Clear Sky Science · es
CLTD-LP: un enfoque de clustering optimizado de arriba hacia abajo con árboles prefijo lineales para el descubrimiento escalable de patrones frecuentes en grandes conjuntos de datos
Encontrar patrones ocultos en los datos cotidianos
Cada vez que compramos en línea, jugamos o usamos un servicio digital, dejamos un rastro de clics y elecciones. Enterrados en esos rastros hay patrones recurrentes que pueden revelar qué productos se compran a menudo juntos, qué eventos del sistema tienden a preceder a una falla o cómo se comportan las personas en un sitio web. Este artículo presenta un nuevo algoritmo informático, llamado CLTD-LP, diseñado para detectar estas combinaciones repetidas de forma rápida y con menos memoria, incluso en conjuntos de datos muy grandes y complejos.
Por qué importan las combinaciones recurrentes
Las organizaciones modernas recopilan enormes registros de eventos: compras de supermercado, sesiones web, conexiones de red, historiales médicos y más. Una tarea básica en el análisis de datos es descubrir “conjuntos frecuentes” —grupos de elementos que tienden a aparecer juntos en muchos registros, como mermelada, salsa y mantequilla en una cesta de la compra, o un conjunto de clics común en una sesión de compra en línea. Estos grupos son la materia prima de los motores de recomendación, la detección de fraude, el análisis de accidentes de tráfico y los descubrimientos biológicos. Sin embargo, a medida que los datos crecen, los métodos tradicionales para encontrar esos patrones pueden volverse extremadamente lentos y exigir grandes cantidades de memoria.
Límites de métodos de minería anteriores
Las generaciones anteriores de algoritmos, como Apriori y FP-growth, recorren los conjuntos de datos para construir estructuras que registran qué elementos coocurren. Apriori trabaja de abajo hacia arriba generando y evaluando muchas combinaciones candidatas, cuyo número puede explotar. FP-growth mejora esto construyendo un árbol especial que comprime las partes repetidas de las transacciones, pero aún depende de construir repetidamente las llamadas árboles condicionales y bases de patrones para cada elemento. Variantes más recientes, incluidas LP-growth, OFIM y SSFIM, intentan agilizar estos pasos, pero siguen teniendo dificultades cuando los conjuntos de datos son a la vez grandes y dispersos, con muchos elementos raros y transacciones largas y variadas.
