Clear Sky Science · de
Feature-ununterscheidbares maschinelles Vergessen durch Negative-Hot-Label-Codierung und Klassengewicht-Maskierung
Warum es wichtig ist, Maschinen das Vergessen beizubringen
Moderne Anwendungen – von Foto-Tags bis zu medizinischer Bildanalyse – basieren auf leistungsfähigen Bilderkennungssystemen, die auf riesigen Datensätzen trainiert wurden. Aber was passiert, wenn jemand verlangt, seine Daten zu löschen, oder ein Datensatz als voreingenommen oder unsicher erkannt wird? Heutige neuronale Netze haben keinen einfachen „Löschen“-Knopf. Dieses Paper stellt eine praktikable Methode vor, ein trainiertes Modell so zu veranlassen, bestimmte Datenkategorien „zu vergessen“, während seine Fähigkeiten bei allem anderen weitgehend erhalten bleiben.
Wenn Daten gelöscht werden müssen, nicht nur ignoriert
Gesetze wie die europäische Datenschutz-Grundverordnung gewähren das „Recht auf Vergessenwerden“, was bedeutet, dass Organisationen möglicherweise den Einfluss bestimmter Daten aus ihren Modellen entfernen müssen, nicht nur die Dateien nicht mehr speichern. Ein großes neuronales Netz nach jedem solchen Vorfall komplett neu zu trainieren ist langsam, teuer und oft unmöglich, weil die Originaldaten nicht mehr vollständig verfügbar sind. Bestehende Methoden des „maschinellen Vergessens“ können helfen, erfordern aber häufig Zugriff auf den vollständigen Trainingssatz, aufwändige mathematische Berechnungen oder schädigen die Leistung auf den verbleibenden Daten merklich. Die Autoren wollen einen Ansatz entwickeln, der gezielt, effizient und schonend für das nützliche Wissen des Modells ist.
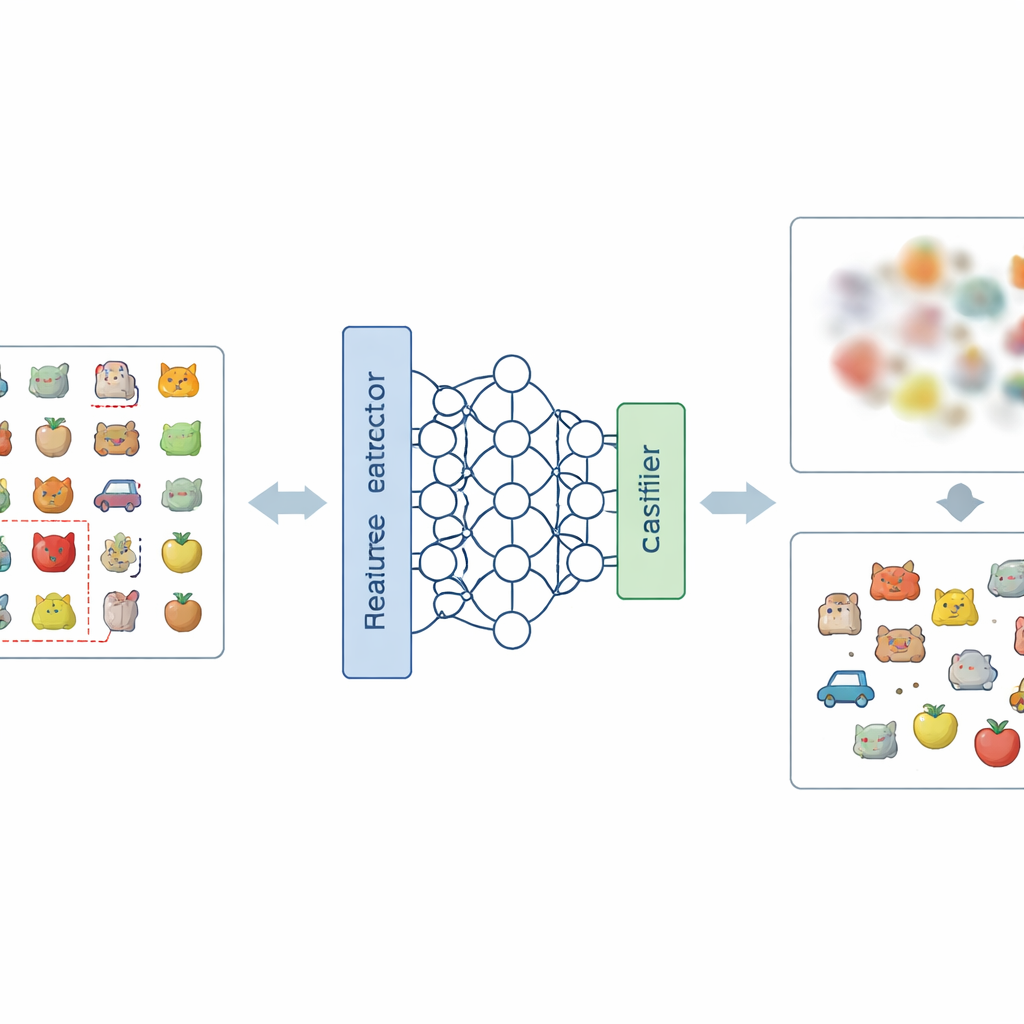
Ein neues Rezept zum Verwischen unerwünschter Erinnerungen
Die Kernidee des Papers greift das Problem auf zwei Ebenen an: wie das Netzwerk Bilder intern repräsentiert und wie es endgültige Entscheidungen trifft. Auf der Repräsentationsebene führen die Autoren eine neue Art der Label-Codierung ein, genannt Negative-Hot Label Encoding. Statt die zu vergessende Kategorie zu verstärken, behandelt dieses Schema sie nahezu wie eine „Anti-Klasse“. Während einer kurzen Feinabstimmungsphase, in der nur eine kleine Handvoll Bilder der zu entfernenden Kategorie verwendet wird, wird das Netzwerk so beeinflusst, dass