Clear Sky Science · sv
Maskinellt oförmåga att skilja funktioner via negativ-hot etikettkodning och klassviktmaskning
Varför det spelar roll att lära maskiner att glömma
Moderna appar — från fotomärkning till medicinsk bildanalys — förlitar sig på kraftfulla bildigenkänningssystem tränade på stora datamängder. Men vad händer när någon begär att deras data ska tas bort, eller när en datamängd visar sig vara partisk eller osäker? Dagens neurala nätverk har ingen enkel ”ta bort”-knapp. Denna artikel presenterar ett praktiskt sätt att få en tränad modell att ”glömma” specifika kategorier av data, samtidigt som modellens kunskaper i övrigt i stor utsträckning bevaras.
När data måste raderas, inte bara ignoreras
Lagar som Europas allmänna dataskyddsförordning ger människor en ”rätt att bli glömda”, vilket innebär att organisationer kan behöva ta bort inflytandet från vissa data i sina modeller, inte bara sluta lagra filerna. Att träna om ett stort neuralt nätverk från början varje gång detta krävs är långsamt, kostsamt och ibland omöjligt eftersom originaldata inte längre är fullt tillgängliga. Befintliga metoder för ”maskinell utglömning” kan hjälpa, men de kräver ofta tillgång till hela träningsuppsättningen, involverar tunga matematiska beräkningar eller skadar modellens prestanda på återstående data märkbart. Författarna ville ta fram en metod som är riktad, effektiv och skonsam mot modellens användbara kunskap.
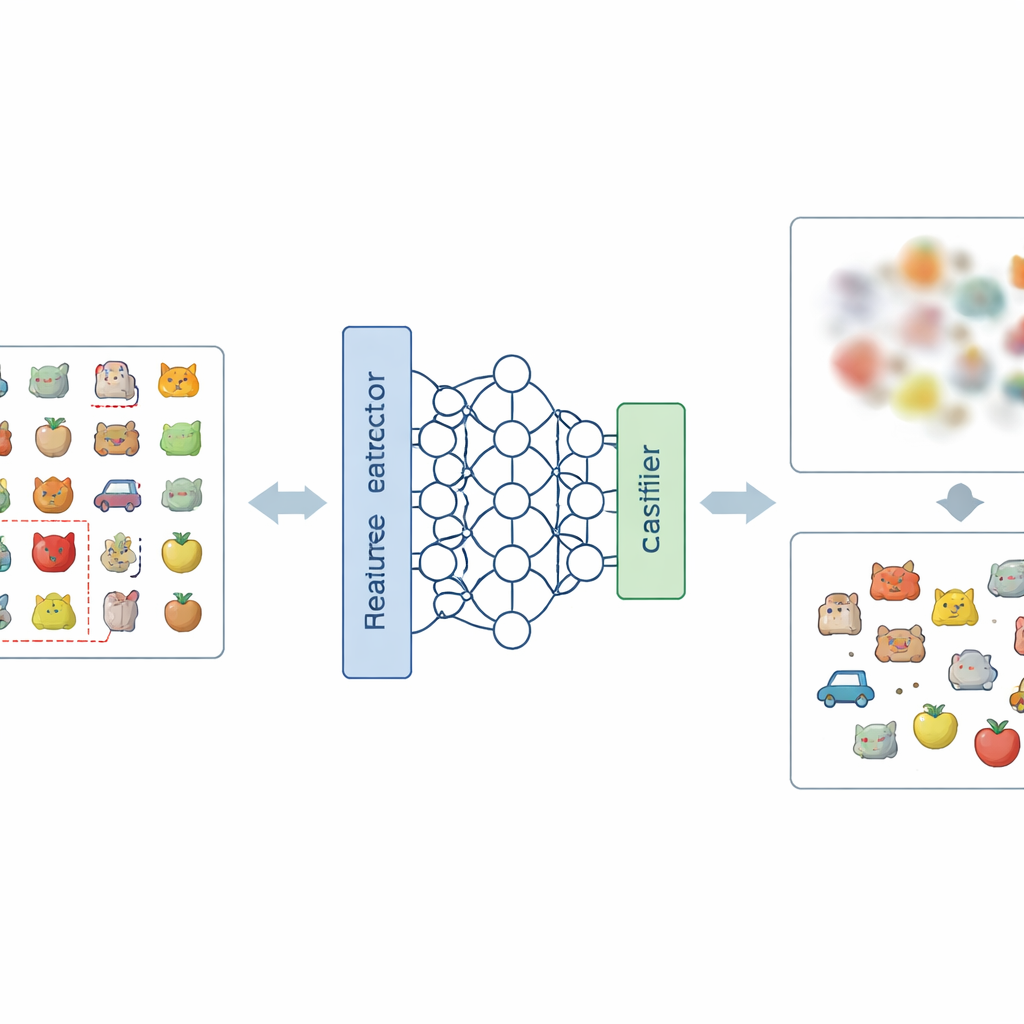
En ny metod för att sudda ut oönskade minnen
Huvudidén i artikeln är att angripa problemet på två nivåer: hur nätverket representerar bilder internt och hur det fattar slutgiltiga beslut. På representationsnivå introducerar författarna ett nytt sätt att koda etiketter, kallat Negative-Hot Label Encoding. Istället för att förstärka den kategori som ska glömmas behandlar detta schema den nästan som en ”antiklasse”. Under en kort finjusteringsfas, med endast ett litet antal bilder från den kategori som ska tas bort, skjuts nätverket