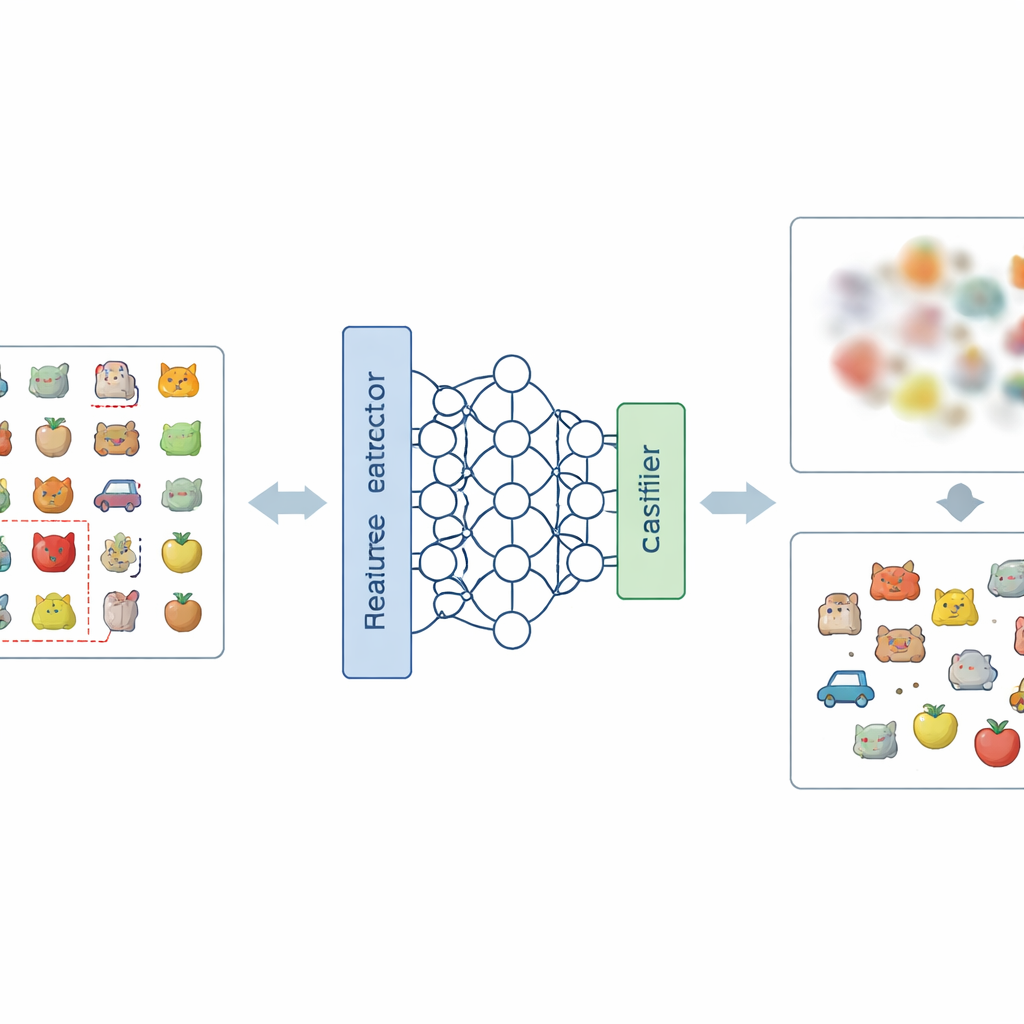
Een nieuw recept om ongewenste herinneringen te vervagen
De kernidee van het artikel is het probleem op twee niveaus aan te pakken: hoe het netwerk beelden intern voorstelt en hoe het tot zijn uiteindelijke beslissingen komt. Op representatieniveau introduceren de auteurs een nieuwe manier van labelen, Negative-Hot Label Encoding. In plaats van de categorie die moet worden vergeten te versterken, behandelt dit schema die bijna als een “anti-klasse”. Tijdens een korte fijnslijpingsfase, waarbij slechts een klein handjevol beelden uit de te verwijderen categorie wordt gebruikt, wordt het netwerk zodanig gestuurd dat zijn interne beschrijving van die beelden minder onderscheidend wordt en meer vermengd raakt met de andere klassen. Op beslissingsniveau voegen ze Class Weight Masking toe, waarmee selectief de uiteindelijke verbindingen van het model die aan de te vergeten categorie zijn gekoppeld worden verzwakt, waardoor de directe invloed op de output wordt verminderd.
