Clear Sky Science · fr
Oubli machine indiscernable par caractéristiques via encodage d’étiquette négative-hot et masquage des poids de classe
Pourquoi il est important d’apprendre aux machines à oublier
Les applications modernes — du marquage de photos à l’analyse d’images médicales — reposent sur de puissants systèmes de reconnaissance d’images entraînés sur d’énormes jeux de données. Mais que se passe-t-il lorsqu’une personne demande la suppression de ses données, ou lorsqu’un jeu de données est jugé biaisé ou dangereux ? Les réseaux neuronaux d’aujourd’hui n’ont pas de bouton « supprimer » simple. Cet article présente une méthode pratique pour amener un modèle entraîné à « oublier » certaines catégories de données, tout en préservant pour l’essentiel ses compétences sur le reste.
Quand les données doivent être effacées, et pas seulement ignorées
Des lois comme le Règlement général sur la protection des données en Europe accordent aux personnes un « droit à l’oubli », ce qui peut contraindre les organisations à supprimer l’influence de certaines données de leurs modèles, et pas seulement à cesser de stocker les fichiers. Réentraîner un grand réseau neuronal depuis zéro à chaque demande est lent, coûteux et parfois impossible parce que les données originales ne sont plus entièrement disponibles. Les méthodes actuelles d’« unlearning » peuvent aider, mais elles exigent souvent l’accès à l’ensemble du jeu d’entraînement, impliquent des calculs mathématiques lourds ou détériorent nettement les performances sur les données restantes. Les auteurs se sont donné pour objectif de concevoir une approche ciblée, efficace et peu dommageable pour les connaissances utiles du modèle.
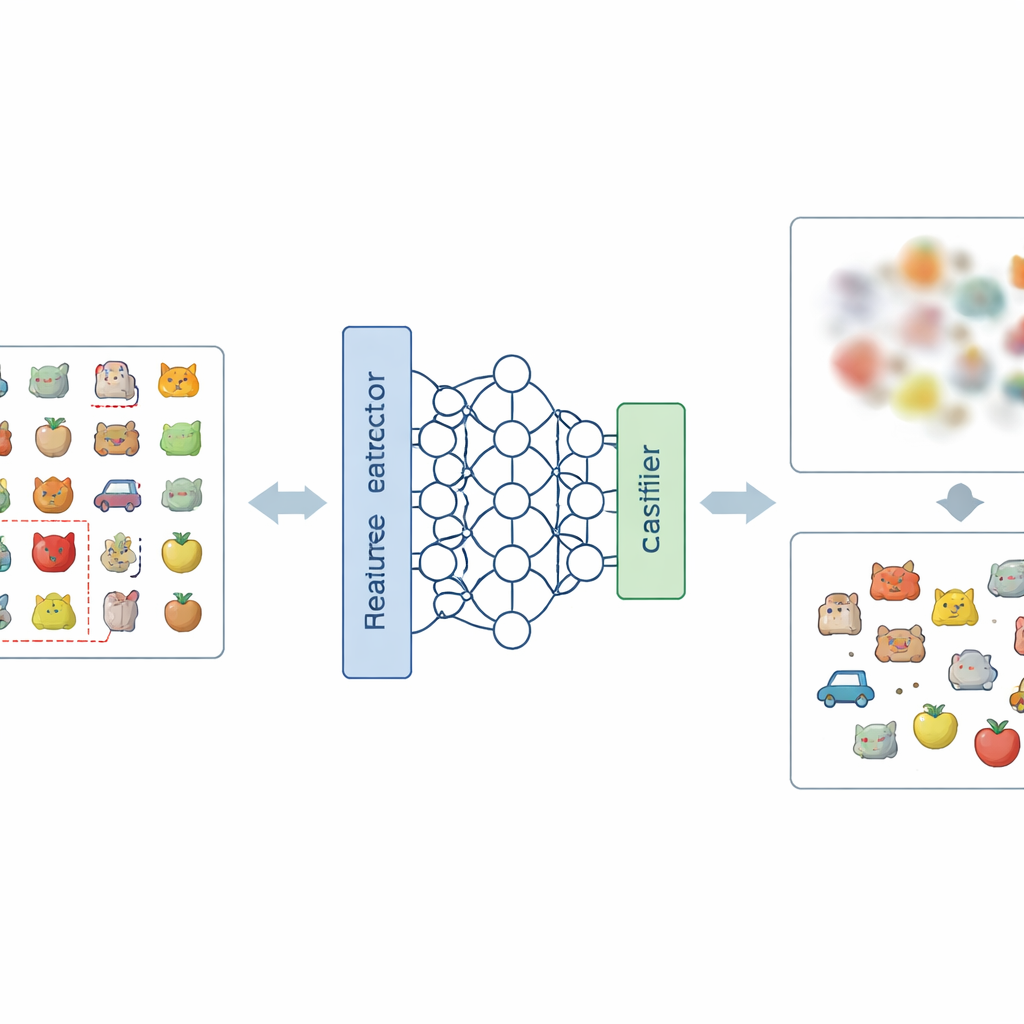
Une nouvelle recette pour estomper des souvenirs indésirables
L’idée centrale de l’article est d’attaquer le problème à deux niveaux : la représentation interne des images par le réseau et la manière dont il prend ses décisions finales. Au niveau de la représentation, les auteurs introduisent une nouvelle manière d’encoder les étiquettes, appelée encodage d’étiquette Negative-Hot. Plutôt que de renforcer la catégorie à oublier, ce schéma la traite presque comme une « anti-classe ». Lors d’une brève phase d’affinage (fine-tuning), en n’utilisant qu’une petite poignée