Clear Sky Science · ar
النسيان الآلي غير المتميز بالميزات عبر ترميز تسميات سلبية-ساخنة وقناع أوزان الفئات
لماذا يهم تعليم الآلات على النسيان
تعتمد التطبيقات الحديثة — من وسم الصور إلى تحليل الصور الطبية — على أنظمة قوية للتعرف على الصور مدرّبة على مجموعات بيانات ضخمة. لكن ماذا يحدث عندما يطلب شخص حذف بياناته، أو عندما تُكتشف مجموعة بيانات متحيزة أو غير آمنة؟ الشبكات العصبية الحالية لا تملك زر "حذف" بسيطًا. تقدم هذه الورقة طريقة عملية لجعل نموذج مدرّب "ينسى" فئات محددة من البيانات، مع الحفاظ إلى حد كبير على مهاراته في باقي المهام.
عندما يجب محو البيانات لا مجرد تجاهلها
قوانين مثل لائحة حماية البيانات العامة في أوروبا تمنح الأشخاص "الحق في النسيان"، ما يعني أن المؤسسات قد تحتاج إلى إزالة تأثير بيانات معينة من نماذجها، وليس مجرد التوقف عن حفظ الملفات. إعادة تدريب شبكة عصبية كبيرة من الصفر في كل مرة يحدث فيها ذلك بطيئة ومكلفة، وأحيانًا مستحيلة لأن البيانات الأصلية لم تعد متاحة بالكامل. يمكن أن تساعد طرق "النسيان الآلي" الحالية، لكنها غالبًا ما تتطلب الوصول إلى مجموعة التدريب الكاملة، أو تنطوي على حسابات رياضية مكثفة، أو تضر أداء النموذج على البيانات المتبقية بشكل ملحوظ. سعى المؤلفون إلى تصميم نهج يكون موجَّهاً وكفؤاً ورقيقًا على معرفة النموذج المفيدة.
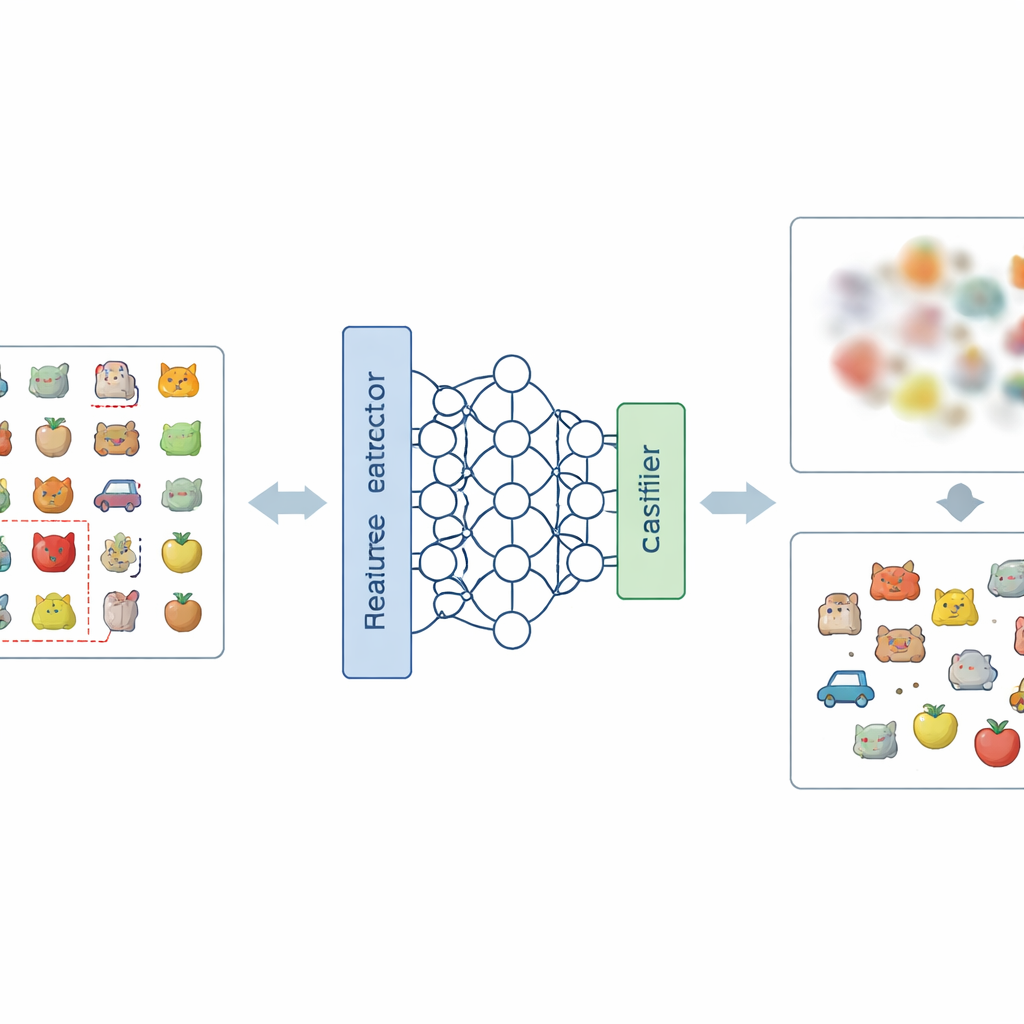
وصفة جديدة لطمس الذكريات غير المرغوب فيها
الفكرة الأساسية في الورقة هي مهاجمة المشكلة على مستويين: كيف تمثل الشبكة الصور داخليًا، وكيف تتخذ قرارها النهائي. على مستوى التمثيل، يقدم المؤلفون طريقة جديدة لترميز التسميات تُسمى ترميز التسميات السلبية-الساخنة. بدلاً من تعزيز الفئة التي يجب نسيانها، تُعامل هذه الخطة تلك الفئة كأنها تقريبًا "مصنفة مضادة". خلال مرحلة تعديل قصيرة للتدريب، باستخدام مجموعة