Primero clustering, luego un árbol más inteligente
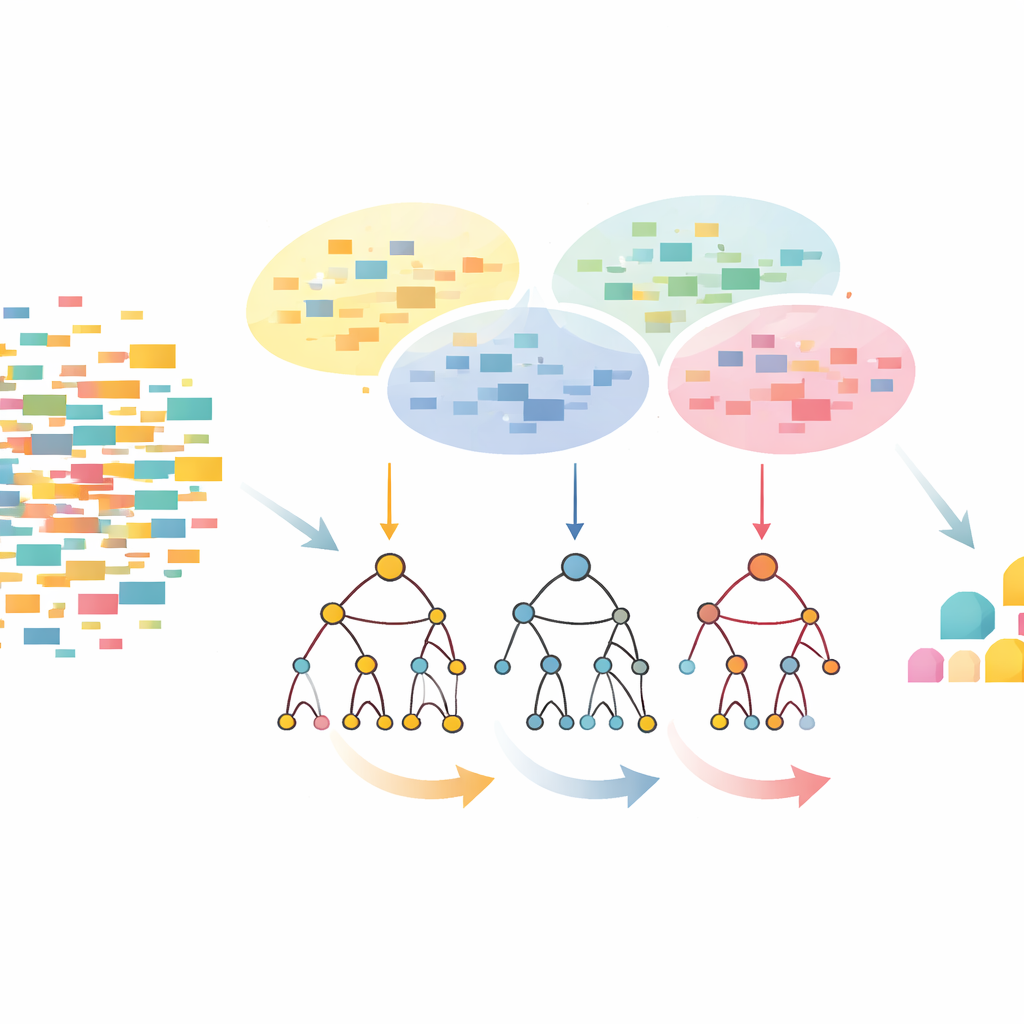
El enfoque CLTD-LP comienza reconfigurando el conjunto de datos antes de construir cualquier árbol. Trata cada transacción, como una cesta de la compra o una sesión de usuario, como un patrón simple de encendido/apagado de elementos y agrupa transacciones similares mediante clustering. Los autores usan una medida de similitud común (el coeficiente de Jaccard) y ajustan el número de clústeres para que los registros dentro de un clúster sean parecidos entre sí pero distintos respecto a otros clústeres. Dentro de cada clúster, los elementos que aparecen con muy poca frecuencia se eliminan, y las transacciones vacías o casi vacías se descartan. Lo que queda es un conjunto de datos más pequeño y limpio que aún conserva el comportamiento central. Estos datos podados por clústeres alimentan luego un árbol prefijo lineal —una estructura compacta, tipo arreglo, que almacena rutas de elementos en un orden consistente, evitando gran parte de la sobrecarga de punteros de los diseños clásicos de árboles.
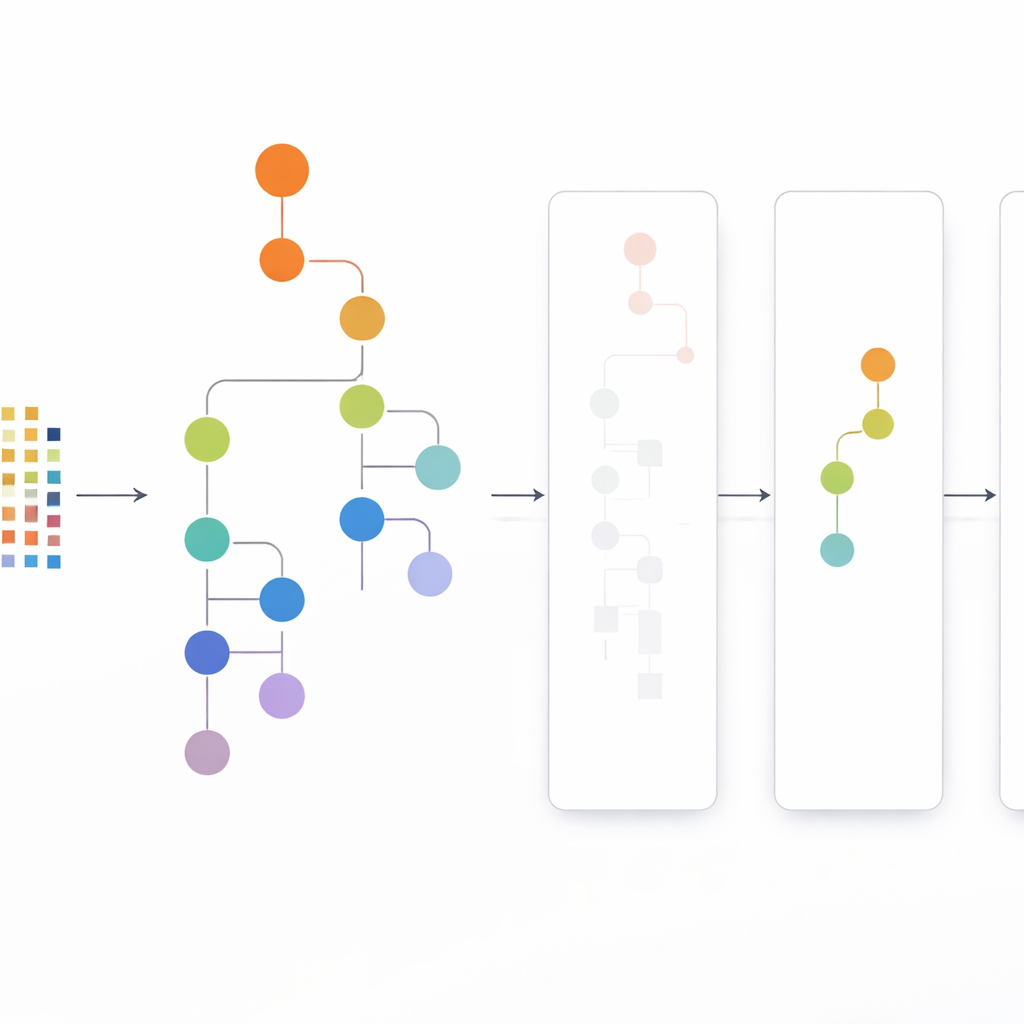
Mirando de arriba abajo en lugar de de abajo arriba
Una vez construido el árbol prefijo lineal, CLTD-LP extrae patrones usando una estrategia de arriba hacia abajo. En lugar de comenzar desde la base del árbol y reconstruir nuevos árboles condicionales para cada elemento, el método recorre desde los elementos más comunes hacia abajo, usando “tablas sub-encabezado” como resúmenes temporales. Estas tablas registran con qué frecuencia aparecen los elementos juntos a lo largo de las rutas que incluyen un determinado elemento, sin recrear árboles adicionales. Al actualizar los conteos directamente en la estructura existente y evitar la reconstrucción repetida de subárboles, CLTD-LP reduce drásticamente la cantidad de trabajo. En un ejemplo de tipo supermercado, el algoritmo rápidamente muestra conjuntos como {anacardo, salsa, mermelada} o {salsa, mermelada, mantequilla, nata} siguiendo enlaces a través del árbol y agregando conteos a lo largo de rutas compartidas.
