Clear Sky Science · tr
CLTD-LP: büyük veri kümelerinde ölçeklenebilir sık örüntü keşfi için doğrusal önek ağaçlarıyla optimize edilmiş yukarıdan aşağı kümeleme yaklaşımı
Günlük Veride Gizli Örüntüleri Bulmak
Çevrimiçi alışveriş yaptığımızda, bir oyun oynadığımızda veya dijital bir hizmet kullandığımızda geride tıklamalar ve tercihlerin bir izi kalır. Bu izlerin içinde, hangi ürünlerin sık birlikte satın alındığını, hangi sistem olaylarının bir arızadan önce geldiğini veya insanların bir web sitesinde nasıl davrandığını ortaya çıkarabilecek tekrar eden örüntüler gizlidir. Bu makale, çok büyük ve karmaşık veri kümelerinde bile bu tekrarlayan kombinasyonları hızlı ve daha az bellekle tespit etmek üzere tasarlanmış CLTD-LP adında yeni bir bilgisayar algoritmasını tanıtıyor.
Neden Tekrarlayan Kombinasyonlar Önemlidir
Modern kuruluşlar, büyük miktarda işlem günlüğü toplar: market alışverişleri, web oturumları, ağ bağlantıları, tıbbi kayıtlar ve daha fazlası. Veri analizinde temel bir görev, birçok kayıtta birlikte ortaya çıkma eğiliminde olan “sık öğe kümelerini” keşfetmektir; örneğin bir market sepetinde reçel, sos ve tereyağı gibi veya çevrimiçi alışveriş sırasında sık yapılan bir dizi tıklama. Bu kümeler öneri motorları, dolandırıcılık tespiti, trafik kazası analizi ve biyolojik keşif için hammadde sağlar. Ancak veri büyüdükçe, bu tür örüntüleri bulmaya yönelik geleneksel yöntemler yavaşlayabilir ve büyük miktarda bellek gerektirebilir.
Önceki Madencilik Yöntemlerinin Sınırlılıkları
Apriori ve FP-growth gibi önceki nesil algoritmalar, hangi öğelerin birlikte göründüğünü izleyen yapılar oluşturmak için veri kümelerini tarar. Apriori, birçok aday kombinasyonu üreterek ve test ederek aşağıdan yukarıya çalışır; bu sayılar hızla patlayabilir. FP-growth, işlemlerin tekrarlayan kısımlarını sıkıştıran özel bir ağaç inşa ederek iyileştirme sağlar, ancak yine de her öğe için tekrar tekrar koşullu ağaçlar ve örüntü tabanları oluşturmayı gerektirir. LP-growth, OFIM ve SSFIM gibi daha yeni varyantlar bu adımları düzene sokmaya çalışsa da, birçok öğenin nadir ve işlemlerin uzun ve çeşitli olduğu büyük ve seyrek veri kümelerinde hâlâ zorlanırlar.
Önce Kümeleme, Sonra Daha Akıllı Bir Ağaç
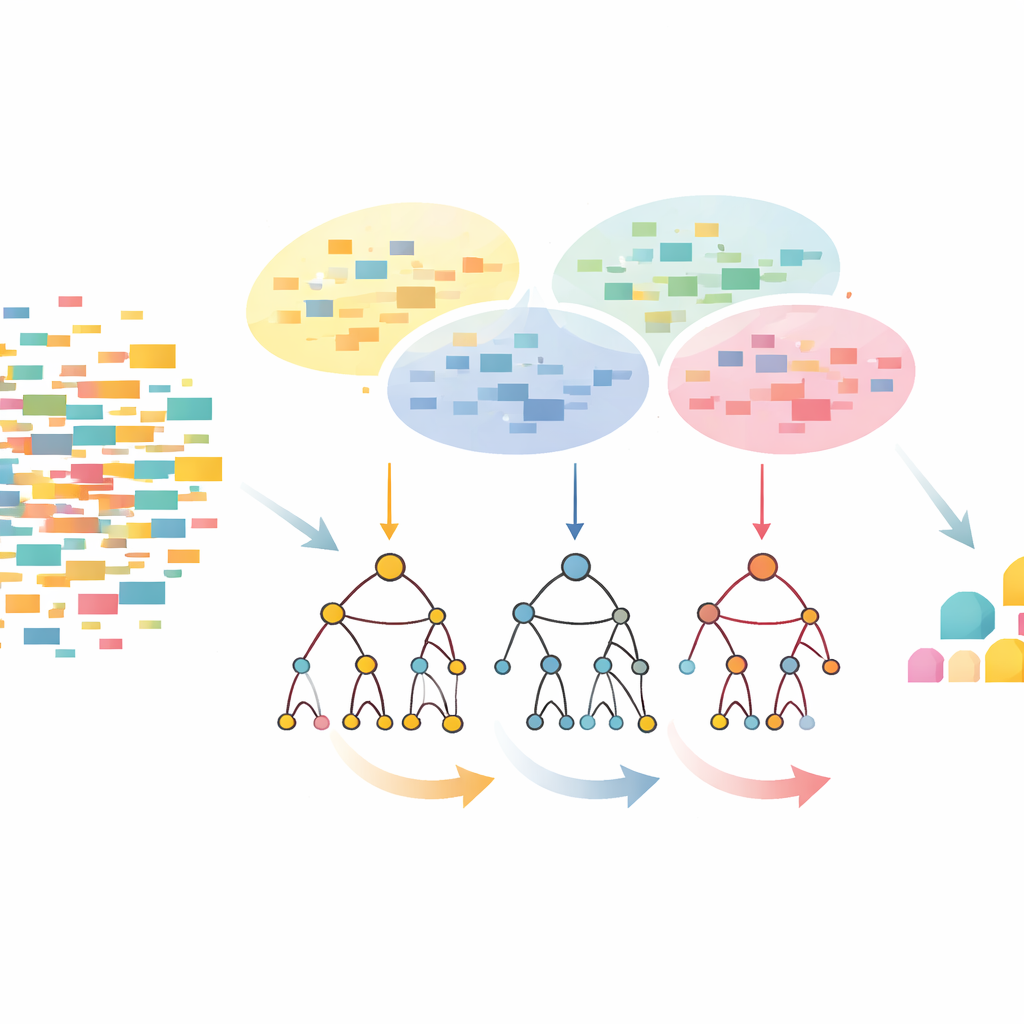
CLTD-LP yaklaşımı herhangi bir ağaç inşa edilmeden önce veri kümesini yeniden şekillendirerek başlar. Her işlemi, örneğin bir market sepeti veya kullanıcı oturumunu, öğelerin açık-kapalı bir deseni olarak ele alır ve benzer işlemleri kümeleme ile gruplar. Yazarlar ortak bir benzerlik ölçüsü (Jaccard katsayısı) kullanır ve bir küme içindeki kayıtların benzer, farklı kümelerin ise birbirinden ayrı kalmasını sağlayacak şekilde küme sayısını ayarlar. Her küme içinde nadiren görülen öğeler budanır ve boş veya neredeyse boş işlemler atılır. Geriye kalan, çekirdeksel davranışı koruyan daha küçük, daha temiz bir veri setidir. Bu budanmış, küme bazlı veri daha sonra öğe yollarını tutarlı bir sıra halinde depolayan ve klasik ağaç tasarımlarının işaretçi yükünün çoğundan kaçınan doğrusal önek ağaca beslenir.
