Clear Sky Science · it
Disimparare macchine in modo indistinguibile tramite codifica di etichette negative-hot e mascheramento dei pesi di classe
Perché insegnare alle macchine a dimenticare è importante
Le applicazioni moderne — dal tagging fotografico all’analisi di immagini mediche — si basano su potenti sistemi di riconoscimento delle immagini addestrati su enormi insiemi di dati. Ma cosa succede quando qualcuno chiede che i propri dati vengano rimossi, o quando un dataset si rivela distorto o non sicuro? Le reti neurali odierne non dispongono di un semplice pulsante “elimina”. Questo articolo introduce un metodo pratico per far “dimenticare” a un modello addestrato categorie specifiche di dati, preservando in larga misura le sue abilità sul resto.
Quando i dati devono essere cancellati, non solo ignorati
Leggi come il Regolamento generale sulla protezione dei dati dell’Unione Europea riconoscono alle persone il “diritto all’oblio”, il che significa che le organizzazioni potrebbero dover rimuovere l’influenza di certi dati dai loro modelli, non limitarsi a non conservare più i file. Riaddestrare da zero una grande rete neurale ogni volta è lento, costoso e talvolta impossibile perché i dati originali non sono più completamente disponibili. I metodi esistenti di “machine unlearning” possono aiutare, ma spesso richiedono l’accesso all’intero set di addestramento, implicano complesse operazioni matematiche o danneggiano visibilmente le prestazioni sui dati rimanenti. Gli autori si sono proposti di progettare un approccio mirato, efficiente e rispettoso delle conoscenze utili del modello.
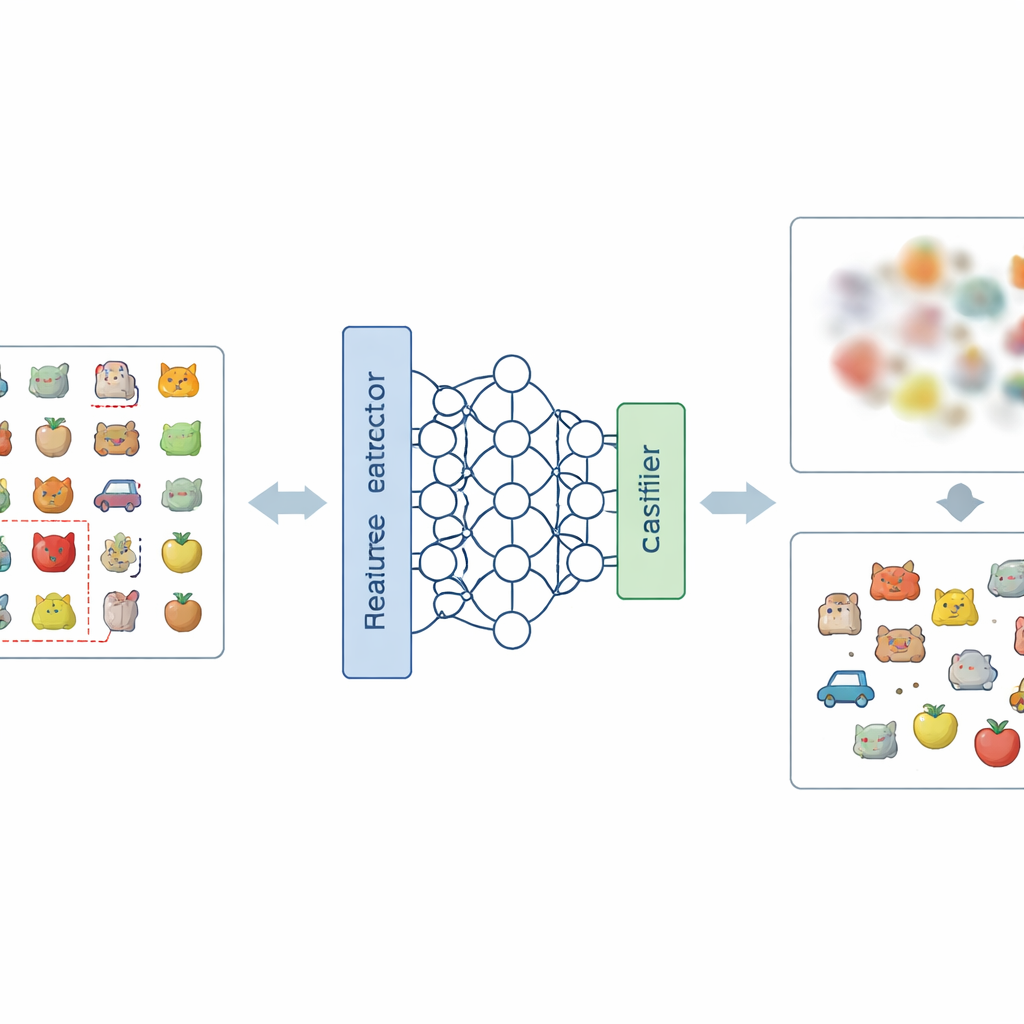
Una nuova ricetta per sfocare i ricordi indesiderati
L’idea centrale dell’articolo è affrontare il problema su due livelli: come la rete rappresenta le immagini internamente e come prende le decisioni finali. A livello di rappresentazione, gli autori introducono un nuovo modo di codificare le etichette, chiamato Codifica di Etichette Negative-Hot. Invece di rinforzare la categoria che deve essere dimenticata, questo schema la tratta quasi come una “anti-classe”. Durante una breve fase di fine-tuning, usando solo una manciata di immagini della categoria da rimuovere, la rete viene spinta affinché la sua descrizione interna di quelle immagini diventi meno distintiva e più confusa con le altre classi. A livello decisionale, aggiungono il Mascheramento dei Pesi di Classe, che indebolisce selettivamente le connessioni finali del modello associate alla categoria da dimenticare, riducendone l’influenza diretta sull’output.
