Clear Sky Science · it
CLTD-LP: un approccio di clustering top-down ottimizzato con alberi prefisso lineari per la scoperta scalabile di pattern frequenti in grandi dataset
Trovare i pattern nascosti nei dati di tutti i giorni
Ogni volta che facciamo acquisti online, giochiamo o utilizziamo un servizio digitale, lasciamo una scia di clic e scelte. Seppelliti in queste tracce ci sono pattern ricorrenti che possono rivelare quali prodotti vengono spesso comprati insieme, quali eventi di sistema tendono a precedere un guasto o come si comportano gli utenti su un sito web. Questo articolo presenta un nuovo algoritmo, chiamato CLTD-LP, progettato per individuare queste combinazioni ripetute in modo rapido e con meno memoria, anche in dataset molto grandi e complessi.
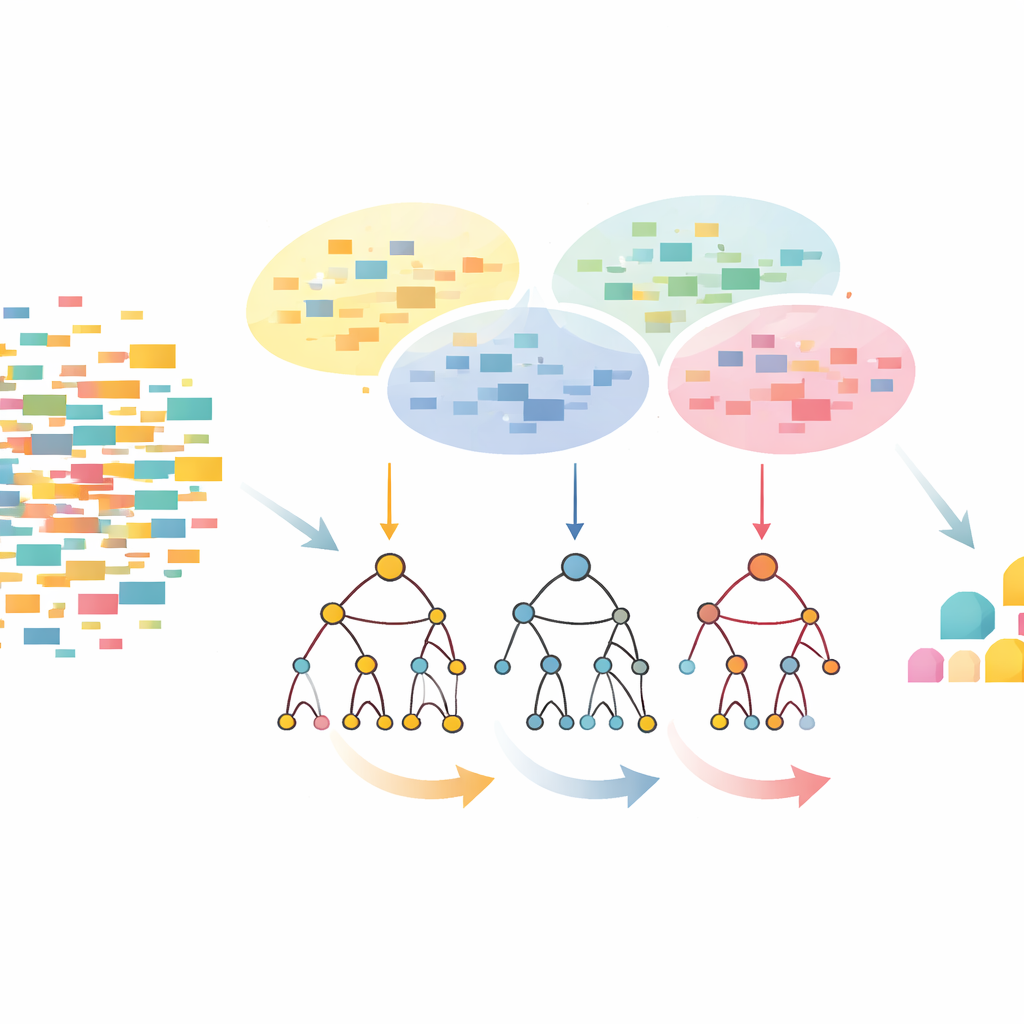
Perché le combinazioni ripetute sono importanti
Le organizzazioni moderne raccolgono enormi registri di eventi: acquisti di generi alimentari, sessioni web, connessioni di rete, cartelle cliniche e altro ancora. Un compito fondamentale nell’analisi dei dati è scoprire “itemset frequenti” – gruppi di elementi che tendono a comparire insieme in molti record, come marmellata, salsa e burro in un carrello della spesa, o un insieme di clic tipici di una sessione di shopping online. Questi gruppi sono la materia prima per motori di raccomandazione, rilevamento delle frodi, analisi degli incidenti stradali e scoperte biologiche. Tuttavia, con la crescita dei dati, i metodi tradizionali per trovare tali pattern possono diventare molto lenti e richiedere grandi quantità di memoria.
