Clear Sky Science · pl
Usuwanie pamięci maszynowej nieodróżnialne cechowo za pomocą negatywno‑gorącego kodowania etykiet i maskowania wag klas
Dlaczego warto nauczyć maszyny zapominać
Nowoczesne aplikacje — od tagowania zdjęć po analizę obrazów medycznych — opierają się na potężnych systemach rozpoznawania obrazów trenowanych na ogromnych zbiorach danych. Co jednak się dzieje, gdy ktoś zażąda usunięcia swoich danych, albo gdy zbiór danych okaże się stronniczy lub niebezpieczny? Dzisiejsze sieci neuronowe nie mają prostego przycisku „usuń”. Artykuł wprowadza praktyczny sposób, by sprawić, że wytrenowany model „zapomni” określone kategorie danych, przy zachowaniu większości swoich umiejętności w pozostałych zadaniach.
Kiedy dane trzeba wykasować, a nie tylko zignorować
Przepisy takie jak europejskie Rozporządzenie o Ochronie Danych Osobowych (RODO) przyznają ludziom „prawo do bycia zapomnianym”, co oznacza, że organizacje mogą być zobowiązane do usunięcia wpływu pewnych danych z ich modeli, a nie tylko do zaprzestania przechowywania plików. Ponowne trenowanie dużej sieci neuronowej od zera za każdym razem jest powolne, kosztowne i czasem niemożliwe, ponieważ oryginalne dane nie są już w pełni dostępne. Istniejące metody „unlearningu” mogą pomóc, lecz często wymagają dostępu do pełnego zestawu treningowego, wiążą się z ciężkimi obliczeniami matematycznymi lub wyraźnie pogarszają wydajność na pozostałych danych. Autorzy postawili sobie za cel zaprojektowanie podejścia ukierunkowanego, wydajnego i łagodnego dla użytecznej wiedzy modelu.
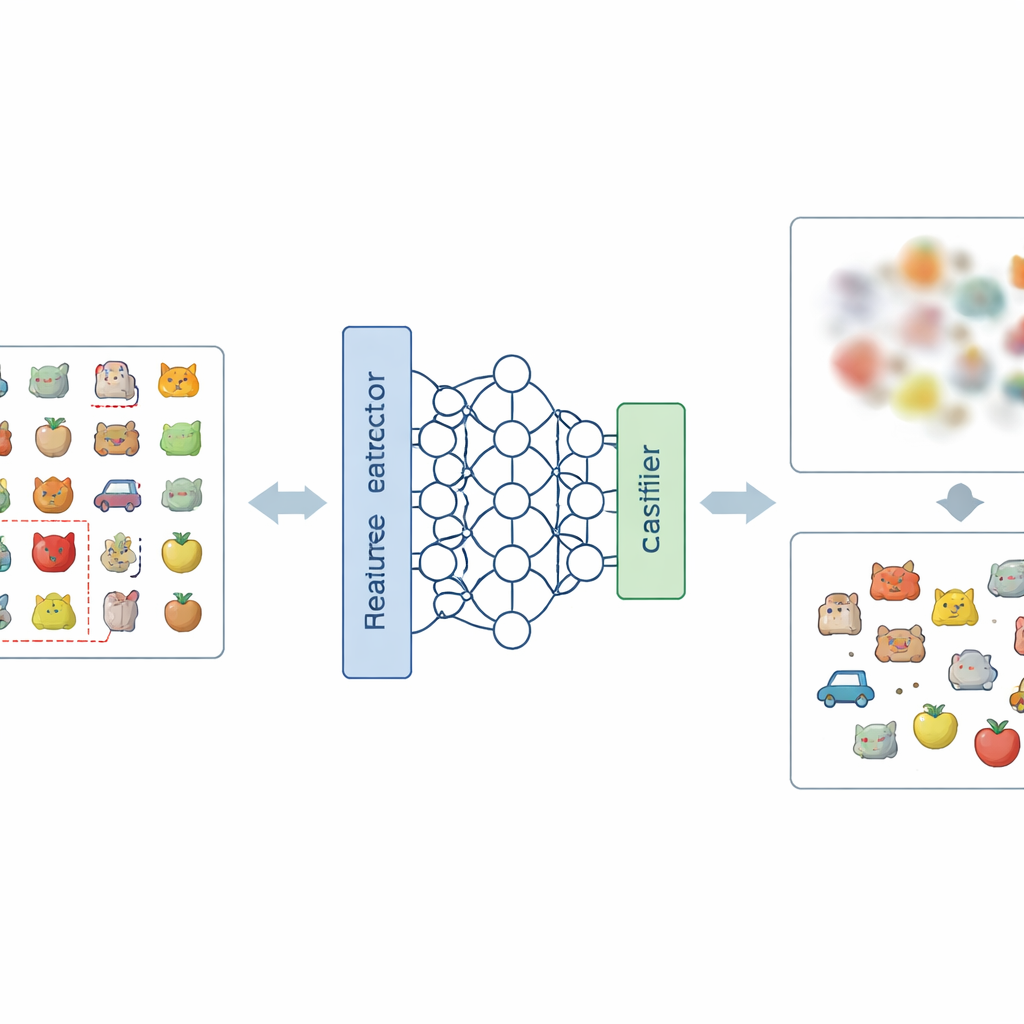
Nowy przepis na rozmycie niechcianych wspomnień
Główny pomysł pracy to atakowanie problemu na dwóch poziomach: jak sieć reprezentuje obrazy wewnętrznie oraz jak podejmuje ostateczne decyzje. Na poziomie reprezentacji autorzy wprowadzają nowy sposób kodowania etykiet, zwany Negatywno‑Gorącym Kodowaniem Etykiet (Negative‑Hot Label Encoding). Zamiast wzmacniać kategorię, którą należy zapomnieć, schemat traktuje ją niemal jak „antyklasę”. W krótkiej fazie dopracowania, używając tylko niewielkiej liczby obrazów z