Clear Sky Science · es
Olvido automático de características en modelos mediante codificación de etiqueta negativo-activa y enmascaramiento de pesos de clase
Por qué enseñar a las máquinas a olvidar importa
Las aplicaciones modernas —desde el etiquetado de fotos hasta el análisis de imágenes médicas— dependen de potentes sistemas de reconocimiento de imágenes entrenados con conjuntos de datos enormes. Pero ¿qué ocurre cuando alguien pide que sus datos se eliminen, o cuando se detecta que un conjunto de datos es sesgado o inseguro? Las redes neuronales actuales no traen un botón simple de “eliminar”. Este artículo presenta una manera práctica de hacer que un modelo ya entrenado “olvide” categorías específicas de datos, preservando en gran medida sus habilidades en todo lo demás.
Cuando los datos deben borrarse, no solo ignorarse
Leyes como el Reglamento General de Protección de Datos de Europa otorgan a las personas un “derecho al olvido”, lo que significa que las organizaciones pueden necesitar eliminar la influencia de ciertos datos en sus modelos, no simplemente dejar de almacenar los archivos. Volver a entrenar una red neuronal grande desde cero cada vez que esto ocurre es lento, costoso y a veces imposible porque los datos originales ya no están totalmente disponibles. Los métodos existentes de “olvido automático” pueden ayudar, pero a menudo requieren acceso al conjunto de entrenamiento completo, implican cálculos matemáticos pesados o perjudican de forma notable el rendimiento en los datos restantes. Los autores se propusieron diseñar un enfoque que fuera dirigido, eficiente y respetuoso con el conocimiento útil del modelo.
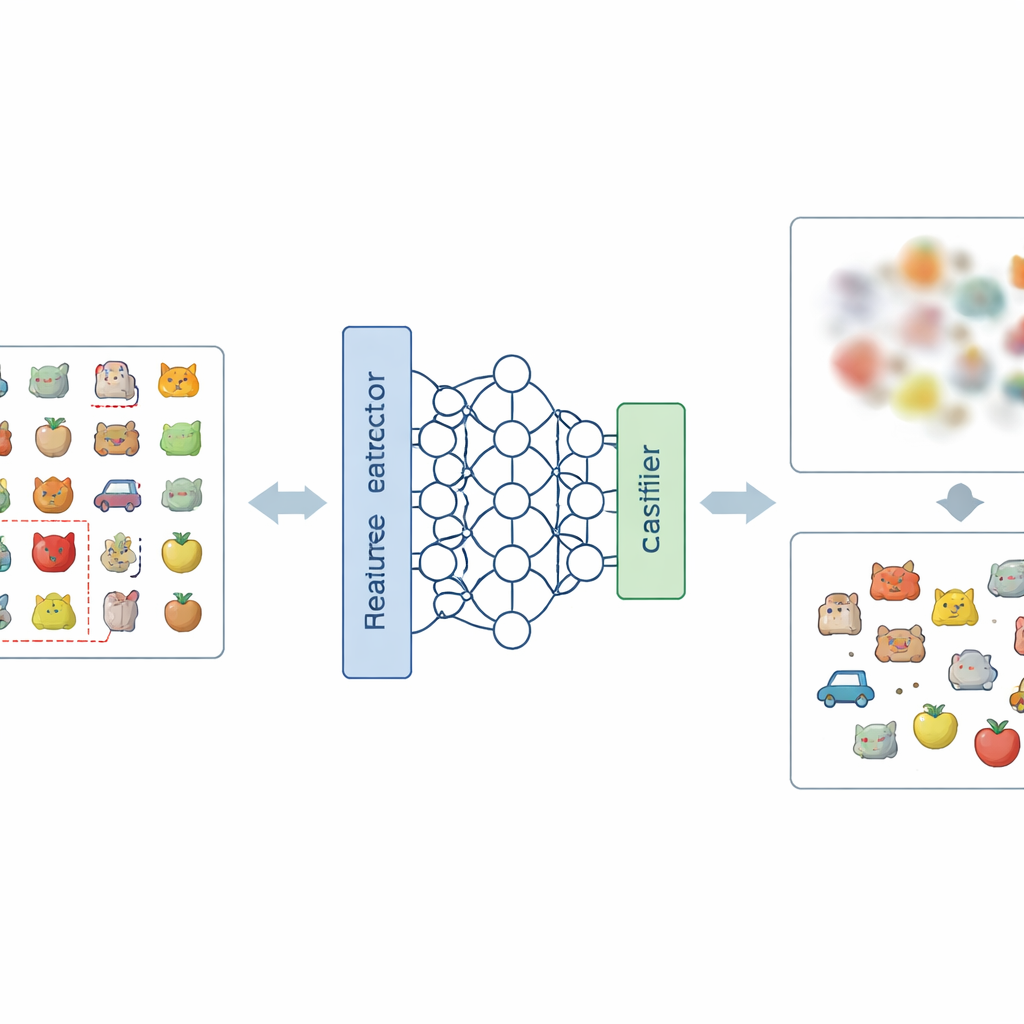
Una nueva receta para difuminar recuerdos no deseados
La idea central del artículo es atacar el problema en dos niveles: cómo la red representa internamente las imágenes y cómo toma las decisiones finales. A nivel de representación, los autores introducen una nueva forma de codificar etiquetas, llamada Codificación de Etiqueta Negativo-Activa (Negative-Hot Label Encoding). En lugar de reforzar la categoría que debe olvidarse, este esquema la trata casi como una “anti-clase”. Durante una breve fase de ajuste fino, usando solo un puñado pequeño de imágenes de la categoría a eliminar, la