Come le etichette negative indeboliscono una categoria
I normali classificatori di immagini sono addestrati con etichette “one-hot”: la classe corretta viene enfatizzata e le altre sono impostate a zero. Questo spinge la rete a ritagliare un confine chiaro per ogni categoria. La Codifica di Etichette Negative-Hot inverte questa logica per la categoria che vogliamo cancellare. Durante l’unlearning, quella categoria riceve un contributo negativo, mentre le categorie rimanenti ottengono piccoli contributi positivi. Matematicamente, questo inverte e amplifica gli aggiornamenti del gradiente che una volta rendevano la classe dimenticata così distintiva, spingendo gradualmente le sue caratteristiche verso la massa. Le visualizzazioni dello spazio delle feature interne mostrano che, con questo schema, i punti appartenenti alla classe dimenticata smettono di formare un ammasso compatto e separato e si mescolano alla nuvola circostante delle altre classi.
Tagliare i legami decisionali proteggendo il resto
Modificare solo le etichette non è sufficiente, perché aggiustare gli strati iniziali della rete può disturbare involontariamente il riconoscimento di altre categorie. Il Mascheramento dei Pesi di Classe fornisce una salvaguardia diretta ed economica. Dopo il breve fine-tuning con etichette negative, il metodo identifica e disattiva i componenti del modello più legati alla categoria dimenticata nello strato finale del classificatore. Questo passaggio riduce nettamente la capacità del modello di distinguere quella categoria, senza richiedere calcoli globali complessi o l’accesso a tutti gli esempi di addestramento. Insieme, i due passaggi formano il framework NHLE–CWM: il primo sfoca il ricordo indesiderato nello spazio delle feature, il secondo recide la sua influenza residua sulle decisioni, e entrambi sono tarati usando solo un piccolo numero di immagini campione delle classi da rimuovere.
