Clear Sky Science · en
Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking
Why teaching machines to forget matters
Modern apps—from photo tagging to medical image analysis—rely on powerful image-recognition systems trained on huge datasets. But what happens when someone asks to have their data removed, or when a dataset is found to be biased or unsafe? Today’s neural networks do not come with a simple “delete” button. This paper introduces a practical way to make a trained model “forget” specific categories of data, while largely preserving its skills on everything else.
When data must be erased, not just ignored
Laws such as Europe’s General Data Protection Regulation give people a “right to be forgotten,” which means organizations may need to remove the influence of certain data from their models, not merely stop storing the files. Retraining a large neural network from scratch every time this happens is slow, expensive, and sometimes impossible because the original data are no longer fully available. Existing “machine unlearning” methods can help, but they often require access to the full training set, involve heavy mathematical computations, or noticeably harm performance on the remaining data. The authors set out to design an approach that is targeted, efficient, and gentle on the model’s useful knowledge.
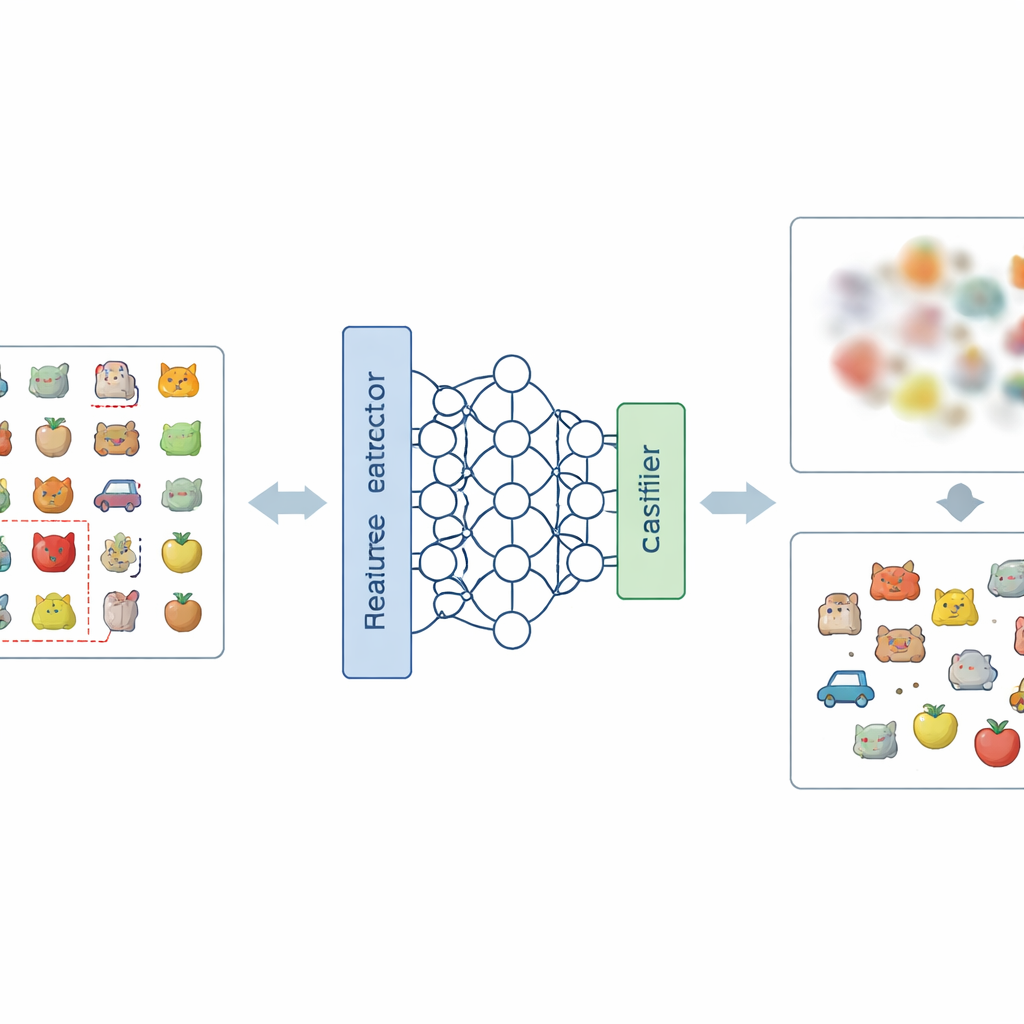
A new recipe for blurring unwanted memories
The core idea of the paper is to attack the problem at two levels: how the network represents images internally, and how it makes final decisions. At the representation level, the authors introduce a new way of encoding labels, called Negative-Hot Label Encoding. Instead of reinforcing the category that should be forgotten, this scheme treats it almost like an “anti-class.” During a short fine-tuning phase, using only a small handful of images from the category to be removed, the network is nudged so that its internal description of those images becomes less distinctive and more tangled up with the other classes. At the decision level, they add Class Weight Masking, which selectively weakens the model’s final connections associated with the to-be-forgotten category, cutting its direct influence on the output.
How negative labels weaken a category
Ordinary image classifiers are trained with “one-hot” labels: the correct class is emphasized, and the others are set to zero. This pushes the network to carve out a clear boundary for each category. Negative-Hot Label Encoding flips this logic for the category we want to erase. During unlearning, that category is given a negative contribution, while the remaining categories receive small positive contributions. Mathematically, this reverses and amplifies the gradient updates that once made the forgotten class so distinctive, gradually pushing its features back toward the crowd. Visualizations of the network’s internal feature space show that, under this scheme, points from the forgotten class stop forming a tight, separate cluster and instead blend into the surrounding cloud of other classes.
