Clear Sky Science · de
CLTD-LP: ein optimierter Top‑Down‑Clustering‑Ansatz mit linearen Präfixbäumen zur skalierbaren Entdeckung häufiger Muster in großen Datensätzen
Muster entdecken, die im Alltagsdaten verborgen sind
Jedes Mal, wenn wir online einkaufen, ein Spiel spielen oder einen digitalen Dienst nutzen, hinterlassen wir eine Spur von Klicks und Entscheidungen. In diesen Spuren verbergen sich wiederkehrende Muster, die zeigen können, welche Produkte oft zusammen gekauft werden, welche Systemereignisse häufig einem Ausfall vorausgehen oder wie sich Menschen auf einer Website verhalten. Dieser Beitrag stellt einen neuen Algorithmus vor, genannt CLTD‑LP, der darauf ausgelegt ist, diese wiederholten Kombinationen schnell und mit geringerem Speicherbedarf zu erkennen – selbst in sehr großen und komplexen Datensätzen.
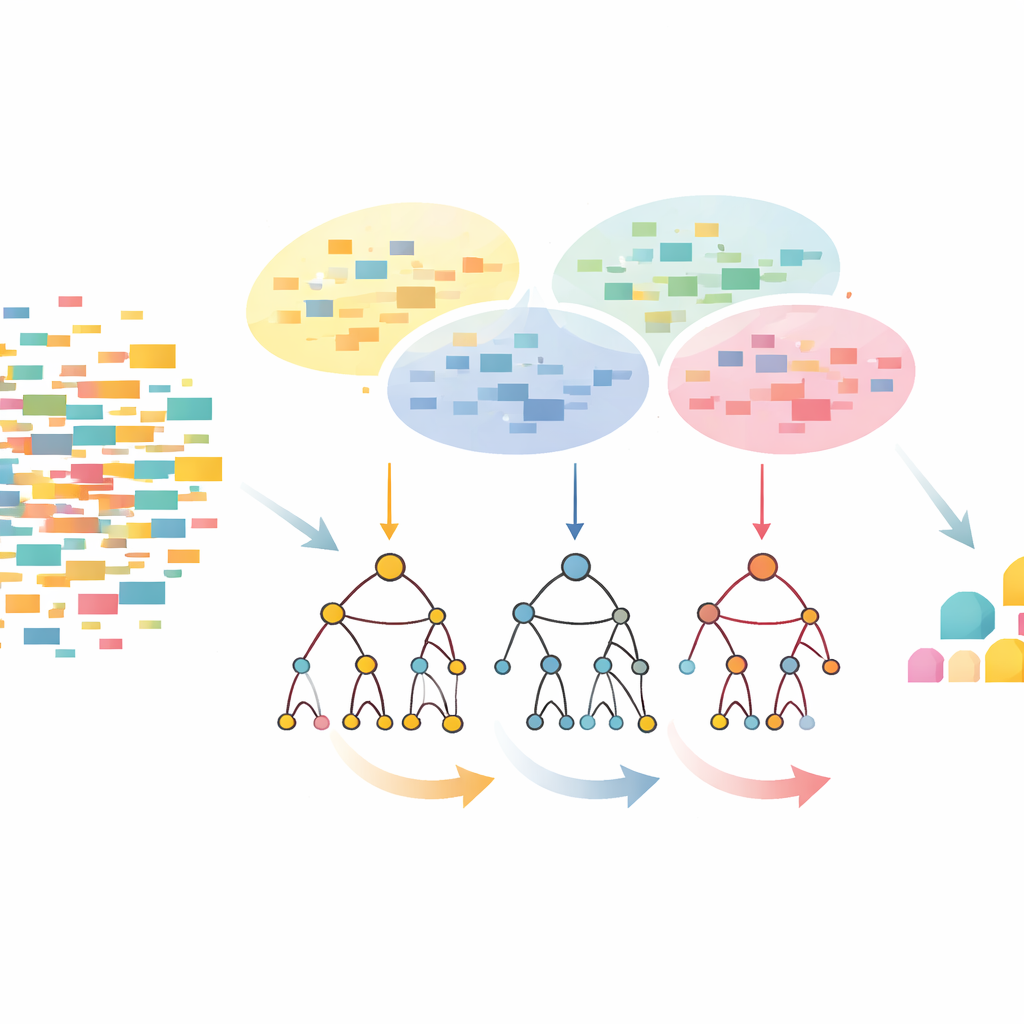
Warum wiederkehrende Kombinationen wichtig sind
Moderne Organisationen sammeln enorme Protokolle von Ereignissen: Lebensmitteleinkäufe, Website‑Sitzungen, Netzwerkverbindungen, medizinische Datensätze und mehr. Eine grundlegende Aufgabe der Datenanalyse ist es, „häufige Itemsets“ zu entdecken – Gruppen von Elementen, die dazu neigen, zusammen in vielen Datensätzen aufzutreten, etwa Marmelade, Soße und Butter im Einkaufswagen oder eine Abfolge von Klicks während einer Online‑Einkaufssitzung. Diese Gruppen sind die Rohbasis für Empfehlungssysteme, Betrugserkennung, Analyse von Verkehrsunfällen und biologische Entdeckungen. Mit wachsendem Datenvolumen können klassische Methoden zur Mustererkennung jedoch sehr langsam werden und viel Speicher benötigen.