kategorii do usunięcia, sieć jest subtelnie przesuwana tak, by jej wewnętrzny opis tych obrazów stał się mniej wyróżniający się i bardziej wymieszany z innymi klasami. Na poziomie decyzji dodają Maskowanie Wag Klas (Class Weight Masking), które selektywnie osłabia końcowe połączenia modelu związane z kategorią do zapomnienia, ograniczając jej bezpośredni wpływ na wynik.
Jak negatywne etykiety osłabiają kategorię
Zwykłe klasyfikatory obrazów są trenowane z etykietami „one‑hot”: poprawna klasa jest wyeksponowana, a pozostałe ustawione na zero. Skłania to sieć do wydzielenia wyraźnej granicy dla każdej kategorii. Negatywno‑Gorące Kodowanie Etykiet odwraca tę logikę dla kategorii, którą chcemy wymazać. Podczas unlearningu ta kategoria otrzymuje negatywny wkład, podczas gdy pozostałe kategorie dostają małe dodatnie wkłady. Matematycznie odwraca to i wzmacnia aktualizacje gradientowe, które kiedyś uczyniły zapominaną klasę tak wyróżniającą się, stopniowo popychając jej cechy z powrotem w kierunku tłumu. Wizualizacje wewnętrznej przestrzeni cech sieci pokazują, że pod tym schematem punkty z zapomnianej klasy przestają tworzyć ciasny, oddzielny klaster i zamiast tego stapiają się z otaczającą chmurą innych klas.
Przecięcie powiązań decyzyjnych przy ochronie tego, co pozostaje
Zmiana etykiet sama w sobie nie wystarcza, ponieważ modyfikacja wczesnych warstw sieci może niezamierzenie zakłócić rozpoznawanie innych kategorii. Maskowanie Wag Klas zapewnia bezpośrednie i niedrogie zabezpieczenie. Po krótkim dopracowaniu z użyciem negatywnych etykiet metoda identyfikuje i wycisza komponenty modelu najsilniej powiązane z zapomnianą kategorią w końcowej warstwie klasyfikatora. Ten krok ostro ogranicza zdolność modelu do rozróżniania tej kategorii, bez potrzeby wykonywania złożonych globalnych obliczeń czy dostępu do wszystkich przykładów treningowych. Razem te dwa kroki tworzą ramy NHLE–CWM: pierwszy rozmywa niechciane wspomnienie w przestrzeni cech, drugi odcina jego pozostały wpływ na decyzje, a oba są dostrajane przy użyciu tylko niewielkiej liczby przykładowych obrazów z klas do usunięcia.