red se impulsa para que su descripción interna de esas imágenes sea menos distintiva y más enmarañada con las demás clases. A nivel de decisión, añaden el Enmascaramiento de Pesos de Clase (Class Weight Masking), que debilita selectivamente las conexiones finales del modelo asociadas a la categoría a olvidar, reduciendo su influencia directa en la salida.
Cómo las etiquetas negativas debilitan una categoría
Los clasificadores de imágenes ordinarios se entrenan con etiquetas “one-hot”: la clase correcta se enfatiza y las demás se ponen a cero. Esto empuja a la red a esculpir un límite claro para cada categoría. La Codificación de Etiqueta Negativo-Activa invierte esta lógica para la categoría que queremos borrar. Durante el proceso de olvido, a esa categoría se le asigna una contribución negativa, mientras que las categorías restantes reciben pequeñas contribuciones positivas. Matemáticamente, esto invierte y amplifica las actualizaciones del gradiente que en su día hicieron a la clase olvidada tan distintiva, empujando gradualmente sus características de vuelta hacia la multitud. Las visualizaciones del espacio de características interno de la red muestran que, bajo este esquema, los puntos de la clase olvidada dejan de formar un clúster compacto y separado y, en su lugar, se mezclan con la nube circundante de otras clases.
Cortar los vínculos de decisión mientras se protege lo que queda
Alterar solo las etiquetas no es suficiente, porque ajustar las capas tempranas de la red puede perturbar sin querer cómo reconoce otras categorías. El Enmascaramiento de Pesos de Clase proporciona una salvaguarda directa y económica. Tras el breve ajuste fino con etiquetas negativas, el método identifica y silencia los componentes del modelo más ligados a la categoría olvidada en la capa clasificadora final. Este paso reduce drásticamente la capacidad del modelo para detectar esa categoría, sin requerir cálculos globales complejos ni acceso a todos los ejemplos de entrenamiento. Juntos, los dos pasos forman el marco NHLE–CWM: el primero difumina el recuerdo no deseado en el espacio de características, el segundo corta su influencia restante en las decisiones, y ambos se ajustan usando solo un pequeño número de imágenes de muestra de las clases a eliminar.