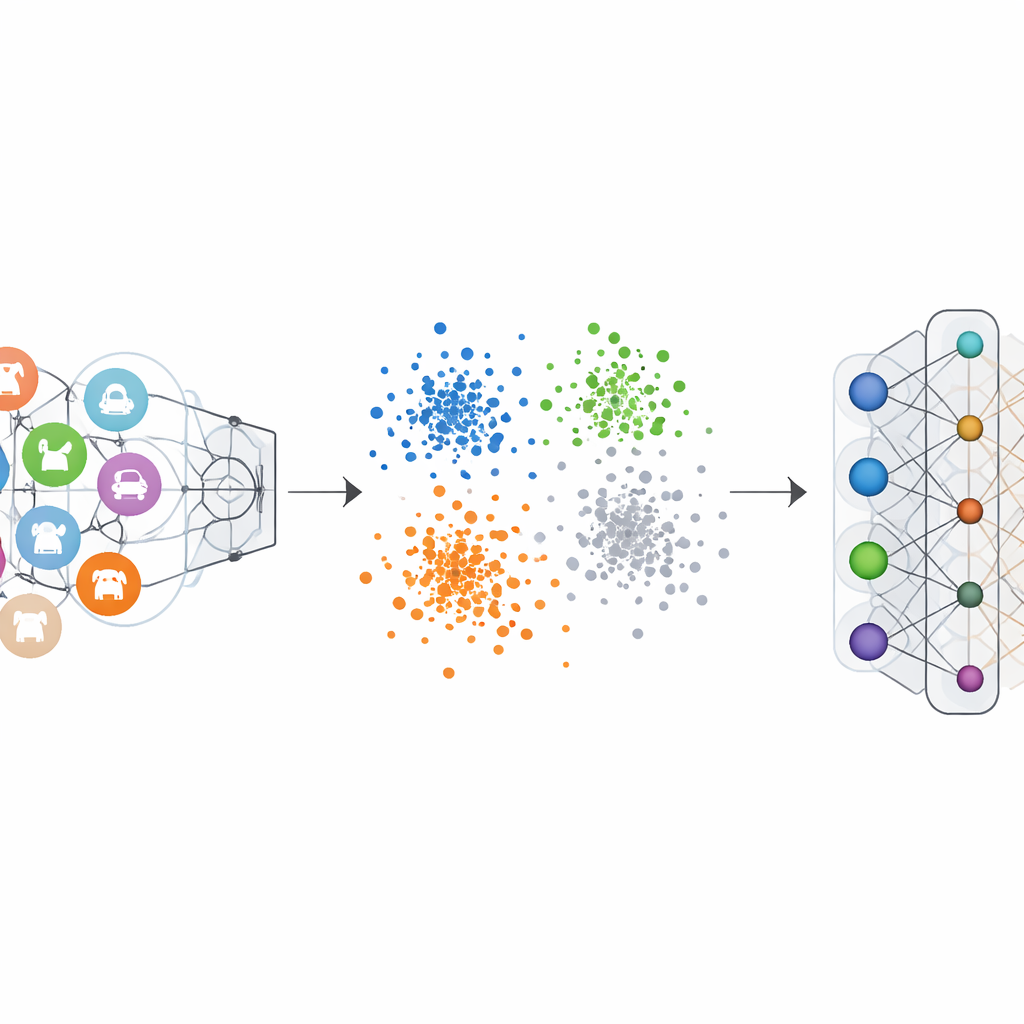
Prove da numerosi test su benchmark di visione
Gli autori hanno testato il loro framework su diversi noti dataset di immagini, incluse cifre scritte a mano, numeri civici ripresi dalla strada, immagini di abbigliamento e foto di oggetti colorati, utilizzando una varietà di architetture neurali popolari. Sia in scenari di dimenticanza di singole classi sia multi-classe, il metodo ha portato l’accuratezza sulle classi dimenticate a quasi zero, rendendo di fatto il modello incapace di riconoscerle. Crucialmente, l’accuratezza sulle classi mantenute è scesa al più di pochi punti percentuali e in alcuni casi è addirittura migliorata leggermente. I confronti con i principali metodi di unlearning hanno mostrato che questo nuovo approccio ottiene una dimenticanza più forte con minori danni alle prestazioni rimanenti, richiedendo al contempo solo un piccolo set di esempi delle classi da dimenticare ed evitando calcoli pesanti.
Cosa significa per l’IA di tutti i giorni
In termini semplici, questo lavoro dimostra che è possibile dotare le reti neurali di una “cancellazione della memoria” controllata per tipi specifici di dati. Cambiando in modo intelligente l’uso delle etichette durante un breve passo di riaddestramento e mascherando pesi decisionali mirati, il framework NHLE–CWM rende la rappresentazione della categoria dimenticata sia sfocata che inattiva. Per utenti e regolatori, ciò significa un percorso più realistico per applicare il diritto all’oblio senza scartare modelli preziosi. Per i professionisti, offre uno strumento scalabile e leggero dal punto di vista computazionale per rimuovere classi distorte, obsolete o sensibili mantenendo intatto il resto del sistema.
Citazione: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Parole chiave: disimparare macchine, privacy dei dati, deep learning, classificazione di immagini, dimenticanza del modello