Limiti dei metodi di mining precedenti
Le generazioni precedenti di algoritmi, come Apriori e FP-growth, scandagliano i dataset per costruire strutture che tengono traccia degli elementi che co-occorrono. Apriori opera dal basso verso l’alto generando e testando molte combinazioni candidate, il cui numero può esplodere. FP-growth migliora costruendo un albero speciale che comprime le parti ripetute delle transazioni, ma si basa ancora sulla ricostruzione ripetuta di cosiddetti alberi condizionali e basi di pattern per ogni elemento. Varianti più recenti, incluse LP-growth, OFIM e SSFIM, cercano di snellire questi passaggi, ma continuano a incontrare difficoltà quando i dataset sono sia grandi sia sparsi, con molti elementi rari e transazioni lunghe e variabili.
Prima il clustering, poi un albero più intelligente
L’approccio CLTD-LP parte rimodellando il dataset prima di costruire qualsiasi albero. Tratta ogni transazione, come un carrello o una sessione utente, come un semplice pattern acceso/spento degli elementi e raggruppa le transazioni simili tramite clustering. Gli autori utilizzano una misura di similarità comune (il coefficiente di Jaccard) e regolano il numero di cluster in modo che i record all’interno di un cluster siano simili mentre i cluster restino distinti. All’interno di ogni cluster, gli elementi che compaiono troppo raramente vengono eliminati e le transazioni vuote o quasi vuote scartate. Ciò che rimane è un dataset più piccolo e pulito che conserva comunque il comportamento fondamentale. Questi dati potati per cluster vengono poi inviati a un albero prefisso lineare – una struttura compatta, simile a un array, che memorizza i percorsi degli elementi in un ordine coerente, evitando gran parte dell’overhead di puntatori tipico dei disegni ad albero classici.
Guardare dall’alto verso il basso invece che dal basso verso l’alto
Una volta costruito l’albero prefisso lineare, CLTD-LP estrae i pattern usando una strategia top-down. Invece di partire dal fondo dell’albero e ricostruire nuovi alberi condizionali per ogni elemento, il metodo scorre dagli elementi più comuni verso il basso, utilizzando “tabelle sub-header” come riepiloghi temporanei. Queste tabelle tengono traccia di quanto spesso gli elementi compaiono insieme lungo i percorsi che includono un dato elemento, senza ricreare alberi aggiuntivi. Aggiornando i conteggi direttamente sulla struttura esistente ed evitando la ricostruzione ripetuta di sottoalberi, CLTD-LP riduce drasticamente la quantità di lavoro. In un esempio sullo stile della spesa, l’algoritmo individua rapidamente insiemi come {anacardio, salsa, marmellata} o {salsa, marmellata, burro, panna} seguendo i collegamenti nell’albero e aggregando i conteggi lungo i percorsi condivisi.
