Clear Sky Science · pt
CLTD-LP: uma abordagem de agrupamento top-down otimizada com árvores de prefixo lineares para descoberta escalável de padrões frequentes em grandes conjuntos de dados
Encontrando padrões ocultos em dados do dia a dia
Cada vez que compramos online, jogamos ou usamos um serviço digital, deixamos um rastro de cliques e escolhas. Enterrados nesses rastros estão padrões recorrentes que podem revelar quais produtos são frequentemente comprados juntos, quais eventos de sistema tendem a preceder uma falha ou como as pessoas se comportam em um site. Este artigo apresenta um novo algoritmo de computador, chamado CLTD-LP, projetado para detectar rapidamente essas combinações repetidas e usando menos memória, mesmo em conjuntos de dados muito grandes e complexos.
Por que combinações repetidas importam
Organizações modernas coletam enormes registros de eventos: compras de supermercado, sessões em sites, conexões de rede, prontuários médicos e muito mais. Uma tarefa básica na análise de dados é descobrir “conjuntos de itens frequentes” – grupos de itens que tendem a aparecer juntos em muitos registros, como geleia, molho e manteiga em uma cesta de supermercado, ou um conjunto de cliques comumente feitos durante uma sessão de compras online. Esses grupos são a matéria‑prima para motores de recomendação, detecção de fraude, análise de acidentes de trânsito e descobertas biológicas. No entanto, à medida que os dados crescem, métodos tradicionais para encontrar tais padrões podem ficar dolorosamente lentos e exigir grandes quantidades de memória.
Limites de métodos de mineração anteriores
Gerações anteriores de algoritmos, como Apriori e FP-growth, percorrem conjuntos de dados para construir estruturas que acompanham quais itens coocorrem. O Apriori funciona de baixo para cima gerando e testando muitas combinações candidatas, cujo número pode explodir. O FP-growth melhora isso construindo uma árvore especial que comprime partes repetidas das transações, mas ainda depende de reconstruir repetidamente as chamadas árvores condicionais e bases de padrão para cada item. Variantes mais recentes, incluindo LP-growth, OFIM e SSFIM, tentam agilizar essas etapas, mas continuam a enfrentar dificuldades quando os conjuntos de dados são ao mesmo tempo grandes e esparsos, com muitos itens raros e transações longas e variadas.
