Clear Sky Science · pl
CLTD-LP: zoptymalizowane podejście top-down z liniowymi drzewami prefiksowymi dla skalowalnego odkrywania częstych wzorców w dużych zbiorach danych
Odnajdywanie wzorców ukrytych w codziennych danych
Za każdym razem, gdy robimy zakupy online, gramy w grę lub korzystamy z cyfrowej usługi, zostawiamy ślad kliknięć i wyborów. W tych śladach kryją się powtarzające się wzorce, które mogą ujawnić, które produkty są często kupowane razem, które zdarzenia systemowe poprzedzają awarię lub jak użytkownicy zachowują się na stronie. W artykule przedstawiono nowy algorytm komputerowy, nazwany CLTD-LP, zaprojektowany do wykrywania tych powtarzających się kombinacji szybko i przy mniejszym wykorzystaniu pamięci, nawet w bardzo dużych i złożonych zbiorach danych.
Dlaczego powtarzające się kombinacje mają znaczenie
Nowoczesne organizacje gromadzą ogromne logi zdarzeń: zakupy spożywcze, sesje na stronach internetowych, połączenia sieciowe, dokumentację medyczną i wiele innych. Podstawowym zadaniem w analizie danych jest odkrywanie „częstych zbiorów” – grup elementów, które mają tendencję do występowania razem w wielu rekordach, na przykład dżem, sos i masło w koszyku sklepowym, lub zestaw kliknięć często wykonywanych podczas sesji zakupowej online. Te grupy stanowią surowiec dla systemów rekomendacyjnych, wykrywania oszustw, analiz wypadków drogowych czy odkryć biologicznych. Jednak wraz ze wzrostem danych tradycyjne metody wyszukiwania takich wzorców mogą stawać się bardzo powolne i wymagać dużych ilości pamięci.
Ograniczenia wcześniejszych metod
Wcześniejsze generacje algorytmów, takie jak Apriori i FP-growth, przeszukują zbiory danych, budując struktury śledzące współwystępowanie elementów. Apriori działa od dołu, generując i testując liczne kandydackie kombinacje, których liczba może eksplodować. FP-growth udoskonala to przez budowę specjalnego drzewa, które kompresuje powtarzające się fragmenty transakcji, ale wciąż polega na wielokrotnym tworzeniu tzw. drzew warunkowych i baz wzorców dla każdego elementu. Nowsze warianty, w tym LP-growth, OFIM i SSFIM, próbują usprawnić te kroki, lecz nadal mają trudności, gdy zbiory danych są jednocześnie duże i rzadkie — wiele elementów występuje rzadko, a transakcje są długie i zróżnicowane.
