Clear Sky Science · en
CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets
Finding Patterns Hidden in Everyday Data
Every time we shop online, play a game, or use a digital service, we leave behind a trail of clicks and choices. Buried in these trails are recurring patterns that can reveal which products are often bought together, which system events tend to precede a failure, or how people behave on a website. This paper introduces a new computer algorithm, called CLTD-LP, designed to spot these repeating combinations quickly and with less memory, even in very large and complex datasets.
Why Repeated Combinations Matter
Modern organizations collect enormous logs of events: grocery purchases, website sessions, network connections, medical records, and more. A basic task in data analysis is to discover “frequent itemsets” – groups of things that tend to appear together in many records, such as jam, sauce, and butter in a grocery basket, or a set of clicks commonly made during an online shopping session. These groups are the raw material for recommendation engines, fraud detection, traffic accident analysis, and biological discovery. However, as data grows, traditional methods for finding such patterns can become painfully slow and demand large amounts of memory.
Limits of Earlier Mining Methods
Earlier generations of algorithms, like Apriori and FP-growth, scan through datasets to build structures that keep track of which items co-occur. Apriori works bottom-up by generating and testing many candidate combinations, which can explode in number. FP-growth improves on this by building a special tree that compresses repeated parts of transactions, but it still relies on repeatedly building so‑called conditional trees and pattern bases for each item. More recent variants, including LP-growth, OFIM, and SSFIM, try to streamline these steps, yet they continue to struggle when datasets are both large and sparse, where many items are rare and transactions are long and varied.
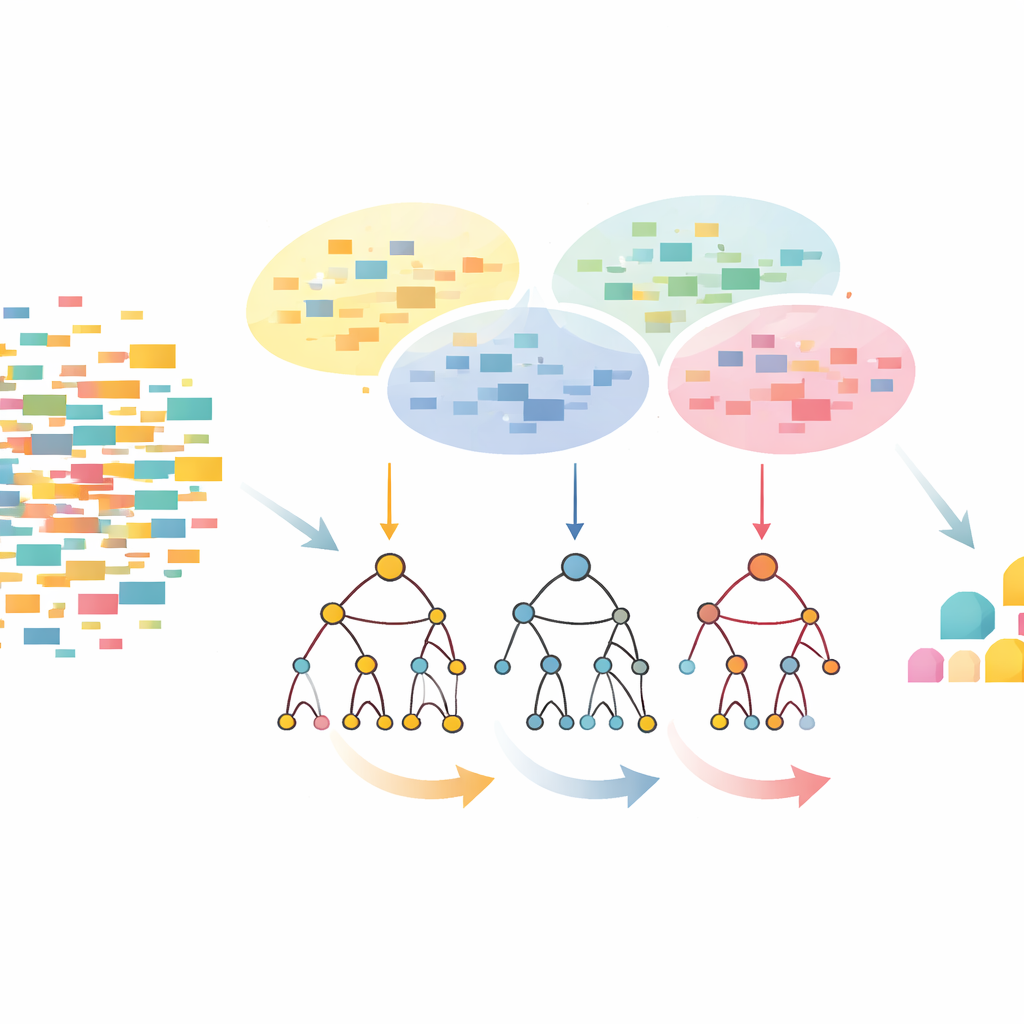
Clustering First, Then a Smarter Tree
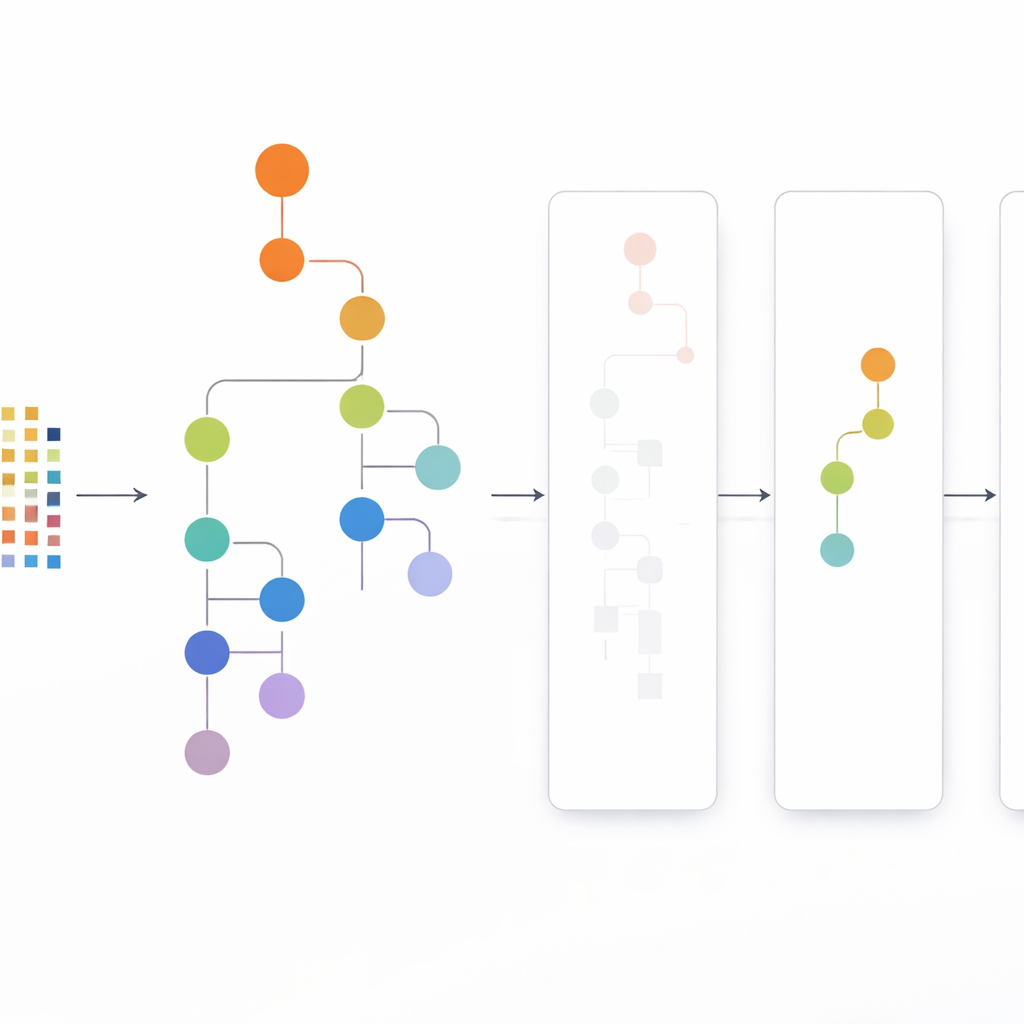
The CLTD-LP approach starts by reshaping the dataset before any tree is built. It treats each transaction, such as a shopping basket or user session, as a simple on–off pattern of items and groups similar transactions using clustering. The authors use a common similarity measure (the Jaccard coefficient) and tune the number of clusters so that records inside a cluster are alike but different clusters stay distinct. Within each cluster, items that appear too rarely are trimmed away, and empty or nearly empty transactions are discarded. What remains is a smaller, cleaner dataset that still preserves the core behavior. This pruned, cluster‑wise data then feeds into a linear prefix tree – a compact, array‑like structure that stores paths of items in a consistent order, avoiding much of the pointer overhead of classic tree designs.