Hoe negatieve labels een categorie verzwakken
Gewone beeldclassifiers worden getraind met “one-hot”-labels: de juiste klasse wordt benadrukt en de anderen op nul gezet. Dat duwt het netwerk ertoe voor elke categorie een duidelijke grens te vormen. Negative-Hot Label Encoding keert deze logica om voor de categorie die we willen wissen. Tijdens het unlearningproces krijgt die categorie een negatieve bijdrage, terwijl de overgebleven categorieën kleine positieve bijdragen ontvangen. Wiskundig keert dit de en vergroot het gewicht van de gradientupdates die de vergeten klasse eens zo onderscheidend maakten, waardoor zijn kenmerken geleidelijk teruggeduwd worden naar de massa. Visualisaties van de interne featurespace van het netwerk tonen dat, onder dit schema, punten van de vergeten klasse stoppen met het vormen van een compacte, aparte cluster en zich in plaats daarvan mengen met de omliggende wolk van andere klassen.
Besnijden van beslissingslinks terwijl het overige beschermd blijft
Het alleen aanpassen van labels is niet voldoende, omdat het bijstellen van de vroege lagen van het netwerk onbedoeld kan verstoren hoe het andere categorieën herkent. Class Weight Masking biedt een directe en goedkope bescherming. Na de korte fijnslijping met negatieve labels identificeert en dempt de methode de modelcomponenten die het meest verbonden zijn met de vergeten categorie in de laatste classificatielaag. Deze stap reduceert sterk het vermogen van het model om die categorie te herkennen, zonder complexe globale berekeningen of toegang tot alle trainingsvoorbeelden te vereisen. Samen vormen de twee stappen het NHLE–CWM-framework: de eerste vervaagt de ongewenste herinnering in de featurespace, de tweede verbreekt de resterende invloed op beslissingen, en beide worden afgesteld met slechts een klein aantal voorbeeldbeelden van de te verwijderen klassen.