d’images de la catégorie à supprimer, le réseau est incité à rendre la description interne de ces images moins distinctive et plus mêlée aux autres classes. Au niveau de la décision, ils ajoutent le masquage des poids de classe (Class Weight Masking), qui affaiblit sélectivement les connexions finales du modèle associées à la catégorie à oublier, réduisant ainsi son influence directe sur la sortie.
Comment des étiquettes négatives affaiblissent une catégorie
Les classifieurs d’images ordinaires sont entraînés avec des étiquettes « one-hot » : la classe correcte est mise en avant et les autres sont mises à zéro. Cela pousse le réseau à délimiter clairement chaque catégorie. L’encodage d’étiquette Negative-Hot inverse cette logique pour la catégorie que l’on souhaite effacer. Pendant l’unlearning, cette catégorie reçoit une contribution négative, tandis que les catégories restantes reçoivent de petites contributions positives. Mathématiquement, cela inverse et amplifie les mises à jour de gradient qui rendaient autrefois la classe oubliée si distinctive, repoussant progressivement ses caractéristiques vers la masse. Les visualisations de l’espace de caractéristiques internes du réseau montrent que, sous ce schéma, les points de la classe oubliée cessent de former un amas serré et distinct pour se fondre dans le nuage environnant des autres classes.
Couper les liens décisionnels tout en protégeant le reste
Modifier les étiquettes seul ne suffit pas, car ajuster les premières couches du réseau peut perturber involontairement la reconnaissance des autres catégories. Le masquage des poids de classe fournit une garde directe et peu coûteuse. Après le bref affinage avec des étiquettes négatives, la méthode identifie et atténue les composants du modèle les plus liés à la catégorie oubliée dans la couche classifieur finale. Cette étape réduit fortement la capacité du modèle à repérer cette catégorie, sans nécessiter de calculs globaux complexes ni l’accès à tous les exemples d’entraînement. Ensemble, les deux étapes forment le cadre NHLE–CWM : la première floute le souvenir indésirable dans l’espace des caractéristiques, la seconde coupe son influence restante sur les décisions, et les deux sont ajustées en n’utilisant qu’un petit nombre d’exemples issus des classes à supprimer.