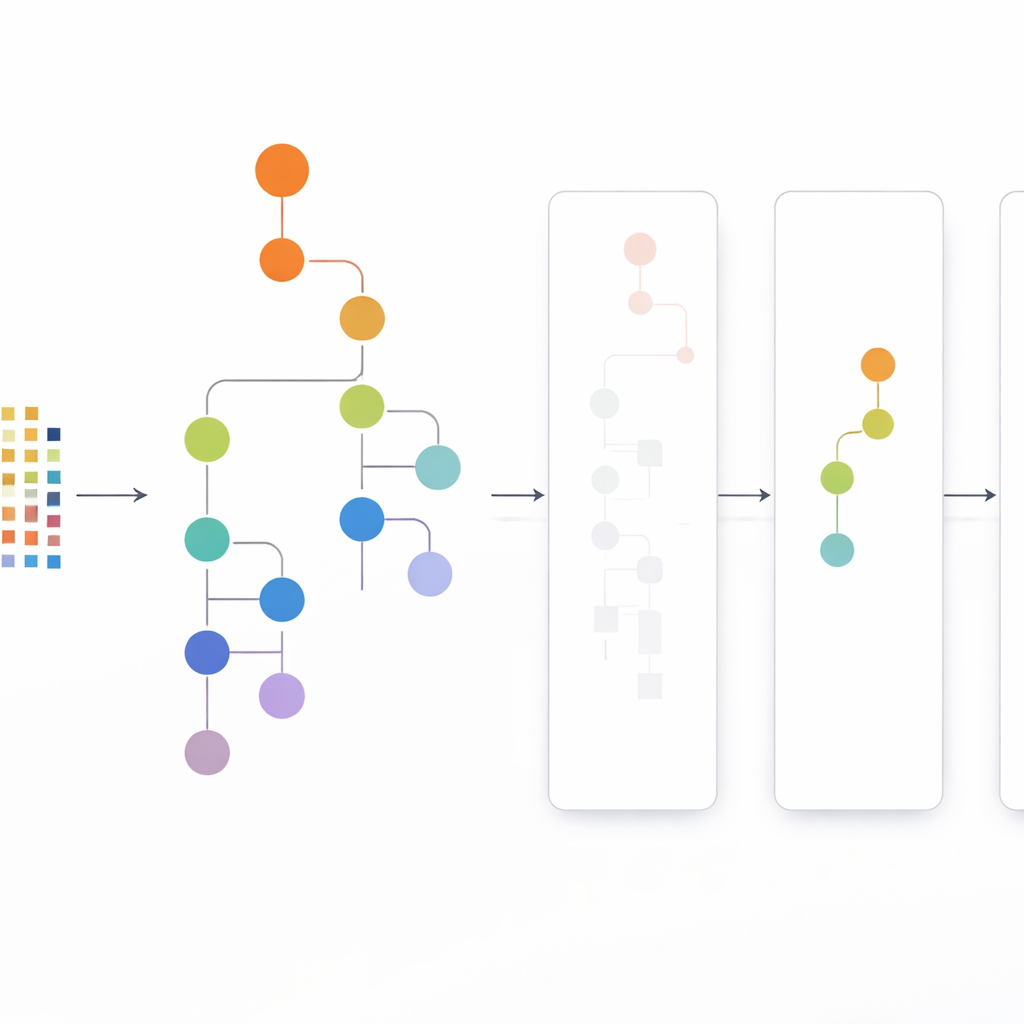
Dimostrare guadagni in velocità e memoria
Per testare il nuovo metodo, gli autori applicano CLTD-LP a tre dataset di riferimento: un database di partite di scacchi, un dataset demografico pubblico (Pumsb) e un vero dataset di shopping online costruito da loro. Per ciascun dataset variano quanto una combinazione deve essere “frequente” per essere considerata e confrontano il loro algoritmo con LP-growth, OFIM e SSFIM. Su tutti e tre, CLTD-LP completa coerentemente il lavoro in meno tempo e usando meno memoria, specialmente quando la soglia di frequenza richiesta è bassa e devono essere esplorati molti itemset. Gli autori supportano queste osservazioni con esecuzioni ripetute, una scelta attenta dei parametri di clustering e test statistici che mostrano come i miglioramenti non siano dovuti al caso.
Cosa significa per il data mining nel mondo reale
In termini semplici, CLTD-LP offre un modo più efficiente di trovare combinazioni significative in grandi raccolte di record. Raggruppando prima le transazioni simili, eliminando elementi improbabili e poi esplorando un albero semplificato dall’alto verso il basso, il metodo evita gran parte degli sprechi osservati negli algoritmi più vecchi. Per aziende e ricercatori che si confrontano con volumi crescenti di log e dati di transazione, ciò significa analisi più rapide e un ingombro di memoria minore, senza sacrificare l’accuratezza. L’approccio richiede comunque una messa a punto attenta dei parametri di clustering, ma indica la strada verso strumenti scalabili in grado di tenere il passo con le tracce digitali in continua espansione della vita moderna.
Citazione: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Parole chiave: estrazione di itemset frequenti, algoritmi di data mining, analisi del carrello della spesa, scoperta di pattern, metodi di clustering