Agrupar primeiro, depois uma árvore mais inteligente
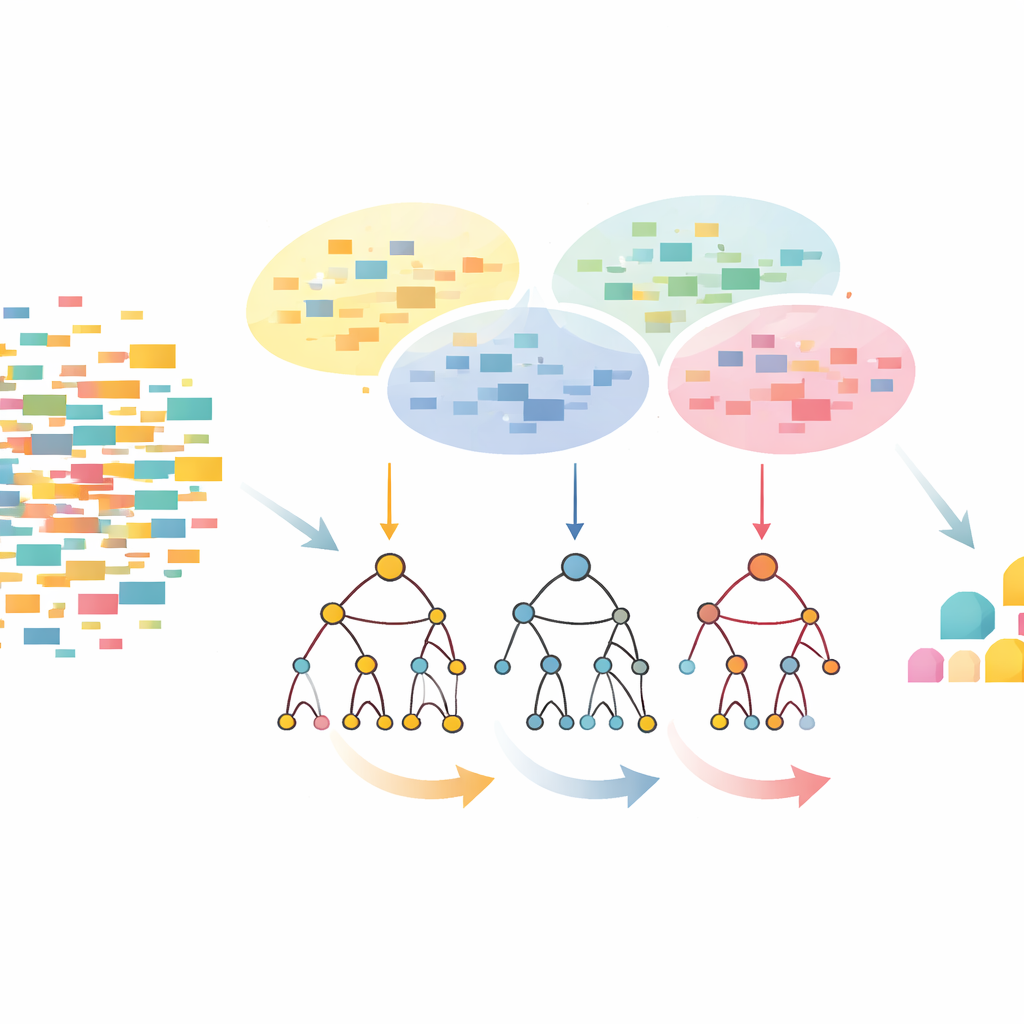
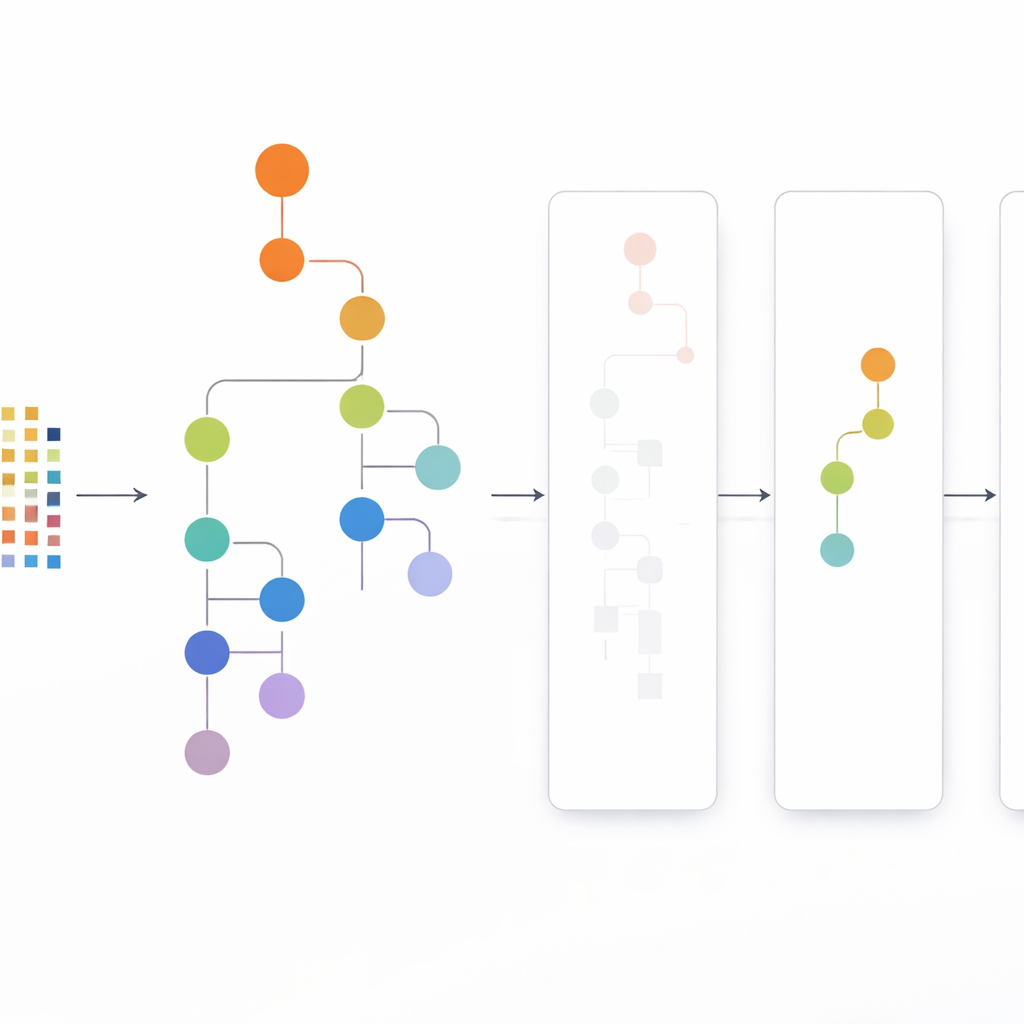
A abordagem CLTD-LP começa remodelando o conjunto de dados antes de construir qualquer árvore. Ela trata cada transação, como uma cesta de compras ou sessão de usuário, como um padrão simples de liga/desliga dos itens e agrupa transações semelhantes usando agrupamento (clustering). Os autores usam uma medida comum de similaridade (o coeficiente de Jaccard) e ajustam o número de clusters para que os registros dentro de um cluster sejam parecidos, enquanto clusters diferentes permanecem distintos. Dentro de cada cluster, itens que aparecem raramente são podados e transações vazias ou quase vazias são descartadas. O que sobra é um conjunto de dados menor e mais limpo que preserva o comportamento central. Esses dados podados por cluster alimentam então uma árvore de prefixo linear – uma estrutura compacta, semelhante a um array, que armazena caminhos de itens em uma ordem consistente, evitando grande parte da sobrecarga de ponteiros dos desenhos clássicos de árvore.
Olhando de cima para baixo em vez de baixo para cima
Uma vez construída a árvore de prefixo linear, o CLTD-LP extrai padrões usando uma estratégia top‑down. Em vez de começar pelo fundo da árvore e reconstruir novas árvores condicionais para cada item, o método percorre a partir dos itens mais comuns para baixo, usando “tabelas sub‑cabeçalho” como resumos temporários. Essas tabelas registram com que frequência itens aparecem juntos ao longo dos caminhos que incluem um dado item, sem recriar árvores adicionais. Ao atualizar contagens diretamente na estrutura existente e evitar a reconstrução repetida de subárvores, o CLTD-LP reduz drasticamente a quantidade de trabalho. Em um exemplo no estilo supermercado, o algoritmo rapidamente revela conjuntos como {castanha de caju, molho, geleia} ou {molho, geleia, manteiga, creme} seguindo links pela árvore e agregando contagens ao longo de caminhos compartilhados.
