Clear Sky Science · zh
基于树莓派的 AI 驱动 BlindSpot VisionGuide 系统,提升视障用户独立性
帮助人们减少对视觉的依赖
对于数以百万计视力受限或失明的人来说,许多有视力的人视为理所当然的日常任务——识别朋友的面孔、了解房间里的物品或简单地获取新闻——在没有帮助的情况下可能既费力又无法完成。本文介绍了 BlindSpot‑VisionGuide,这是一套构建在低成本树莓派计算机上的紧凑系统,能听取语音指令、通过摄像头观察并以语音提供指导。通过将视觉信息实时转化为声音,它旨在让视障用户在家中、工作场所和外出时获得更多独立性。
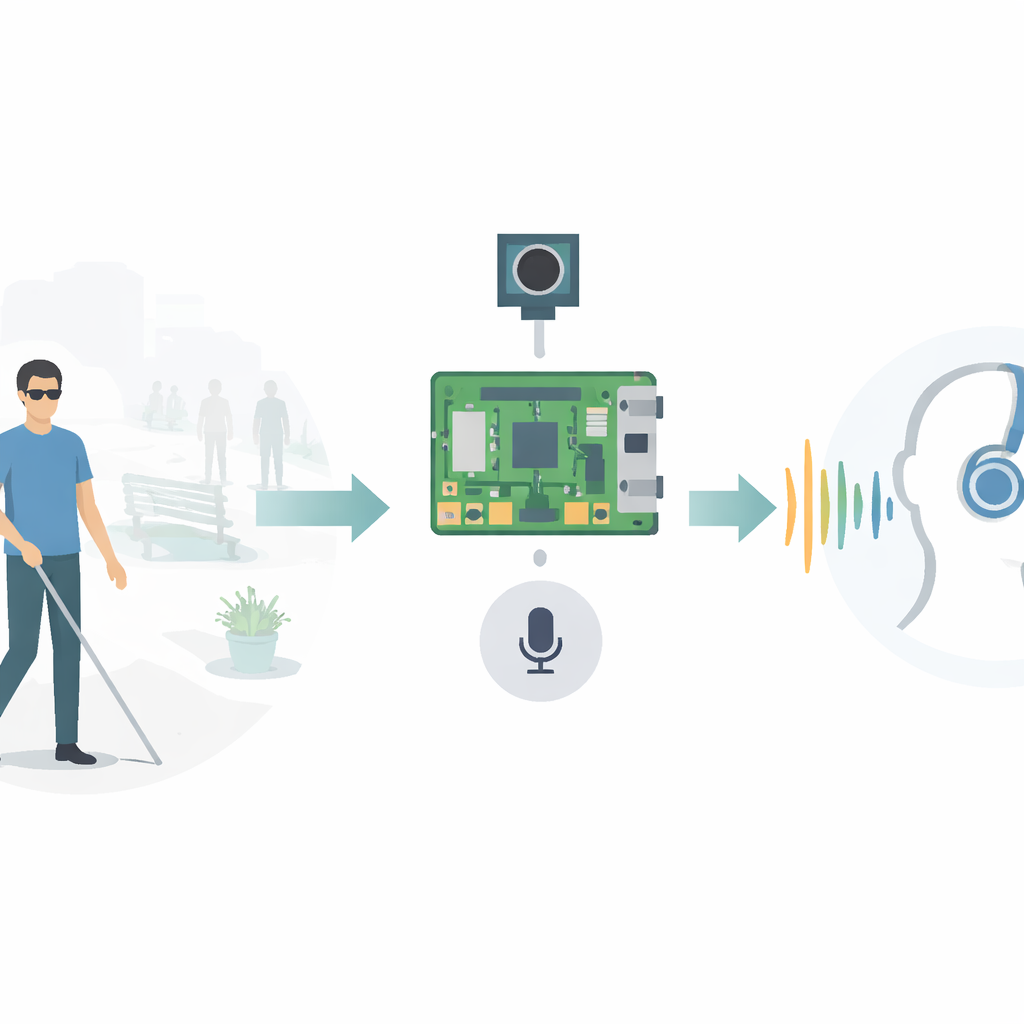
一个小盒子,三项有用功能
BlindSpot‑VisionGuide 将三项主要功能打包到一个设备中。首先,它可以识别熟悉的面孔,让用户在不等待介绍的情况下知道谁进入了房间。其次,它可以用通俗语言描述摄像头所见,例如“一个人坐在桌旁”或“一只鸟停在栏杆上”。第三,它可以从在线报纸抓取头条和简短摘要并朗读出来。所有这些都在树莓派 5 上运行——这是一台常用于爱好项目的信用卡大小的电脑,配合小型摄像头、麦克风和扬声器或耳机使用。
用说话代替点击
系统几乎完全依赖语音,而非屏幕、按钮或触摸手势。树莓派持续监听简单的口头命令,例如“运行人脸模块”或“运行报纸模块”。当用户触发人脸识别时,摄像头捕获实时视频,软件从中分离出人脸,将其与设备上小型的已知人脸库比对,然后语音播报最相近的匹配结果。对于场景描述,用户会有短暂停顿以调整摄像头;系统随后拍照并将图像传入先进的图像转文本模型,生成自然流畅的句子,再转成语音播放。对于新闻,系统访问在线服务,按国家、日期等选项筛选近期文章,然后以稳定、清晰的声音朗读每条标题和摘要。
智能模块如何协同工作
在后台,BlindSpot‑VisionGuide 借助现代人工智能工具,但以非常务实、工程化的方式使用它们。对于人脸识别,它将每张人脸转换为紧凑的数字“指纹”——通过深度网络生成——然后将该指纹与存储的样本进行比较。在对 20 名志愿者和 300 张图像的测试中,它约有 94% 的识别正确率,并且每张人脸的响应通常不到四分之一秒。对于图像字幕,它使用名为 BLIP 的强大模型,该模型结合了视觉模块与语言模块。这能生成丰富的描述,但在小型树莓派上讲述一条字幕大约需要 4.5 秒——对于理解静态场景足够快,但尚不足以应对过街等需瞬间决策的情形。报纸模块依赖 Web 编程接口而非脆弱的网页抓取,从而在限制发送的个人数据量的同时实现对最新新闻的可靠访问。
