Clear Sky Science · zh
CLTD-LP:一种结合线性前缀树的自上而下聚类优化方法,用于大规模数据集的可扩展频繁模式发现
发现隐藏在日常数据中的模式
每当我们在线购物、玩游戏或使用数字服务时,都会留下点击和选择的轨迹。在这些轨迹中埋藏着重复出现的模式,它们可以揭示哪些商品经常一起被购买、哪些系统事件常在故障之前出现,或人们在网站上的行为方式。本文介绍了一种新的计算机算法,称为 CLTD-LP,旨在在非常大且复杂的数据集中快速且更省内存地识别这些重复组合。
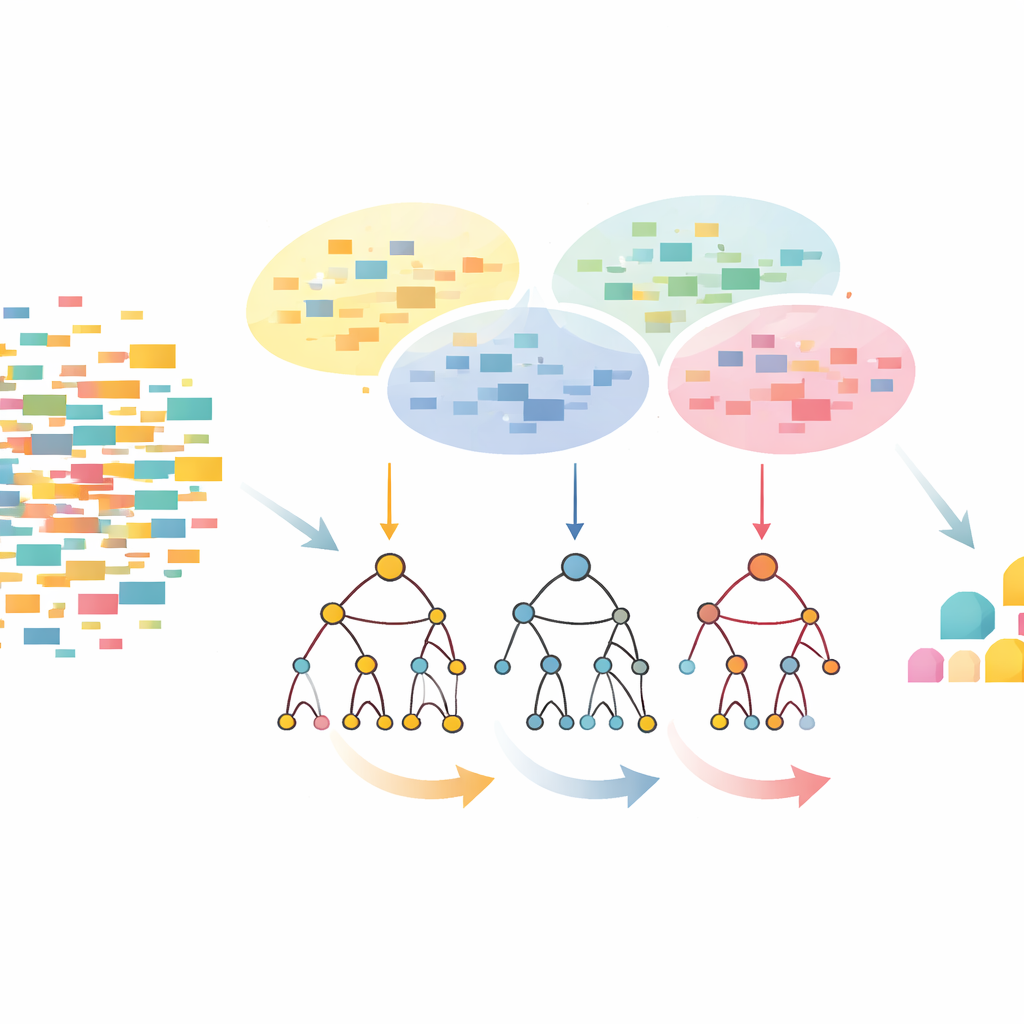
为什么重复组合很重要
现代组织收集了大量事件日志:杂货购买记录、网站会话、网络连接、病历等。数据分析中的一项基本任务是发现“频繁项集”——那些在许多记录中倾向于一起出现的项目组,例如杂货篮中的果酱、酱料和黄油,或在线购物会话中常见的一组点击。这些组合是推荐引擎、欺诈检测、交通事故分析和生物学发现的原始材料。然而,随着数据量增长,传统的模式发现方法会变得极其缓慢并且需要大量内存。
早期挖掘方法的局限
早期的算法,例如 Apriori 和 FP-growth,会扫描数据集以构建记录项目共现情况的结构。Apriori 采用自底向上的方式生成并测试大量候选组合,其数量可能呈爆炸式增长。FP-growth 通过构建一种特殊的树来压缩事务中的重复部分有所改进,但仍然需要为每个项目反复构建所谓的条件树和模式基。包括 LP-growth、OFIM 和 SSFIM 在内的较新变体尝试简化这些步骤,但当数据集既大又稀疏(许多项目很少出现且事务又长又多样)时,它们仍然举步维艰。
先聚类,再构建更聪明的树
CLTD-LP 的做法是在构建任何树之前先重塑数据集。它将每个事务(如购物篮或用户会话)视为一个简明的项的开/关模式,并使用聚类将相似事务分组。作者使用常见的相似性度量(雅卡尔德系数),并调节簇数以使簇内记录相似而簇间保持差异。在每个簇内,出现过于稀少的项目被剪除,空或近似空的事务被丢弃。剩下的是一个更小、更干净但仍保留核心行为的数据集。该经修剪的簇内数据随后输入线性前缀树——一种紧凑的、类似数组的结构,按一致顺序存储项目路径,避免了经典树设计中大量的指针开销。