Provando ganhos de velocidade e memória
Para testar o novo método, os autores aplicam o CLTD-LP a três conjuntos de dados de referência: um banco de dados de partidas de xadrez, um conjunto demográfico público (Pumsb) e um conjunto real de compras online que eles construíram. Para cada conjunto, variam o quão “frequente” um padrão deve ser para ser considerado e comparam seu algoritmo com LP-growth, OFIM e SSFIM. Em todos os três, o CLTD-LP conclui consistentemente seu trabalho em menos tempo e usa menos memória, especialmente quando o limite de frequência exigido é baixo e muitos conjuntos de itens precisam ser explorados. Os autores sustentam essas observações com execuções repetidas, escolha cuidadosa dos parâmetros de agrupamento e testes estatísticos que mostram que as melhorias não se devem ao acaso.
O que isso significa para a mineração de dados no mundo real
Em termos simples, o CLTD-LP oferece uma maneira mais eficiente de encontrar combinações significativas em grandes coleções de registros. Ao primeiro agrupar transações semelhantes, podar itens improváveis e então explorar uma árvore simplificada de cima para baixo, o método evita grande parte do desperdício observado em algoritmos mais antigos. Para empresas e pesquisadores que lidam com volumes crescentes de logs e dados de transações, isso significa análises mais rápidas e menor uso de memória, sem sacrificar a precisão. A abordagem ainda exige ajuste cuidadoso dos parâmetros de agrupamento, mas aponta para ferramentas escaláveis capazes de acompanhar os rastros digitais em constante expansão da vida moderna.
Citação: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Palavras-chave: mineração de conjuntos frequentes, algoritmos de mineração de dados, análise de cestas de compras, descoberta de padrões, métodos de agrupamento