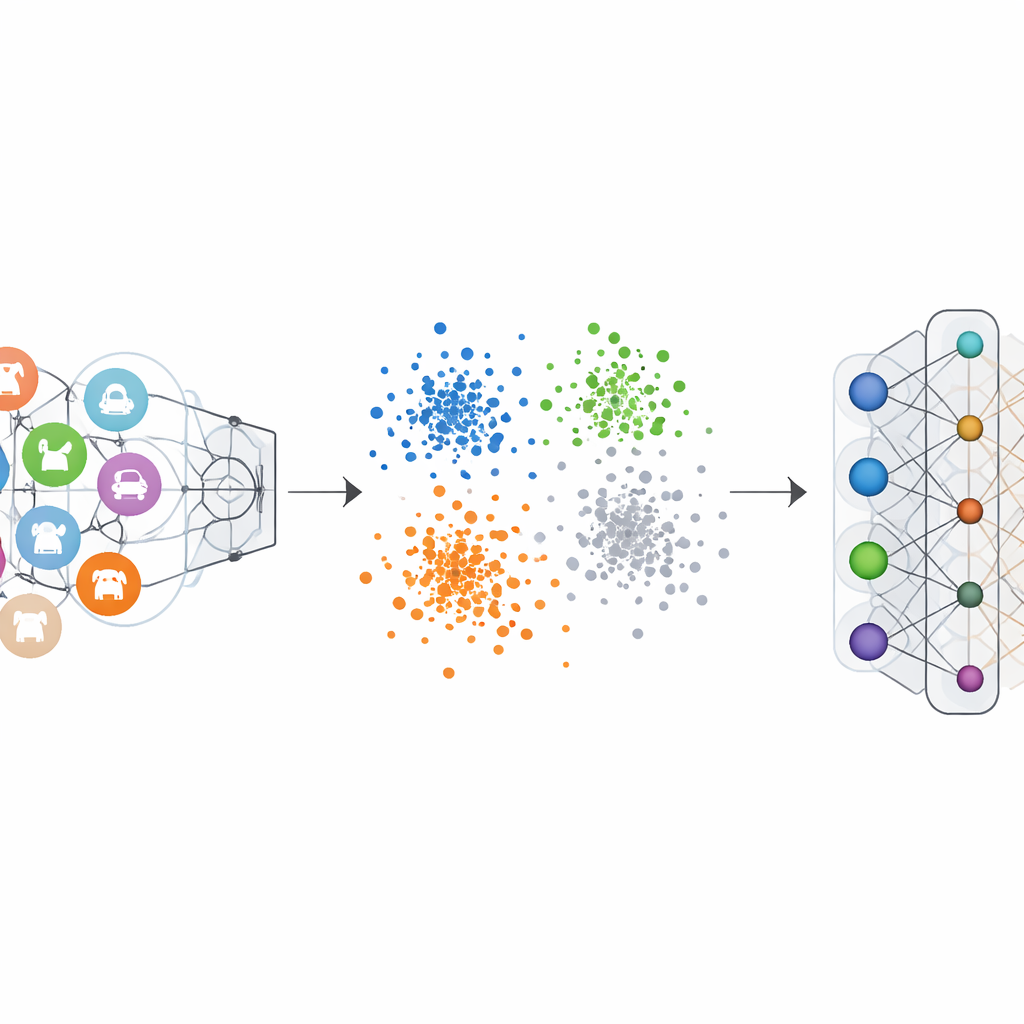
Dowód na podstawie wielu testów na benchmarkach wizji
Autorzy przetestowali swój framework na kilku znanych zbiorach obrazów, w tym na ręcznie pisanych cyfrach, numerach domów ze zdjęć ulic, obrazach odzieży i kolorowych zdjęciach obiektów, używając różnych popularnych architektur sieci neuronowych. Zarówno w scenariuszach zapominania pojedynczych klas, jak i wielu klas, metoda zredukowała dokładność dla zapomnianych klas niemal do zera, skutecznie uniemożliwiając modelowi ich rozpoznanie. Co kluczowe, dokładność dla zachowanych klas spadła maksymalnie o kilka punktów procentowych, a w niektórych przypadkach nawet nieznacznie się poprawiła. Porównania z wiodącymi metodami unlearningu wykazały, że nowe podejście osiągnęło silniejsze zapominanie przy mniejszym uszczerbku dla pozostałej wydajności, wszystko to przy użyciu tylko niewielkiego zestawu przykładów z klas do zapomnienia i bez ciężkich obliczeń.
Co to oznacza dla codziennej sztucznej inteligencji
Mówiąc prosto, praca pokazuje, że możliwe jest doposażenie sieci neuronowych w kontrolowany „gumkownik pamięci” dla określonych rodzajów danych. Poprzez sprytne zmienienie sposobu użycia etykiet podczas krótkiego kroku ponownego trenowania i przez maskowanie ukierunkowanych wag decyzyjnych, ramy NHLE–CWM sprawiają, że widok modelu na zapomnianą kategorię staje się zarówno rozmyty, jak i nieaktywny. Dla użytkowników i regulatorów oznacza to bardziej realistyczną ścieżkę do egzekwowania prawa do bycia zapomnianym bez konieczności odrzucania wartościowych modeli. Dla praktyków oferuje skalowalne i obliczeniowo lekkie narzędzie do usuwania stronniczych, przestarzałych lub wrażliwych klas przy zachowaniu reszty systemu nienaruszonej.
Cytowanie: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Słowa kluczowe: unlearning maszynowy, ochrona danych, uczenie głębokie, klasyfikacja obrazów, zapominanie modelu