Aşağıdan Yukarıya Değil, Yukarıdan Aşağıya Bakmak
Doğrusal önek ağaç oluşturulduktan sonra CLTD-LP örüntüleri yukarıdan aşağıya bir stratejiyle keşfeder. Ağacın altından başlayıp her öğe için yeni koşullu ağaçlar yeniden oluşturmak yerine yöntem, en yaygın öğelerden aşağı doğru yürür ve geçici özetler olarak “alt-başlık tabloları” kullanır. Bu tablolar, ekstra ağaçlar yeniden oluşturmadan, belirli bir öğeyi içeren yollar boyunca öğelerin ne sıklıkla birlikte göründüğünü takip eder. Sayımları mevcut yapı üzerinde doğrudan güncelleyerek ve alt ağaçları yeniden inşa etmekten kaçınarak CLTD-LP iş miktarını önemli ölçüde azaltır. Market tarzı bir örnekte, algoritma ağacın bağlantılarını takip edip paylaşılan yollar boyunca sayımları toplayarak {fıstık, sos, reçel} veya {sos, reçel, tereyağı, krema} gibi kümelemeleri hızlıca ortaya çıkarır.
Hız ve Bellek Kazançlarını Kanıtlamak
Yeni yöntemi test etmek için yazarlar CLTD-LP’yi üç kıyaslama veri kümesine uygular: bir satranç oyunu veritabanı, halka açık demografik bir veri kümesi (Pumsb) ve onların oluşturduğu gerçek bir çevrimiçi alışveriş veri kümesi. Her veri kümesi için bir örüntünün sayılabilmesi için gereken “sıklık” eşiğini değiştirir ve algoritmalarını LP-growth, OFIM ve SSFIM ile karşılaştırırlar. Üçünün tamamında CLTD-LP tutarlı şekilde daha az zamanda işi bitirir ve daha az bellek kullanır; özellikle gerekli sıklık eşiği düşükse ve çok sayıda öğe kümesi keşfedilmek zorundaysa. Yazarlar bu gözlemleri tekrar edilen koşuşlar, dikkatli kümeleme ayarları seçimi ve iyileşmelerin tesadüfe bağlı olmadığını gösteren istatistiksel testlerle destekler.
Gerçek Dünya Veri Madenciliği İçin Anlamı
Basitçe söylemek gerekirse, CLTD-LP büyük kayıt koleksiyonlarında anlamlı kombinasyonları bulmak için daha verimli bir yol sunar. Önce benzer işlemleri gruplayarak, olası olmayan öğeleri budayarak ve ardından yukarıdan aşağıya sadeleştirilmiş bir ağacı keşfederek yöntem, eski algoritmalarda görülen israfın çoğundan kaçınır. Büyüyen günlük ve işlem verileriyle uğraşan şirketler ve araştırmacılar için bu, doğruluktan ödün vermeden daha hızlı analizler ve daha küçük bellek ayak izleri anlamına gelir. Yöntem hâlâ kümeleme ayarlarının dikkatle ayarlanmasını gerektirir, ancak modern yaşamın giderek genişleyen dijital izleriyle başa çıkabilecek ölçeklenebilir araçlara doğru bir işaret sunar.
Atıf: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Anahtar kelimeler: sık öğe kümesi madenciliği, veri madenciliği algoritmaları, alışveriş sepeti analizi, örüntü keşfi, kümeleme yöntemleri