seine interne Beschreibung dieser Bilder weniger unterscheidbar und stärker mit den anderen Klassen vermischt wird. Auf Entscheidungsebene fügen sie die Klassengewicht-Maskierung hinzu, die selektiv die finalen Verbindungen des Modells abschwächt, die mit der zu vergessenden Kategorie assoziiert sind, wodurch ihr direkter Einfluss auf die Ausgabe reduziert wird.
Wie negative Labels eine Kategorie schwächen
Gewöhnliche Bildklassifizierer werden mit „One-Hot“-Labels trainiert: die korrekte Klasse wird betont, die anderen auf null gesetzt. Das treibt das Netzwerk dazu, für jede Kategorie klare Grenzen zu schaffen. Das Negative-Hot Label Encoding kehrt diese Logik für die zu löschende Kategorie um. Während des Unlearnings erhält diese Kategorie einen negativen Beitrag, während die übrigen Klassen kleine positive Beiträge bekommen. Mathematisch kehrt und verstärkt dies die Gradientenupdates, die die vergessene Klasse einst so unterscheidbar gemacht haben, und drückt ihre Merkmale allmählich wieder in die Masse. Visualisierungen des internen Merkmalsraums des Netzwerks zeigen, dass unter diesem Schema Punkte der vergessenen Klasse aufhören, einen dichten, separaten Cluster zu bilden, und stattdessen in die umgebende Wolke anderer Klassen übergehen.
Entscheidungslinks kappen und zugleich das Verbleibende schützen
Allein das Verändern von Labels reicht nicht aus, weil Anpassungen in den frühen Netzwerkschichten unbeabsichtigt stören können, wie andere Kategorien erkannt werden. Die Klassengewicht-Maskierung bietet eine direkte und kostengünstige Absicherung. Nach der kurzen Feinabstimmung mit negativen Labels identifiziert und dämpft die Methode die Modellkomponenten, die in der finalen Klassifikationsschicht am stärksten mit der vergessenen Kategorie verknüpft sind. Dieser Schritt reduziert deutlich die Fähigkeit des Modells, diese Kategorie auszuwählen, ohne komplexe globale Berechnungen oder den Zugriff auf alle Trainingsbeispiele zu erfordern. Zusammen bilden die beiden Schritte das NHLE–CWM-Framework: das erste verwischt die unerwünschte Erinnerung im Merkmalsraum, das zweite kappt ihren verbleibenden Einfluss auf Entscheidungen, und beide werden nur mit einer kleinen Anzahl von Beispielbildern aus den zu entfernenden Klassen abgestimmt.