så att dess interna beskrivning av dessa bilder blir mindre distinkt och mer sammanblandad med de andra klasserna. På beslutsnivå lägger de till Class Weight Masking, som selektivt försvagar modellens slutliga kopplingar associerade med den kategori som ska glömmas och därigenom skär dess direkta inflytande på utdata.
Hur negativa etiketter försvagar en kategori
Vanliga bildklassificerare tränas med ”one-hot”-etiketter: den korrekta klassen markeras starkt och de andra sätts till noll. Det driver nätverket att skapa en tydlig gräns för varje kategori. Negative-Hot Label Encoding vänder denna logik för den kategori vi vill radera. Under utglömningen ges den kategorin ett negativt bidrag, medan återstående kategorier får små positiva bidrag. Matematiskt omvänder och förstärker detta gradientuppdateringar som en gång gjorde den bortglömda klassen så distinkt, och skjuter gradvis dess features tillbaka mot mängden. Visualiseringar av nätverkets interna featurespace visar att punkter från den bortglömda klassen slutar bilda en tät, separat klunga och istället blandas in i det omgivande molnet av andra klasser.
Skära beslutslänkar samtidigt som det som återstår skyddas
Att bara ändra etiketter räcker inte, eftersom justeringar i nätverkets tidiga lager oavsiktligt kan störa hur det känner igen andra kategorier. Class Weight Masking ger en direkt och billig skyddsmekanism. Efter den korta finjusteringen med negativa etiketter identifierar och dämpar metoden de modellkomponenter i det slutliga klassificeringslagret som mest kopplats till den bortglömda kategorin. Detta steg minskar kraftigt modellens förmåga att plocka ut den kategorin, utan att kräva komplexa globala beräkningar eller tillgång till alla träningsexempel. Tillsammans bildar de två stegen NHLE–CWM-ramverket: det första suddar ut det oönskade minnet i featurespace, det andra kapar dess kvarvarande inflytande på besluten, och båda justeras med endast ett litet antal exempelbilder från klasserna som ska tas bort.