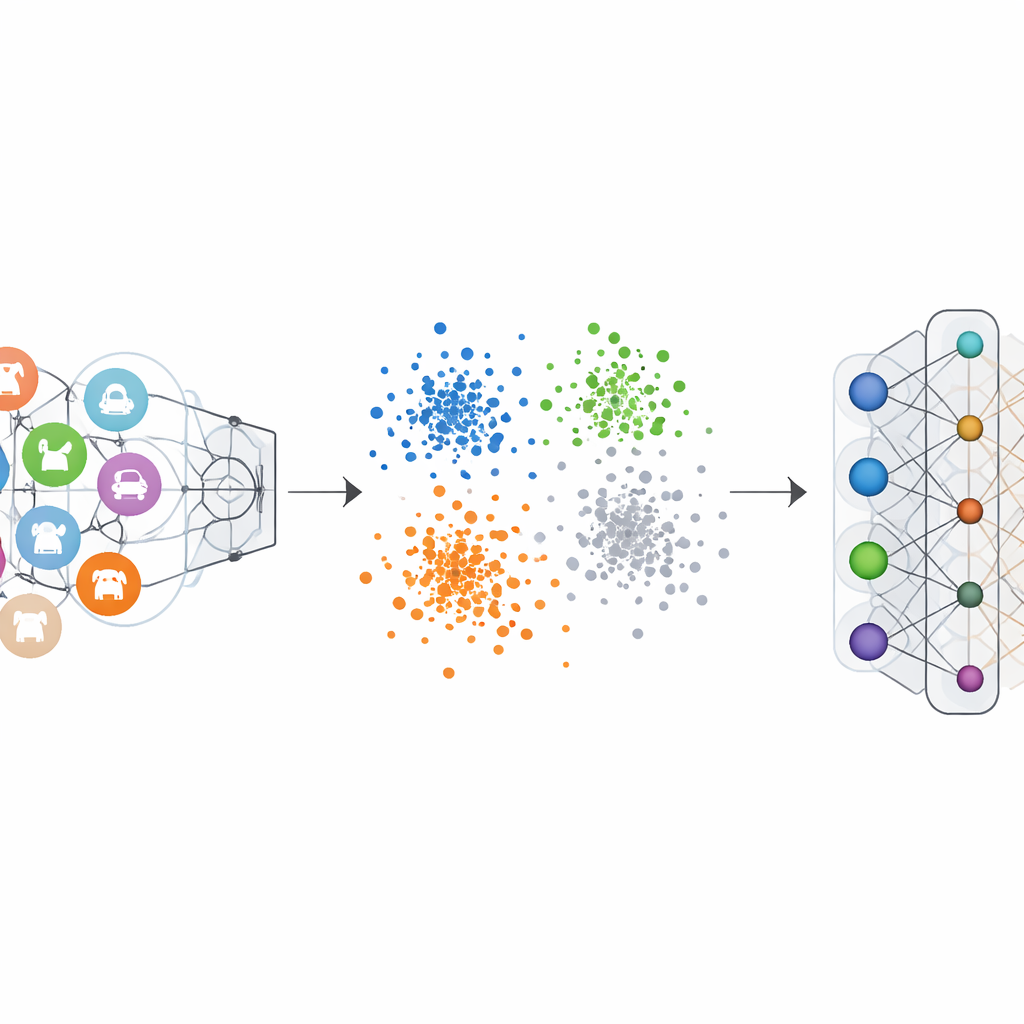
Bewijs uit vele tests op visuele benchmarks
De auteurs testten hun framework op meerdere bekende beelddatasets, waaronder handgeschreven cijfers, straatnummers, kledingafbeeldingen en kleurrijke objectfoto’s, met een verscheidenheid aan populaire neurale netwerkarchitecturen. In zowel single-class als multi-class forgetting-scenario’s bracht de methode de nauwkeurigheid op de vergeten klassen bijna tot nul, waardoor het model ze effectief niet meer kon herkennen. Cruciaal is dat de nauwkeurigheid op de behouden klassen met hooguit enkele procentpunten daalde, en in sommige gevallen zelfs licht verbeterde. Vergelijkingen met vooraanstaande unlearning-methoden toonden dat deze nieuwe aanpak sterkere vergetelheid bereikte met minder schade aan de resterende prestaties, terwijl slechts een kleine set voorbeelden van de te vergeten klassen nodig was en zware berekeningen werden vermeden.
Wat dit betekent voor alledaagse AI
In eenvoudige termen laat dit werk zien dat het mogelijk is neurale netwerken achteraf uit te rusten met een gecontroleerde “geheugenwisser” voor specifieke soorten data. Door slim te veranderen hoe labels tijdens een korte hertraining worden gebruikt en door gerichte beslissingsgewichten te maskeren, maakt het NHLE–CWM-framework het beeld van de vergeten categorie in het model zowel wazig als inactief. Voor gebruikers en toezichthouders betekent dat een realistischer pad naar handhaving van het recht om te worden vergeten zonder waardevolle modellen weg te gooien. Voor praktijkmensen biedt het een schaalbaar en computationeel licht instrument om bevooroordeelde, verouderde of gevoelige klassen te verwijderen terwijl de rest van het systeem intact blijft.
Bronvermelding: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Trefwoorden: machine unlearning, gegevensprivacy, deep learning, beeldclassificatie, modelvergetelheid