Grenzen früherer Mining‑Methoden
Frühere Algorithmus‑Generationen wie Apriori und FP‑growth durchlaufen Datensätze, um Strukturen zu bauen, die dokumentieren, welche Elemente gemeinsam vorkommen. Apriori arbeitet bottom‑up, indem viele Kandidatenkombinationen erzeugt und geprüft werden, was in einer explosionsartigen Zunahme der Kombinationen enden kann. FP‑growth verbessert das, indem ein spezieller Baum wiederholte Teile von Transaktionen komprimiert, doch es beruht weiterhin darauf, für jedes Element so genannte konditionale Bäume und Pattern‑Basen wiederholt aufzubauen. Neuere Varianten, darunter LP‑growth, OFIM und SSFIM, versuchen diese Schritte zu straffen, kämpfen aber weiterhin, wenn Datensätze sowohl groß als auch dünn besetzt sind – viele Elemente selten vorkommen und Transaktionen lang und heterogen sind.
Zuerst Clustern, dann ein schlauerer Baum
Der CLTD‑LP‑Ansatz beginnt damit, den Datensatz umzustrukturieren, bevor ein Baum gebaut wird. Jede Transaktion, etwa ein Einkaufswagen oder eine Sitzung, wird als einfaches An‑/Aus‑Muster von Elementen betrachtet und ähnliche Transaktionen werden per Clustering gruppiert. Die Autoren verwenden ein gebräuchliches Ähnlichkeitsmaß (den Jaccard‑Koeffizienten) und passen die Clusteranzahl so an, dass Datensätze innerhalb eines Clusters sich ähneln, während verschiedene Cluster deutlich verschieden bleiben. Innerhalb jedes Clusters werden sehr selten auftretende Elemente abgeschnitten und leere oder fast leere Transaktionen verworfen. Übrig bleibt ein kleinerer, sauberer Datensatz, der das Kernverhalten bewahrt. Diese bereinigten, clusterweisen Daten werden dann in einen linearen Präfixbaum gespeist – eine kompakte, arrayähnliche Struktur, die Pfade von Elementen in einer konsistenten Reihenfolge speichert und viel des Zeiger‑Overheads klassischer Baumdesigns vermeidet.
Von oben nach unten statt von unten nach oben schauen
Sobald der lineare Präfixbaum aufgebaut ist, extrahiert CLTD‑LP Muster mit einer Top‑Down‑Strategie. Anstatt am unteren Ende des Baums zu beginnen und für jedes Element neue konditionale Bäume zu rekonstruieren, geht die Methode von den häufigsten Elementen aus nach unten und nutzt „Sub‑Header‑Tabellen“ als temporäre Zusammenfassungen. Diese Tabellen halten fest, wie oft Elemente zusammen entlang der Pfade auftreten, die ein gegebenes Element enthalten, ohne zusätzliche Bäume neu zu erzeugen. Durch direktes Aktualisieren der Zählungen auf der vorhandenen Struktur und das Vermeiden wiederholten Neubauens von Teilbäumen reduziert CLTD‑LP den Arbeitsaufwand deutlich. In einem lebensmittelorientierten Beispiel fördert der Algorithmus schnell Mengen wie {Cashew, Soße, Marmelade} oder {Soße, Marmelade, Butter, Sahne} zutage, indem er Links durch den Baum folgt und Zählungen entlang gemeinsamer Pfade aggregiert.
Beschleunigungs‑ und Speichergewinne belegen
Um die neue Methode zu prüfen, wenden die Autoren CLTD‑LP auf drei Benchmark‑Datensätze an: eine Schachdatenbank, einen öffentlichen demografischen Datensatz (Pumsb) und einen realen Online‑Einkaufsdatensatz, den sie zusammengestellt haben. Für jeden Datensatz variieren sie die Mindesthäufigkeit, die ein Muster erreichen muss, und vergleichen ihren Algorithmus mit LP‑growth, OFIM und SSFIM. In allen drei Fällen beendet CLTD‑LP die Arbeit durchgehend in weniger Zeit und mit geringerem Speicherbedarf, besonders wenn die geforderte Frequenzschwelle niedrig ist und viele Itemsets untersucht werden müssen. Die Autoren stützen diese Beobachtungen auf wiederholte Läufe, eine sorgfältige Wahl der Clustering‑Einstellungen und statistische Tests, die zeigen, dass die Verbesserungen nicht zufällig sind.
Was das für das reale Data‑Mining bedeutet
Vereinfacht gesagt bietet CLTD‑LP eine effizientere Möglichkeit, sinnvolle Kombinationen in großen Datensammlungen zu finden. Durch das vorherige Gruppieren ähnlicher Transaktionen, das Entfernen unwahrscheinlicher Elemente und das anschließende Durchsuchen eines gestrafften Baums von oben nach unten vermeidet die Methode vieles von dem Aufwand, der bei älteren Algorithmen anfällt. Für Unternehmen und Forscher, die mit wachsenden Mengen an Log‑ und Transaktionsdaten arbeiten, bedeutet das schnellere Analysen und geringere Speicheranforderungen, ohne Genauigkeit einzubüßen. Der Ansatz erfordert weiterhin eine sorgfältige Abstimmung der Clustering‑Parameter, bietet aber einen Weg zu skalierbaren Werkzeugen, die mit den ständig wachsenden digitalen Spuren des modernen Lebens Schritt halten können.
Zitation: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Schlüsselwörter: Mining häufiger Itemsets, Data‑Mining‑Algorithmen, Einkaufswagenanalyse, Mustererkennung, Clustering‑Methoden