بسيطة وصغيرة من الصور من الفئة المراد إزالتها، تُدفع الشبكة بحيث يصبح وصفها الداخلي لتلك الصور أقل تميزًا وأكثر تشابكًا مع الفئات الأخرى. وعلى مستوى القرار، يضيفون قناع أوزان الفئات، الذي يضعف بشكل انتقائي وصلات النموذج النهائية المرتبطة بالفئة المطلوب نسيانها، مقطوعًا بذلك تأثيرها المباشر على المخرجات.
كيف تضعف التسميات السلبية فئة ما
تُدرَّب مصنفات الصور التقليدية بتسميات "واحد-ساخن": تُؤكَّد الفئة الصحيحة وتُضبط الباقية على صفر. هذا يدفع الشبكة إلى نحت حدود واضحة لكل فئة. يقلب ترميز التسميات السلبية-الساخنة هذا المنطق للفئة التي نريد محوها. أثناء النسيان، تُمنح تلك الفئة مساهمة سلبية، بينما تتلقى الفئات المتبقية مساهمات موجبة صغيرة. رياضيًا، يعكس هذا ويضخم تحديثات التدرج التي جعلت الفئة المنسية مميزة في السابق، دافعًا ميزاتها تدريجيًا نحو التجمع العام. تظهر تصورات فضاء الميزات الداخلية للشبكة أنه بموجب هذا النظام، تتوقف نقاط الفئة المنسية عن تشكيل عنقود منفصل ومتماسك، وتندمج بدلًا من ذلك في السحابة المحيطة من الفئات الأخرى.
قطع روابط القرار مع حماية ما يبقى
تغيير التسميات وحده لا يكفي، لأن تعديل الطبقات المبكرة في الشبكة قد يزعج عن غير قصد كيفية تعرفها على فئات أخرى. يوفر قناع أوزان الفئات ضمانًا مباشرًا وميسور التكلفة. بعد التعديل القصير بالتسميات السلبية، يحدد الأسلوب ويخفت مكونات النموذج المرتبطة أكثر ما تكون بالفئة المنسية في طبقة المصنّف النهائية. تقلل هذه الخطوة بقوة قدرة النموذج على تمييز تلك الفئة، دون الحاجة إلى حسابات عالمية معقدة أو الوصول إلى جميع أمثلة التدريب. معًا، تشكل الخطوتان إطار NHLE–CWM: الأولى تطمس الذاكرة غير المرغوب فيها في فضاء الميزات، والثانية تقطع تأثيرها المتبقي على القرارات، وكلاهما مضبوط باستخدام عدد قليل فقط من صور العينات من الفئات المراد إزالتها.