Looking From the Top Down Instead of From the Bottom Up
Once the linear prefix tree is built, CLTD-LP mines patterns using a top‑down strategy. Instead of starting from the bottom of the tree and reconstructing new conditional trees for each item, the method walks from the most common items downward, using “sub-header tables” as temporary summaries. These tables keep track of how often items appear together along the paths that include a given item, without recreating extra trees. By updating counts directly on the existing structure and avoiding repeated rebuilding of subtrees, CLTD-LP dramatically cuts the amount of work. In a grocery-style example, the algorithm quickly surfaces sets like {cashew, sauce, jam} or {sauce, jam, butter, cream} by following links through the tree and aggregating counts along shared paths.
Proving Speed and Memory Gains
To test the new method, the authors apply CLTD-LP to three benchmark datasets: a chess game database, a public demographic dataset (Pumsb), and a real online shopping dataset they constructed. For each dataset, they vary how “frequent” a pattern must be to count and compare their algorithm against LP-growth, OFIM, and SSFIM. Across all three, CLTD-LP consistently finishes its work in less time and uses less memory, especially when the required frequency threshold is low and many itemsets must be explored. The authors back these observations with repeated runs, careful choice of clustering settings, and statistical tests showing that the improvements are not due to chance.
What This Means for Real-World Data Mining
In simple terms, CLTD-LP offers a more efficient way to find meaningful combinations in large collections of records. By first grouping similar transactions, trimming unlikely items, and then exploring a streamlined tree from the top down, the method avoids much of the waste seen in older algorithms. For companies and researchers dealing with growing volumes of log and transaction data, this means faster analyses and smaller memory footprints, without sacrificing accuracy. The approach still requires careful tuning of clustering settings, but it points toward scalable tools that can keep up with the ever‑expanding digital traces of modern life.
Citation: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Keywords: frequent itemset mining, data mining algorithms, shopping basket analysis, pattern discovery, clustering methods