Cutting decision links while protecting what remains
Altering labels alone is not enough, because adjusting the early layers of the network can unintentionally disturb how it recognizes other categories. Class Weight Masking provides a direct and inexpensive safeguard. After the short fine-tuning with negative labels, the method identifies and mutes the model components most tied to the forgotten category in the final classifier layer. This step sharply reduces the model’s ability to pick out that category, without requiring complex global calculations or access to all training examples. Together, the two steps form the NHLE–CWM framework: the first blurs the unwanted memory in feature space, the second severs its remaining influence on decisions, and both are tuned using only a small number of sample images from the classes to be removed.
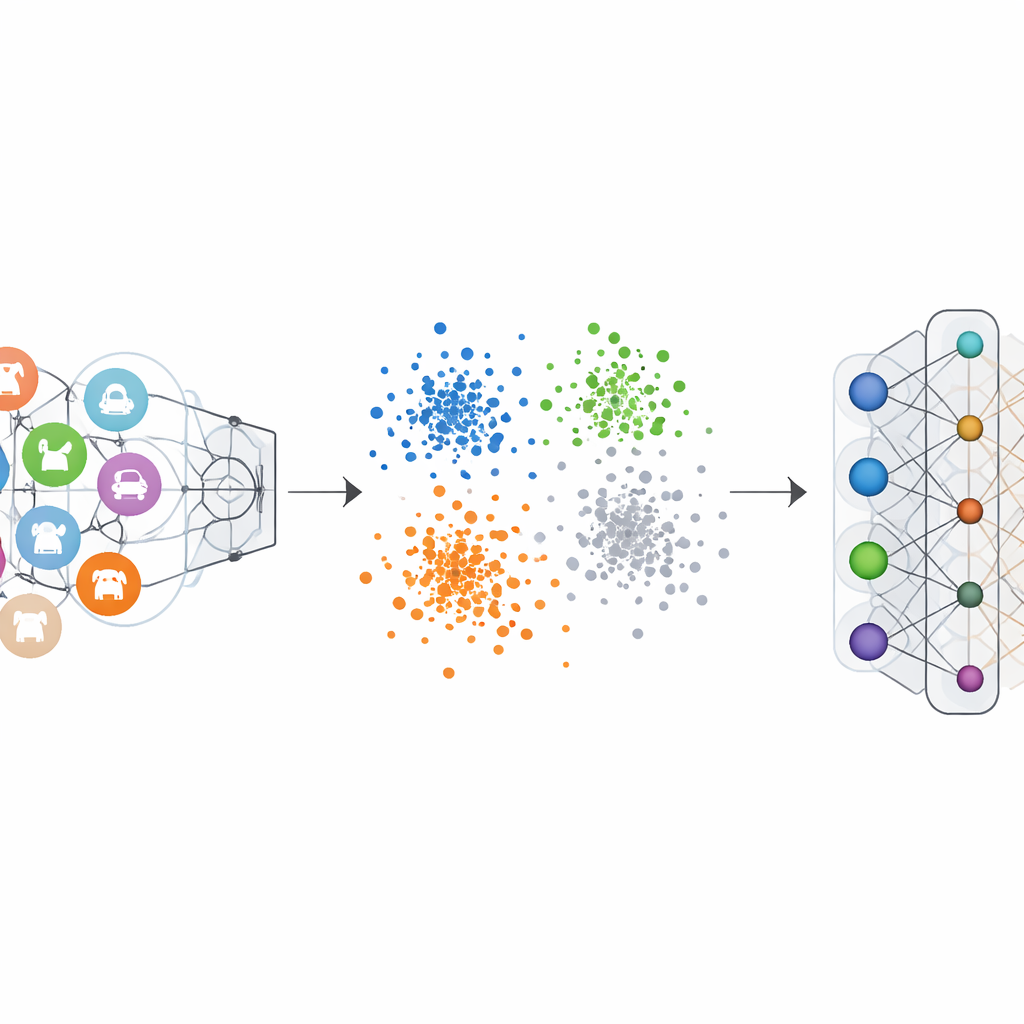
Proof from many tests on vision benchmarks
The authors tested their framework on several well-known image datasets, including handwritten digits, street-view house numbers, clothing images, and colourful object photos, using a variety of popular neural network architectures. In both single-class and multi-class forgetting scenarios, the method drove the accuracy on the forgotten classes down to nearly zero, effectively making the model unable to recognize them. Crucially, the accuracy on the retained classes dropped by at most a few percentage points, and in some cases even improved slightly. Comparisons with leading unlearning methods showed that this new approach achieved stronger forgetting with less damage to the remaining performance, all while needing only a small set of examples from the classes to forget and avoiding heavy computations.
What this means for everyday AI
In simple terms, this work shows that it is possible to retrofit neural networks with a controlled “memory eraser” for specific kinds of data. By cleverly changing how labels are used during a brief retraining step and by masking targeted decision weights, the NHLE–CWM framework makes the model’s view of the forgotten category both blurry and inactive. For users and regulators, that means a more realistic path toward enforcing the right to be forgotten without discarding valuable models. For practitioners, it offers a scalable and computationally light tool to remove biased, outdated, or sensitive classes while keeping the rest of the system intact.
Citation: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Keywords: machine unlearning, data privacy, deep learning, image classification, model forgetting