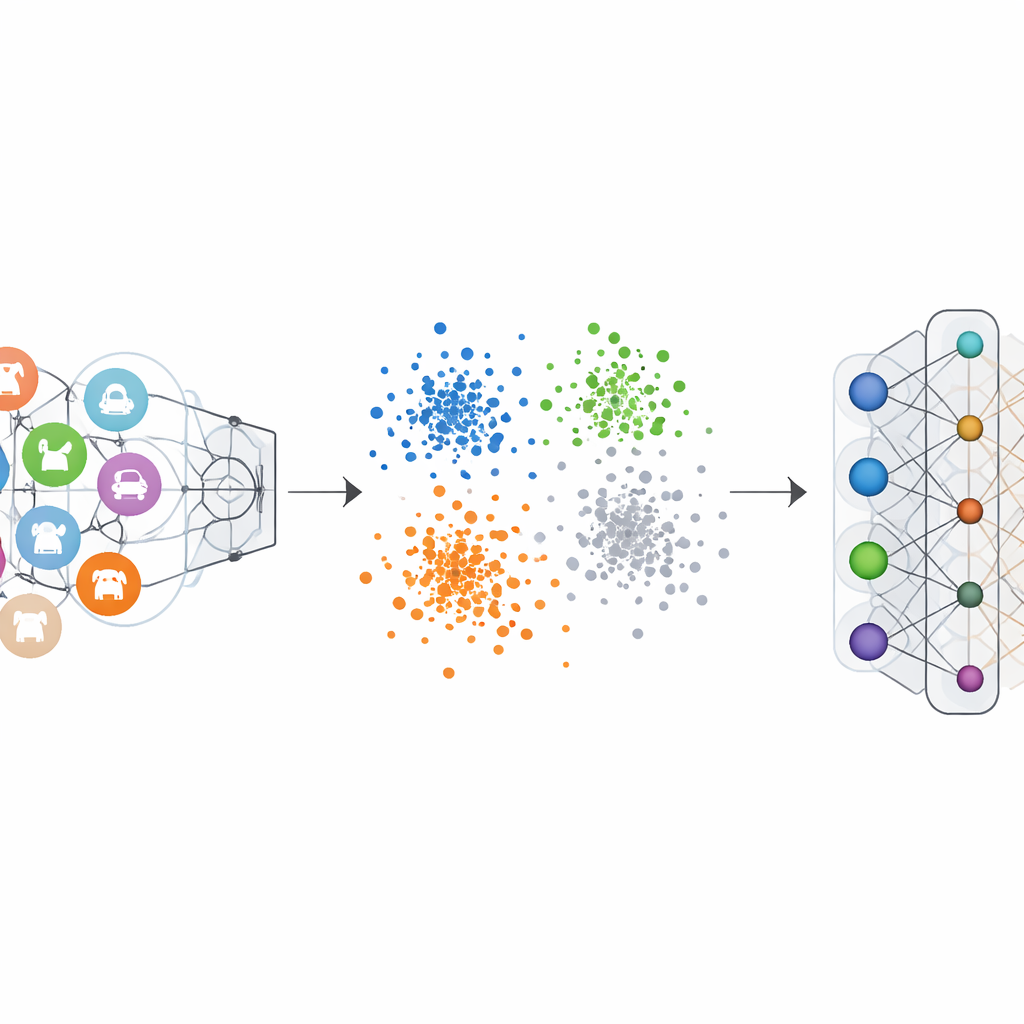
دليل من العديد من الاختبارات على بيانات رؤيوية معيارية
اختبر المؤلفون إطارهم على عدة مجموعات بيانات صور معروفة، بما في ذلك الأرقام اليدوية، أرقام منازل واجهات الشوارع، صور الملابس، وصور كائنات ملونة، مستخدمين مجموعة من البنى الشبكية العصبية الشهيرة. في سيناريوهات النسيان ذات الفئة الواحدة والمتعددة، خفضت الطريقة الدقة على الفئات المنسية إلى ما يقرب من الصفر، مما جعل النموذج عمليًا غير قادر على التعرف عليها. والأهم من ذلك، أن الدقة على الفئات المحتفظ بها انخفضت بحد أقصى بعدد نقاط مئوية قليلة، وفي بعض الحالات تحسنت طفيفًا. أظهرت المقارنات مع طرق النسيان الرائدة أن هذا النهج الجديد حقق نسيانًا أقوى مع ضرر أقل على الأداء المتبقي، وكل ذلك مع الحاجة فقط إلى مجموعة صغيرة من أمثلة الفئات المراد نسيانها وتجنب الحسابات الثقيلة.
ما الذي يعنيه هذا للذكاء الاصطناعي اليومي
بعبارات بسيطة، تُظهر هذه الدراسة أن من الممكن تجهيز الشبكات العصبية بـ"ممحاة ذاكرة" مُتحكم بها لأنواع محددة من البيانات. عن طريق تغيير ذكي لكيفية استخدام التسميات خلال خطوة إعادة تدريب قصيرة وبواسطة قناع أوزان قرار موجه، يجعل إطار NHLE–CWM رؤية النموذج للفئة المنسية ضبابية وغير فعّالة. للمستخدمين والمنظمين، يعني ذلك مسارًا أكثر واقعية لتطبيق الحق في النسيان دون التخلص من النماذج القيّمة. للممارسين، يقدم أداة قابلة للتوسع وخفيفة حسابيًا لإزالة فئات متحيزة أو قديمة أو حسّاسة مع الحفاظ على بقية النظام.
الاستشهاد: Wang, J., Bie, H., Jing, Z. et al. Feature-indistinguishable machine unlearning via negative-hot label encoding and class weight masking. Sci Rep 16, 11879 (2026). https://doi.org/10.1038/s41598-026-40379-9
الكلمات المفتاحية: النسيان الآلي للنماذج, خصوصية البيانات, التعلّم العميق, تصنيف الصور, نسيان النموذج