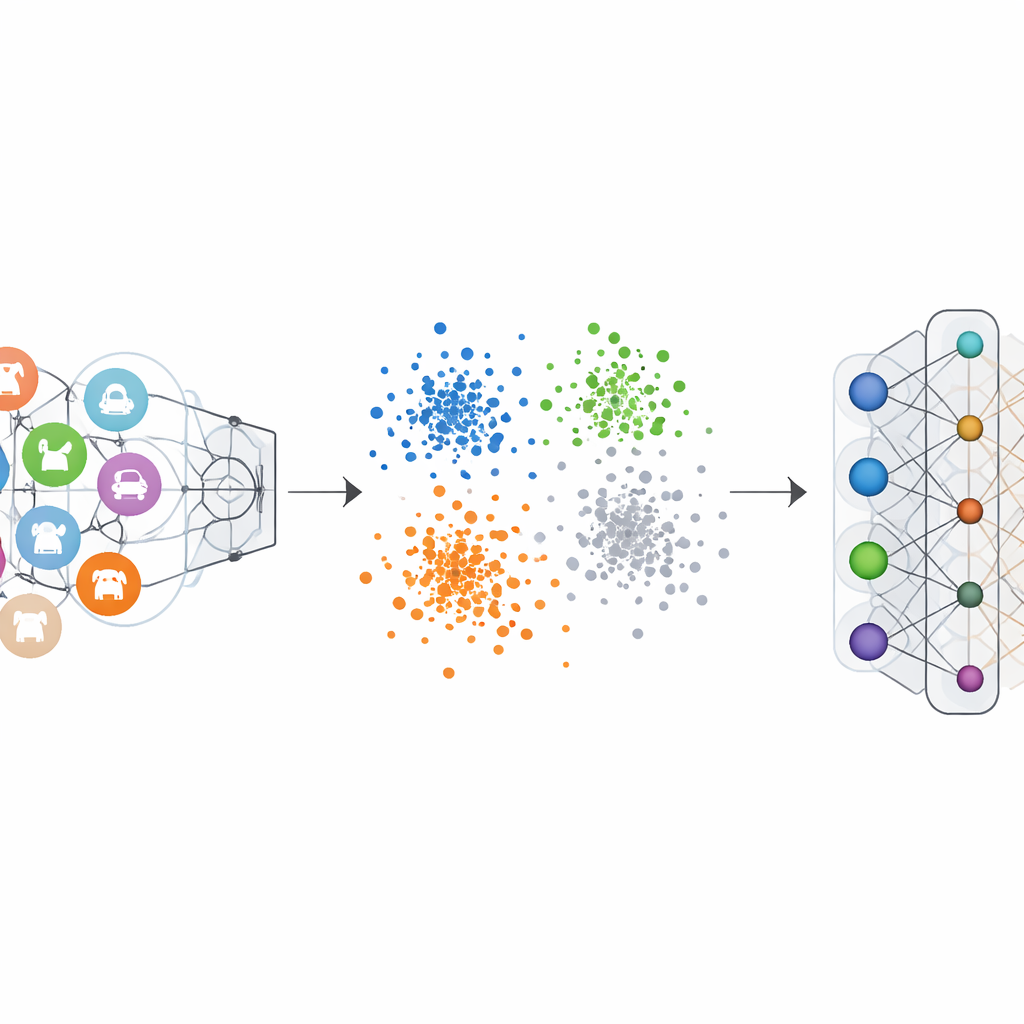
Beleg durch zahlreiche Tests auf Vision-Benchmarks
Die Autoren testeten ihr Framework auf mehreren bekannten Bilddatensätzen, darunter handgeschriebene Ziffern, Straßenansicht-Hausnummern, Bekleidungsbilder und farbenfrohe Objektfotos, unter Verwendung verschiedener gängiger neuronaler Netzwerkarchitekturen. Sowohl in Szenarien mit dem Vergessen einzelner Klassen als auch mehrerer Klassen brachte die Methode die Genauigkeit für die vergessenen Klassen nahezu auf null und machte das Modell effektiv unfähig, sie zu erkennen. Wichtig ist, dass die Genauigkeit auf den verbleibenden Klassen höchstens um wenige Prozentpunkte sank und in einigen Fällen sogar leicht zunahm. Vergleiche mit führenden Unlearning-Verfahren zeigten, dass dieser neue Ansatz stärkeres Vergessen bei geringerem Schaden für die verbleibende Leistung erreichte, und das alles bei nur einem kleinen Satz von Beispielen aus den zu vergessenden Klassen und ohne aufwändige Berechnungen.
Was das für die alltägliche KI bedeutet
Einfach gesagt zeigt diese Arbeit, dass es möglich ist, neuronale Netze nachträglich mit einem kontrollierten „Gedächtnislöscher“ für bestimmte Datenarten auszustatten. Indem man klug verändert, wie Labels während eines kurzen Retrainings verwendet werden, und gezielt Entscheidungsgewichte maskiert, macht das NHLE–CWM-Framework die Sicht des Modells auf die vergessene Kategorie sowohl unscharf als auch inaktiv. Für Nutzer und Regulierungsbehörden bedeutet das einen realistischeren Weg, das Recht auf Vergessenwerden durchzusetzen, ohne wertvolle Modelle wegwerfen zu müssen. Für Praktiker bietet es ein skalierbares und rechenleichtes Werkzeug, um voreingenommene, veraltete oder sensible Klassen zu entfernen und zugleich den Rest des Systems intakt zu halten.
Zitation: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Schlüsselwörter: maschinelles Vergessen, Datenschutz, Deep Learning, Bildklassifikation, Modellvergessen