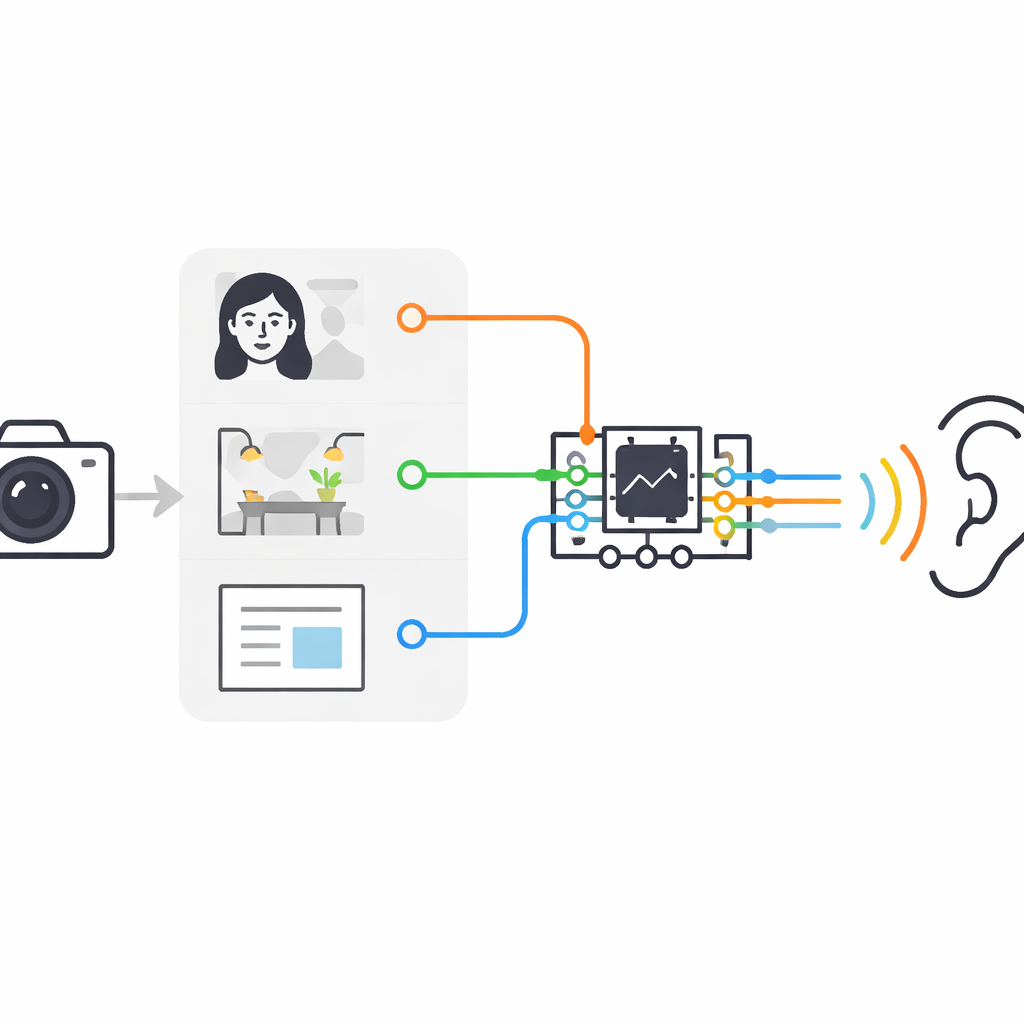
在速度、能耗与隐私之间取得平衡
一项关键挑战是将这三项功能塞入一台体积小、低功耗的计算机中,同时不依赖远端云服务器。作者把这当作系统工程问题来处理,而不是一味追求更大的神经网络。一次只运行一个模块,共享摄像头、麦克风和语音引擎,以控制内存使用和电池消耗。人脸识别和场景描述在模型存储到设备后可以完全离线工作,这有助于保护用户隐私。唯一的常规互联网使用是获取最新新闻,即便如此,系统也可以缓存文章,以便离线时重放。对 15 名视障参与者的用户测试在标准问卷中将整体可用性评分为“优秀”,任务成功率高且心理负担相对较低。
这对日常生活意味着什么
简而言之,BlindSpot‑VisionGuide 展示出一台低成本、口袋大小的计算机能够为无法依赖视觉的人提供一套有用的“眼睛和耳朵”。它并未发明新的学习算法;相反,它证明了现有的人脸、语言和语音工具可以经过谨慎组合在本地运行、对许多日常情境做出足够快速的响应,并尊重用户隐私。该系统尚不适合用于快速、涉及安全的导航情境,且仍依赖网络获取实时新闻并仅支持英语语音。但随着硬件加速器、更快模型和多语种语音的普及,这类集成的语音驱动设备有望成为视障用户的实用伴侣,帮助他们识别他人、理解周围环境并更少依赖他人地获取信息。
引用: Sudha, M., Swaminathan, S., Suba, M. et al. AI-powered BlindSpot VisionGuide system on raspberry Pi for enhancing independence of visually impaired users. Sci Rep 16, 11316 (2026). https://doi.org/10.1038/s41598-026-39724-9
关键词: 辅助技术, 视力障碍, Raspberry Pi, 计算机视觉, 文本转语音