Najpierw klastrowanie, potem inteligentniejsze drzewo
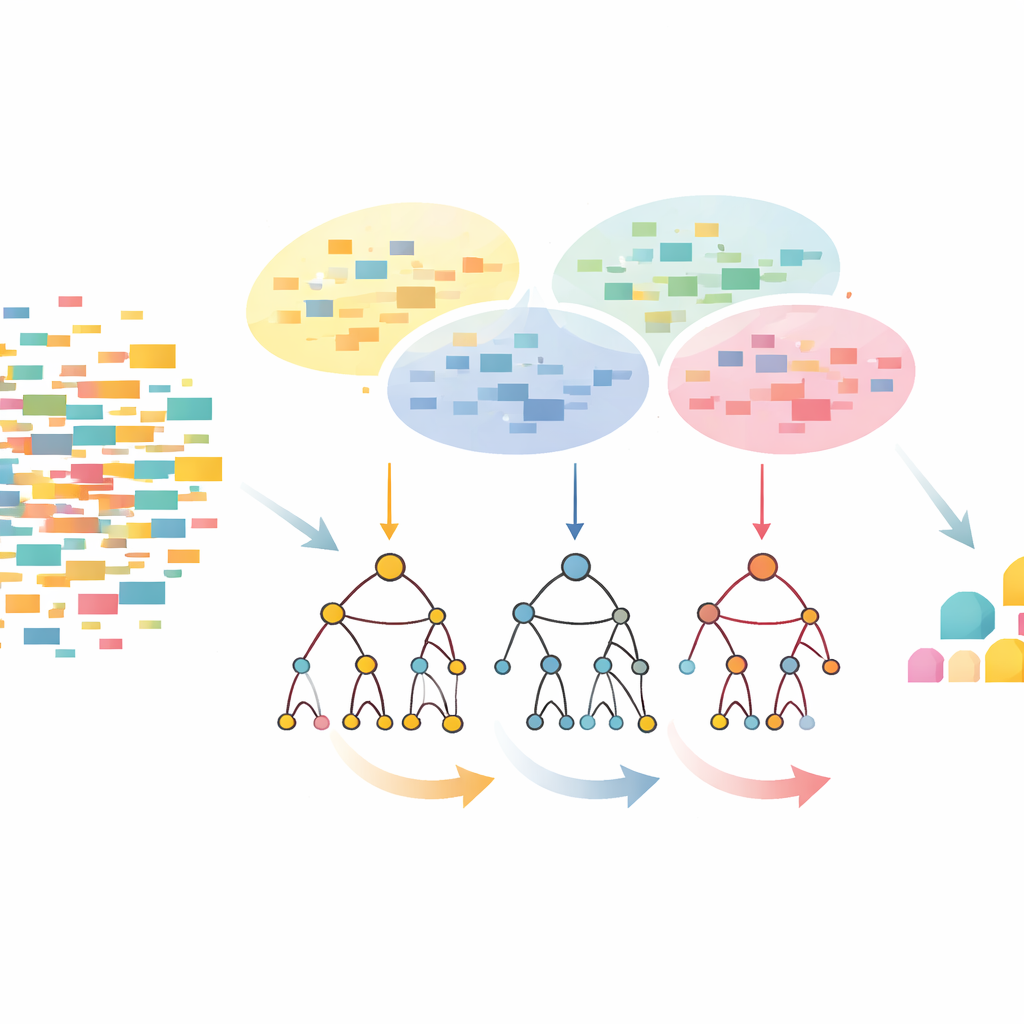
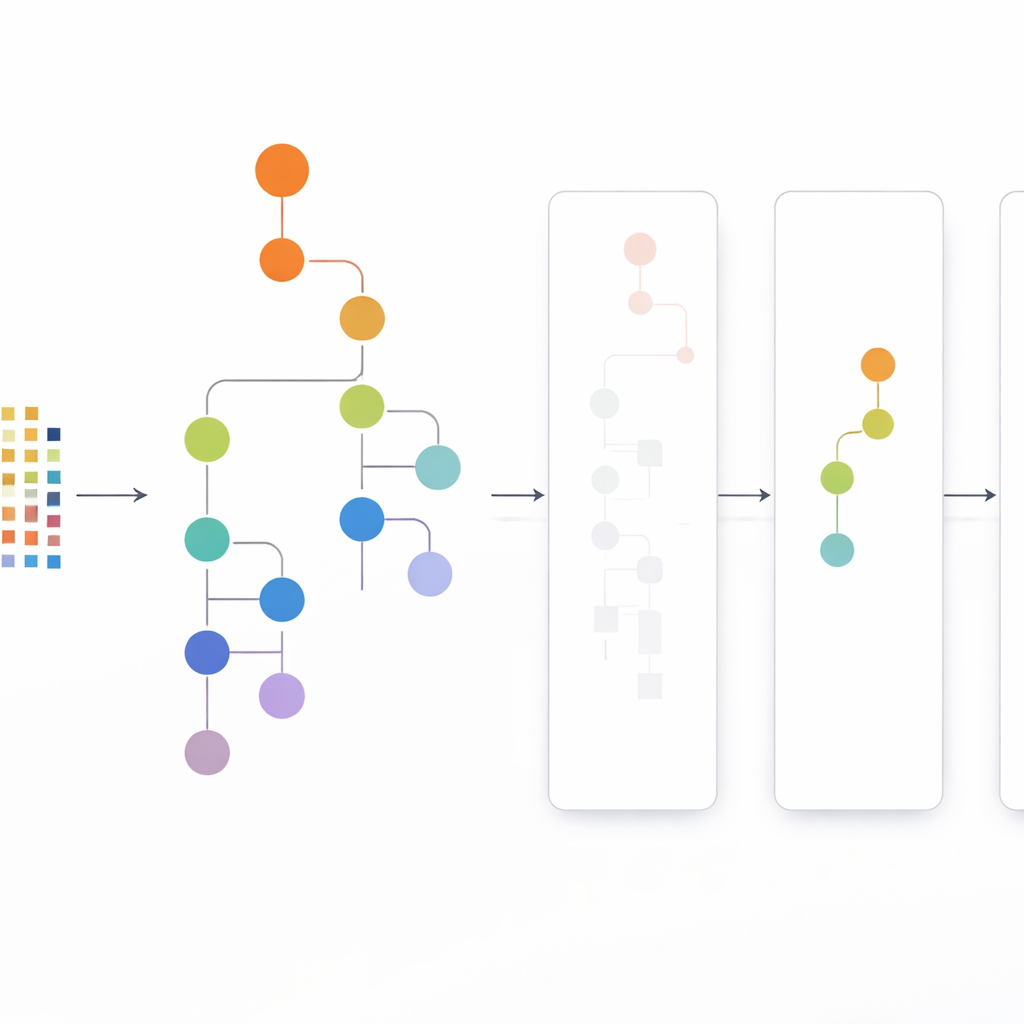
Podejście CLTD-LP zaczyna od przekształcenia zbioru danych, zanim zostanie zbudowane jakiekolwiek drzewo. Traktuje każdą transakcję, taką jak koszyk zakupowy czy sesja użytkownika, jako prosty wzorzec włącz/wyłącz elementów i grupuje podobne transakcje za pomocą klastrowania. Autorzy używają powszechnego miary podobieństwa (współczynnika Jaccarda) i dobierają liczbę klastrów tak, aby rekordy w klastrze były do siebie podobne, a różne klastry pozostawały odrębne. W obrębie każdego klastra elementy występujące zbyt rzadko są odcinane, a puste lub niemal puste transakcje są odrzucane. Pozostały mniejszy, oczyszczony zbiór danych nadal zachowuje istotne wzorce. Tak przycięte dane dla każdego klastra trafiają następnie do liniowego drzewa prefiksowego — zwartej, tablicopodobnej struktury przechowującej ścieżki elementów w spójnym porządku, co eliminuje dużą część narzutu wskaźników typowego dla klasycznych drzew.
Patrzenie z góry w dół zamiast od dołu do góry
Po zbudowaniu liniowego drzewa prefiksowego CLTD-LP kopiuje wzorce używając strategii top-down. Zamiast zaczynać od dołu drzewa i rekonstruować nowe drzewa warunkowe dla każdego elementu, metoda schodzi od najczęściej występujących elementów w dół, wykorzystując „tabele podnagłówków” jako tymczasowe podsumowania. Tabele te śledzą, jak często elementy pojawiają się razem wzdłuż ścieżek zawierających dany element, bez potrzeby odtwarzania dodatkowych drzew. Poprzez bezpośrednie aktualizowanie zliczeń w istniejącej strukturze i unikanie wielokrotnego przebudowywania poddrzew, CLTD-LP znacząco redukuje ilość pracy. W przykładzie sklepowym algorytm szybko ujawnia zestawy takie jak {orzech nerkowca, sos, dżem} lub {sos, dżem, masło, śmietana} podążając po linkach w drzewie i agregując zliczenia wzdłuż wspólnych ścieżek.