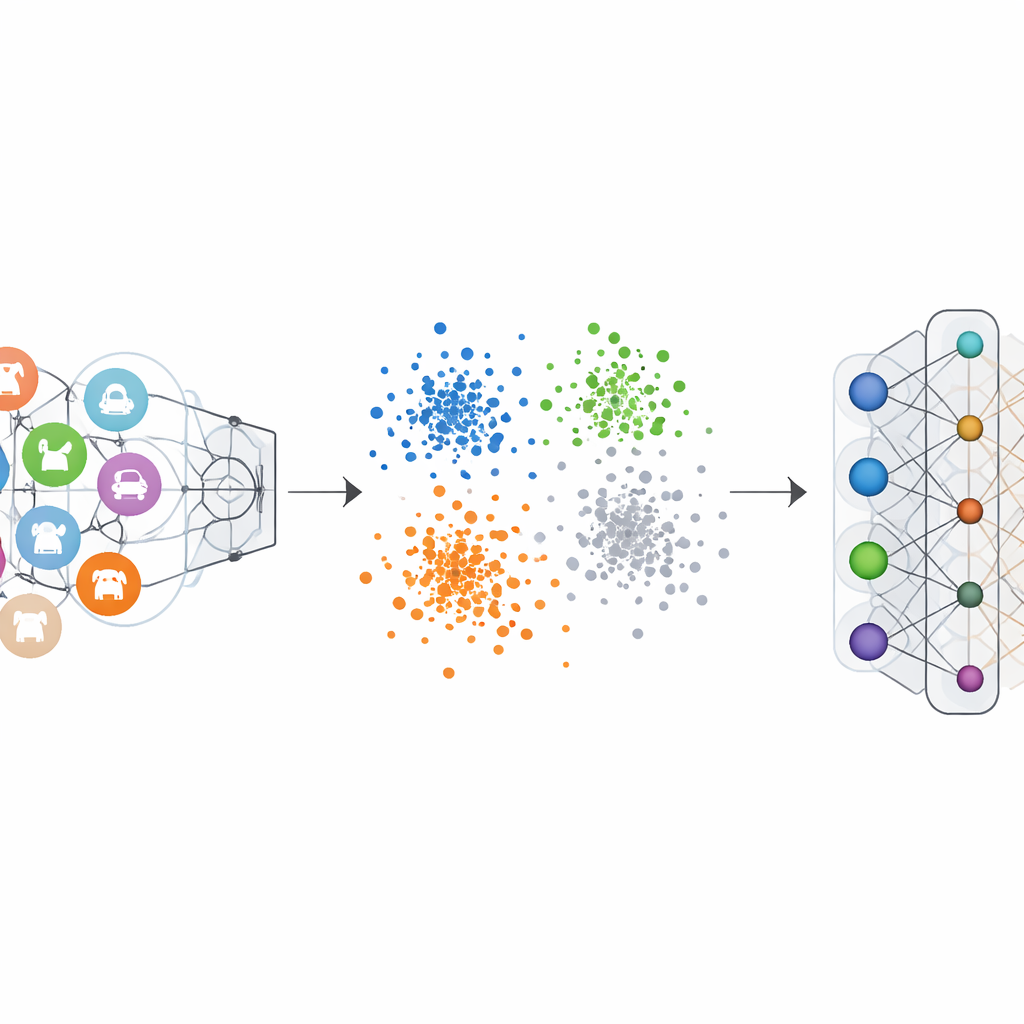
Prueba mediante numerosos tests en benchmarks de visión
Los autores probaron su marco en varios conjuntos de datos de imágenes bien conocidos, incluidos dígitos manuscritos, números de casas en vistas de calle, imágenes de ropa y fotos coloridas de objetos, usando una variedad de arquitecturas neuronales populares. Tanto en escenarios de olvido de clase única como de varias clases, el método redujo la precisión en las clases olvidadas casi a cero, haciendo que el modelo fuera incapaz de reconocerlas. Crucialmente, la precisión en las clases retenidas cayó como mucho unos pocos puntos porcentuales y, en algunos casos, incluso mejoró ligeramente. Las comparaciones con métodos de olvido líderes mostraron que este nuevo enfoque logró un olvido más fuerte con menos daño al rendimiento restante, todo ello necesitando solo un pequeño conjunto de ejemplos de las clases a olvidar y evitando cálculos pesados.
Qué significa esto para la IA cotidiana
En términos sencillos, este trabajo muestra que es posible dotar a las redes neuronales de una “borradora de memoria” controlada para tipos específicos de datos. Al cambiar de forma inteligente cómo se usan las etiquetas durante una breve etapa de reentrenamiento y al enmascarar pesos de decisión dirigidos, el marco NHLE–CWM hace que la representación de la categoría olvidada por el modelo sea tanto borrosa como inactiva. Para usuarios y reguladores, ello significa un camino más realista hacia la aplicación del derecho al olvido sin desechar modelos valiosos. Para los profesionales, ofrece una herramienta escalable y con bajo coste computacional para eliminar clases sesgadas, obsoletas o sensibles, manteniendo intacto el resto del sistema.
Cita: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Palabras clave: olvido automático de máquinas, privacidad de datos, aprendizaje profundo, clasificación de imágenes, olvido del modelo