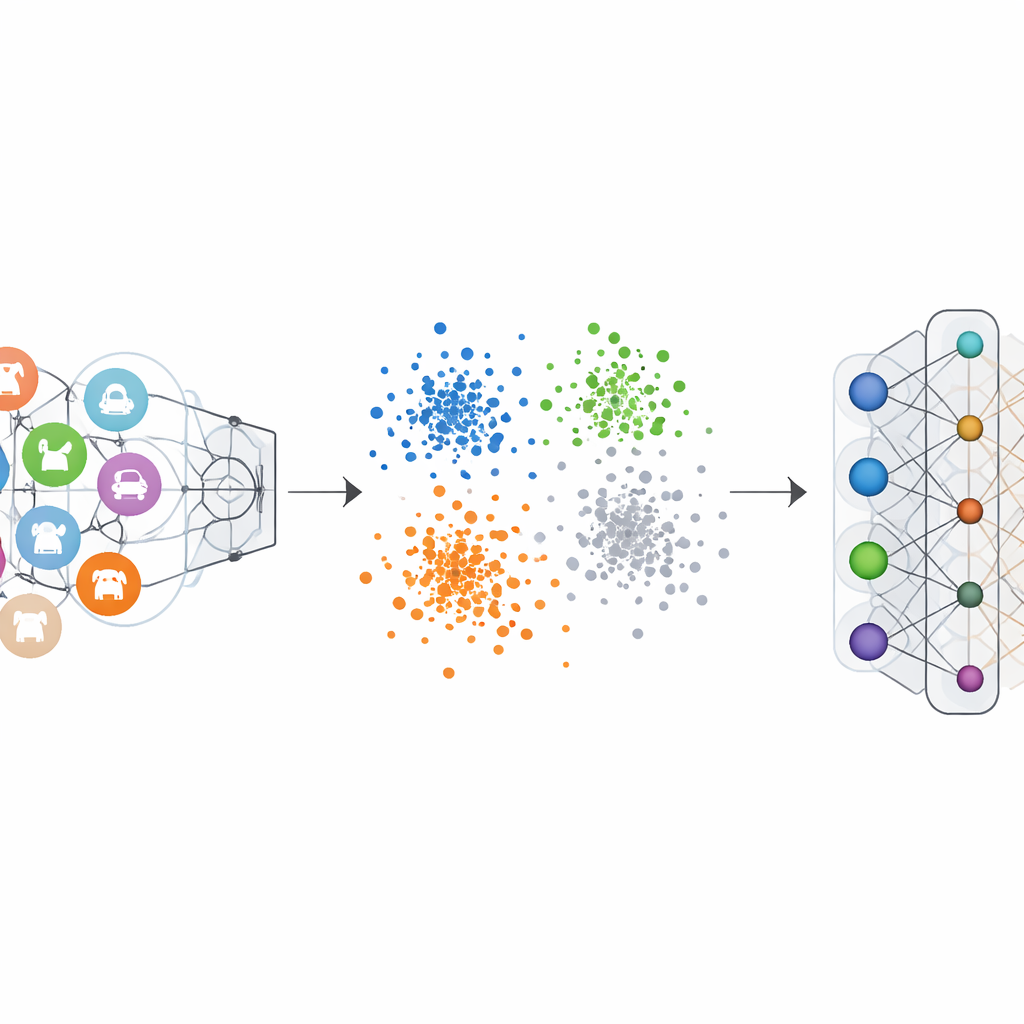
Preuve par de nombreux tests sur des benchmarks vision
Les auteurs ont testé leur cadre sur plusieurs jeux de données d’images bien connus, incluant des chiffres manuscrits, des numéros de maisons en vue de rue, des images de vêtements et des photos d’objets colorés, en utilisant diverses architectures neuronales populaires. Dans des scénarios d’oubli d’une seule classe comme de plusieurs classes, la méthode a fait chuter l’exactitude sur les classes oubliées jusqu’à presque zéro, rendant ainsi le modèle incapable de les reconnaître. Crucialement, l’exactitude sur les classes conservées a chuté d’au plus quelques points de pourcentage, et dans certains cas s’est même légèrement améliorée. Les comparaisons avec les méthodes d’unlearning de pointe montrent que cette nouvelle approche obtient un oubli plus fort avec moins de dégâts pour les performances restantes, tout en nécessitant seulement un petit ensemble d’exemples des classes à oublier et en évitant des calculs lourds.
Ce que cela signifie pour l’IA au quotidien
En termes simples, ce travail démontre qu’il est possible d’équiper des réseaux neuronaux d’une « gomme mémoire » contrôlée pour des types spécifiques de données. En modifiant habilement l’utilisation des étiquettes durant une brève étape de réentraînement et en masquant des poids décisionnels ciblés, le cadre NHLE–CWM rend la représentation de la catégorie oubliée à la fois floue et inactive. Pour les utilisateurs et les régulateurs, cela offre une voie plus réaliste pour appliquer le droit à l’oubli sans jeter des modèles précieux. Pour les praticiens, c’est un outil évolutif et peu coûteux en calcul pour supprimer des classes biaisées, obsolètes ou sensibles tout en conservant le reste du système intact.
Citation: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
Mots-clés: oublie machine, confidentialité des données, apprentissage profond, classification d’images, oublier un modèle