Udowodnienie przyspieszenia i oszczędności pamięci
Aby przetestować nową metodę, autorzy zastosowali CLTD-LP do trzech zestawów referencyjnych: bazy partii gry w szachy, publicznego zestawu demograficznego (Pumsb) oraz rzeczywistego zbioru danych zakupów online, który sami skonstruowali. Dla każdego zbioru zmieniali próg, od którego wzorzec uznawany był za „częsty”, i porównywali swój algorytm z LP-growth, OFIM i SSFIM. We wszystkich trzech przypadkach CLTD-LP konsekwentnie kończy pracę szybciej i zużywa mniej pamięci, zwłaszcza gdy wymagany próg częstości jest niski i trzeba przeszukać wiele zbiorów. Autorzy podpierają te obserwacje powtarzalnymi uruchomieniami, starannym doborem ustawień klastrowania i testami statystycznymi wykazującymi, że poprawy nie wynikają z przypadku.
Co to oznacza dla praktycznego wydobywania danych
Mówiąc wprost, CLTD-LP oferuje bardziej efektywny sposób znajdowania znaczących kombinacji w dużych zbiorach rekordów. Dzięki najpierw grupowaniu podobnych transakcji, przycinaniu mało prawdopodobnych elementów, a następnie eksplorowaniu uproszczonego drzewa od góry w dół, metoda unika wielu strat występujących w starszych algorytmach. Dla firm i badaczy mających do czynienia z rosnącymi wolumenami logów i danych transakcyjnych oznacza to szybsze analizy i mniejsze zużycie pamięci, bez utraty dokładności. Podejście nadal wymaga starannego strojenia parametrów klastrowania, ale wskazuje drogę ku skalowalnym narzędziom, które nadążą za stale rosnącymi cyfrowymi śladami współczesnego życia.
Cytowanie: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Słowa kluczowe: wydobywanie częstych zbiorów, algorytmy data mining, analiza koszyków zakupowych, odkrywanie wzorców, metody klastrowania