自上而下的视角,而不是自下而上
在构建线性前缀树之后,CLTD-LP 使用自上而下的策略挖掘模式。它不是从树的底部开始为每个项目重建新的条件树,而是从最常见的项目向下遍历,使用“子头表”作为临时汇总。这些表记录包含给定项目的路径上项目的共同出现次数,而无需重建额外的树。通过在现有结构上直接更新计数并避免重复重建子树,CLTD-LP 大幅减少了工作量。在杂货店风格的示例中,算法可以通过沿树路径跟随链接并在共享路径上聚合计数,迅速发现诸如 {腰果, 酱料, 果酱} 或 {酱料, 果酱, 黄油, 奶油} 之类的项集。
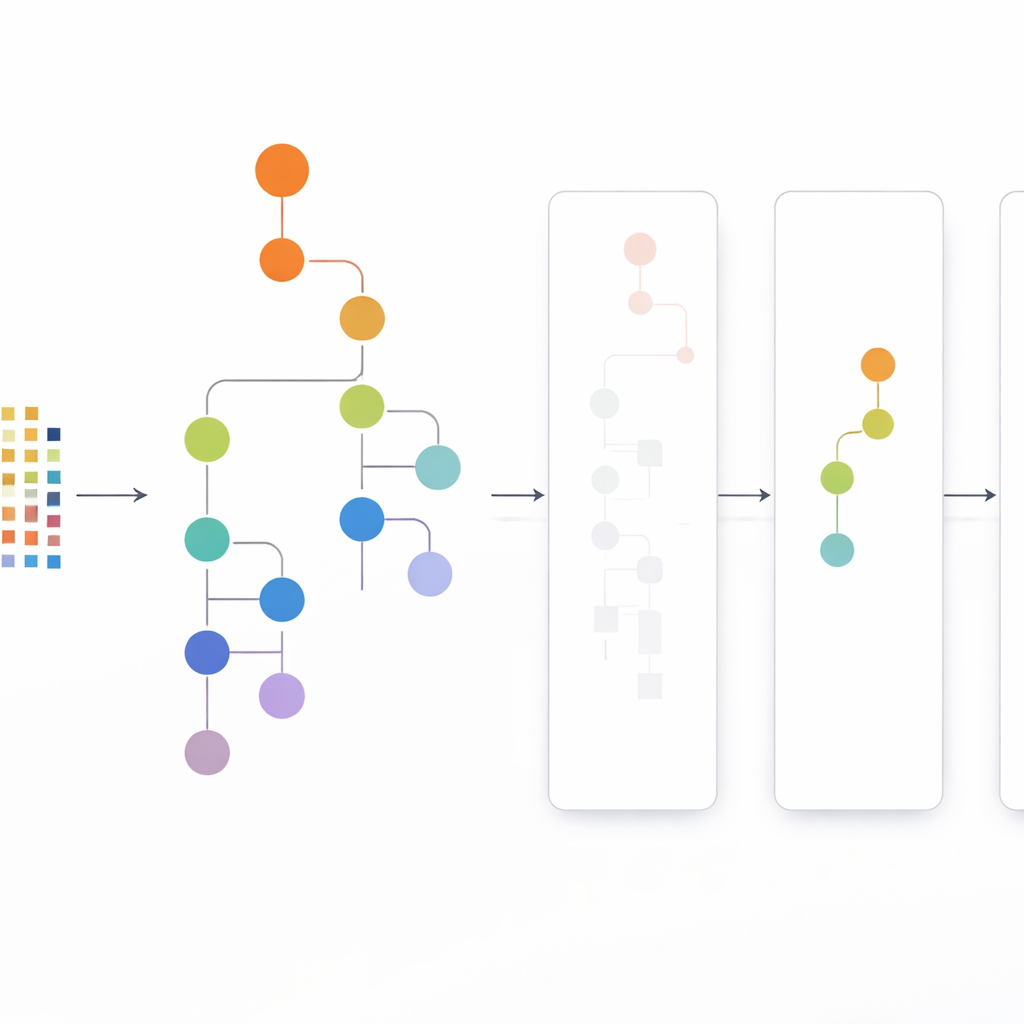
证明速度和内存优势
为测试新方法,作者将 CLTD-LP 应用于三个基准数据集:一个国际象棋游戏数据库、一个公开的人口统计数据集(Pumsb)以及他们构建的一个真实在线购物数据集。对于每个数据集,他们调整“频繁”阈值并将算法与 LP-growth、OFIM 和 SSFIM 进行比较。在全部三个数据集中,CLTD-LP 在时间和内存使用上都持续优于对手,尤其在所需频率阈值较低、需要探索许多项集的情况下更为明显。作者通过多次运行、对聚类设置的谨慎选择以及统计检验来支持这些观察,表明改进并非偶然。
这对现实世界数据挖掘的意义
简而言之,CLTD-LP 提供了一种在大规模记录集合中更高效地发现有意义组合的方式。通过先对相似事务分组、修剪不太可能的项目,然后自上而下地探索简化后的树,该方法避免了旧算法中大量的浪费。对处理日益增长的日志和交易数据的公司与研究人员而言,这意味着分析更快、内存占用更小且不牺牲准确性。该方法仍需对聚类参数进行细致调优,但它指向了能够跟上现代生活日益扩展的数字痕迹的可扩展工具。
引用: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
关键词: 频繁项集挖掘, 数据挖掘算法, 购物篮分析, 模式发现, 聚类方法