Demostrando mejoras en velocidad y memoria
Para probar el nuevo método, los autores aplican CLTD-LP a tres conjuntos de datos de referencia: una base de datos de partidas de ajedrez, un conjunto demográfico público (Pumsb) y un conjunto real de compras en línea que ellos construyeron. Para cada conjunto, varían el umbral de “frecuencia” que debe alcanzar un patrón para contarse y comparan su algoritmo con LP-growth, OFIM y SSFIM. En los tres casos, CLTD-LP completa su trabajo en menos tiempo y usa menos memoria, especialmente cuando el umbral de frecuencia requerido es bajo y deben explorarse muchos conjuntos de ítems. Los autores respaldan estas observaciones con ejecuciones repetidas, una selección cuidadosa de parámetros de clustering y pruebas estadísticas que muestran que las mejoras no se deben al azar.
Qué significa esto para la minería de datos en el mundo real
En términos sencillos, CLTD-LP ofrece una forma más eficiente de encontrar combinaciones significativas en grandes colecciones de registros. Al agrupar primero transacciones similares, podar elementos improbables y luego explorar un árbol simplificado de arriba hacia abajo, el método evita gran parte del desperdicio observado en algoritmos más antiguos. Para empresas e investigadores que manejan volúmenes crecientes de registros y datos de transacción, esto significa análisis más rápidos y una menor huella de memoria, sin sacrificar la precisión. El enfoque aún requiere un ajuste cuidadoso de los parámetros de clustering, pero apunta hacia herramientas escalables que pueden seguir el ritmo de los rastros digitales cada vez mayores de la vida moderna.
Cita: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Palabras clave: minería de conjuntos frecuentes, algoritmos de minería de datos, análisis de cesta de la compra, descubrimiento de patrones, métodos de clustering