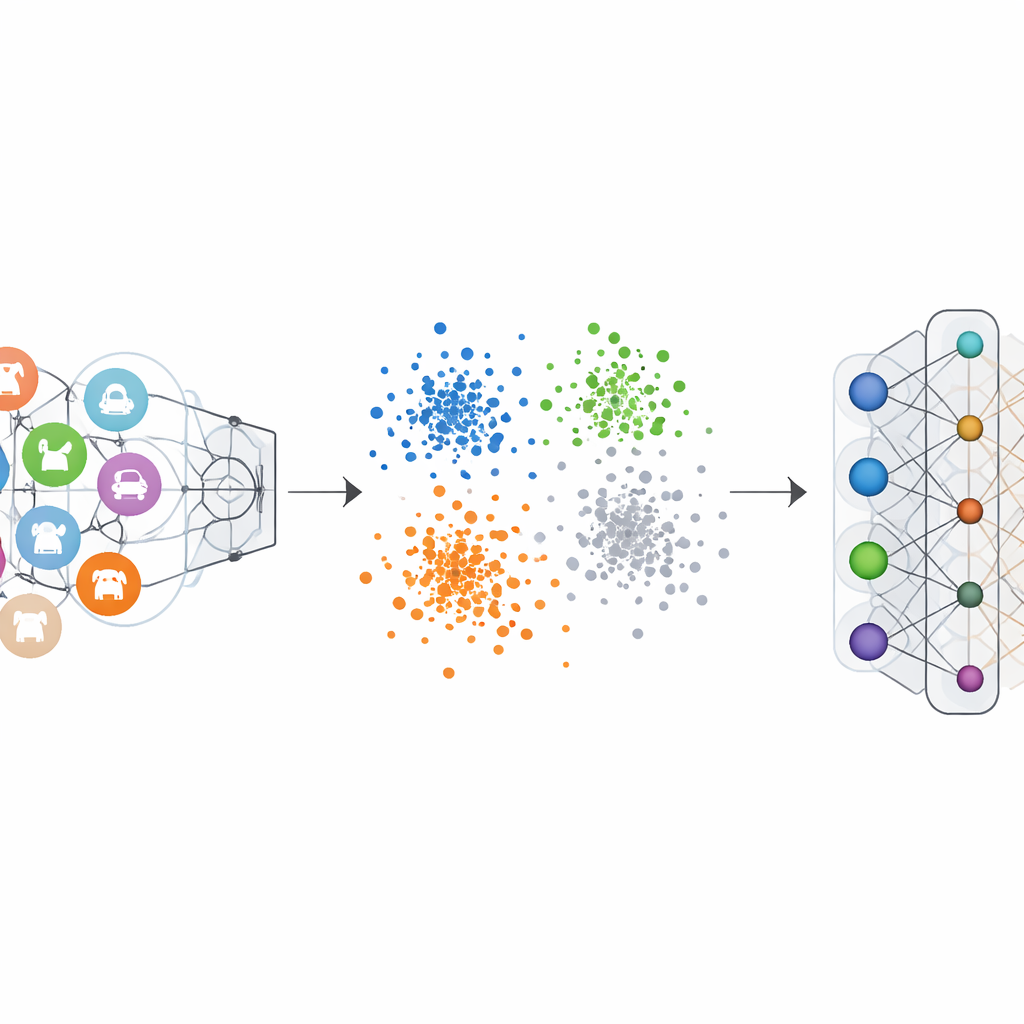
Bevis från många tester på visuella benchmarkar
Författarna testade sitt ramverk på flera välkända bilddatamängder, inklusive handskrivna siffror, gatubyggnadsnummer, klädnadsbilder och färgrika objektfoton, med en rad populära neurala nätverksarkitekturer. I både enkla och flerkategoriska utglömningsscenarier pressade metoden noggrannheten på de bortglömda klasserna nästan till noll, vilket effektivt gjorde modellen oförmögen att känna igen dem. Avgörande var att noggrannheten på de kvarvarande klasserna sjönk med högst några procentenheter, och i vissa fall förbättrades den till och med något. Jämförelser med ledande utglömningsmetoder visade att detta nya tillvägagångssätt uppnådde starkare utglömning med mindre skada på återstående prestanda, samtidigt som det krävde endast en liten uppsättning exempel från klasserna att glömma och undvek tunga beräkningar.
Vad detta betyder för vardaglig AI
Enkelt uttryckt visar detta arbete att det är möjligt att eftermontera neurala nätverk med en kontrollerad ”minnesraderare” för specifika typer av data. Genom att listigt ändra hur etiketter används under ett kort reträningssteg och genom att maskera riktade beslutsvikter gör NHLE–CWM-ramverket modellens bild av den bortglömda kategorin både suddig och inaktiv. För användare och tillsynsmyndigheter innebär det en mer realistisk väg mot att tillämpa rätten att bli glömd utan att kassera värdefulla modeller. För praktiker erbjuder det ett skalbart och beräkningsmässigt lätt verktyg för att ta bort partiska, föråldrade eller känsliga klasser samtidigt som resten av systemet förblir intakt.
Citering: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Nyckelord: maskinavlärning, datasekretess, djuplärande, bildklassificering, modellglömska