Clear Sky Science · ar
CLTD-LP: نهج تجميع مُحسَّن من الأعلى للأسفل مع أشجار بادئات خطية لاكتشاف الأنماط المتكررة القابلة للتوسع في مجموعات بيانات كبيرة
اكتشاف الأنماط المختبئة في البيانات اليومية
في كل مرة نتسوق عبر الإنترنت أو نلعب لعبة أو نستخدم خدمة رقمية، نترك أثرًا من النقرات والاختيارات. مدفونًا في هذه الآثار توجد أنماط متكررة قد تكشف أي المنتجات تُشترى معًا في كثير من الأحيان، أو أي أحداث نظام تسبق عادة فشلًا، أو كيف يتصرف الأشخاص على موقع ويب. تقدم هذه الورقة خوارزمية جديدة تسمى CLTD-LP، مصممة لاكتشاف هذه التراكيب المتكررة بسرعة وبذاكرة أقل، حتى في مجموعات بيانات كبيرة ومعقدة جدًا.
لماذا تهم التوليفات المتكررة
تجمع المؤسسات الحديثة سجلات هائلة من الأحداث: مشتريات البقالة، جلسات الويب، الاتصالات الشبكية، السجلات الطبية، وغيرها. مهمة أساسية في تحليل البيانات هي اكتشاف «مجموعات العناصر المتكررة» — مجموعات من العناصر التي تميل للظهور معًا في كثير من السجلات، مثل المربى والصلصة والزبدة في سلة البقالة، أو مجموعة من النقرات الشائعة أثناء جلسة تسوق عبر الإنترنت. هذه المجموعات هي المادة الخام لمحركات التوصية، واكتشاف الاحتيال، وتحليل حوادث المرور، والاكتشافات البيولوجية. ومع ذلك، مع نمو البيانات تصبح الأساليب التقليدية للعثور على هذه الأنماط بطيئة ومتطلبة لذاكرة كبيرة.
حدود طرق التنقيب السابقة
أجيال سابقة من الخوارزميات، مثل Apriori وFP-growth، تمر عبر مجموعات البيانات لبناء هياكل تتتبع تكرار co-occurrence للعناصر. تعمل Apriori من الأسفل إلى الأعلى عن طريق توليد واختبار العديد من التركيبات الممكنة، والتي قد تتضخم أعدادها. يحسن FP-growth ذلك ببناء شجرة خاصة تضغط الأجزاء المتكررة من المعاملات، لكنه ما يزال يعتمد على بناء ما يُسمى الأشجار الشرطية وقواعد الأنماط لكل عنصر بشكل متكرر. تحاول متغيرات أحدث، بما في ذلك LP-growth وOFIM وSSFIM، تبسيط هذه الخطوات، لكنها تستمر في مواجهة صعوبات عندما تكون المجموعات الكبيرة متناثرة، حيث تكون العديد من العناصر نادرة والمعاملات طويلة ومتنوعة.
التجميع أولًا، ثم شجرة أذكى
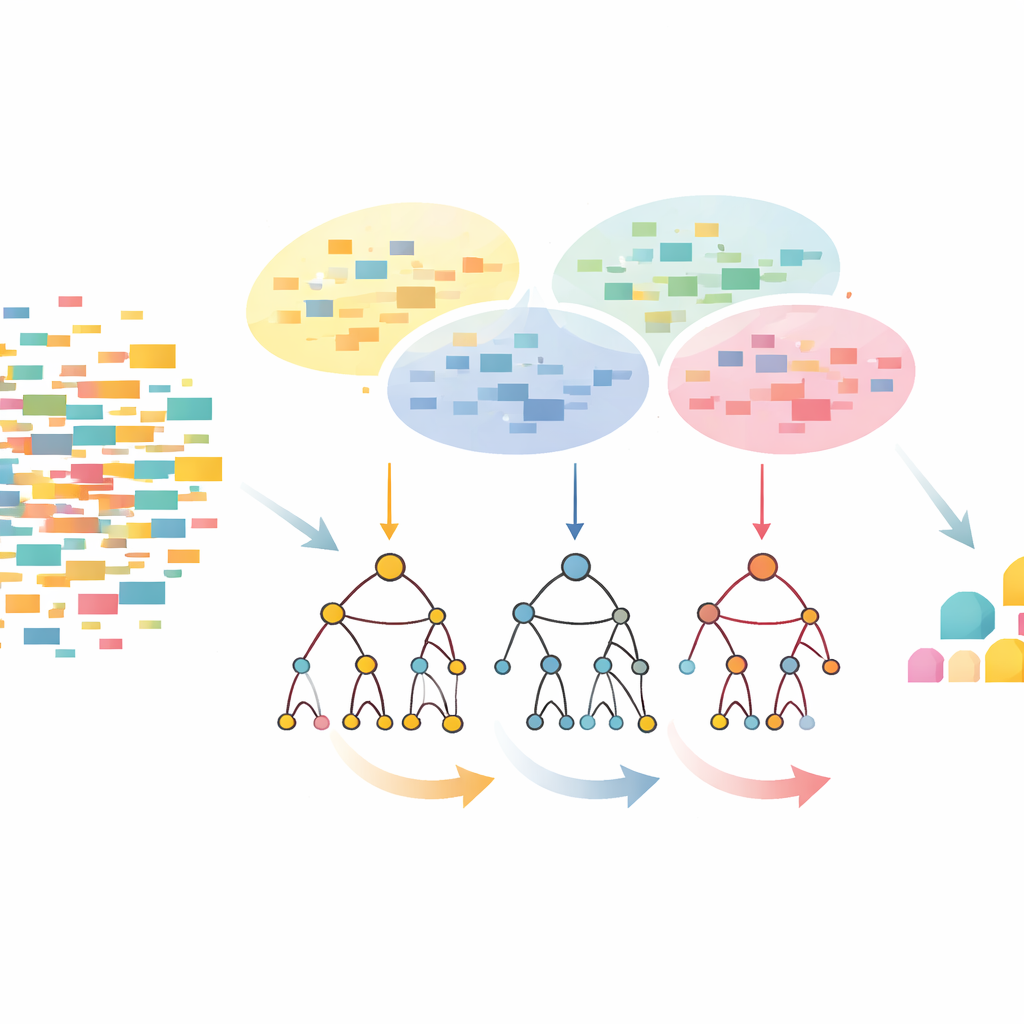
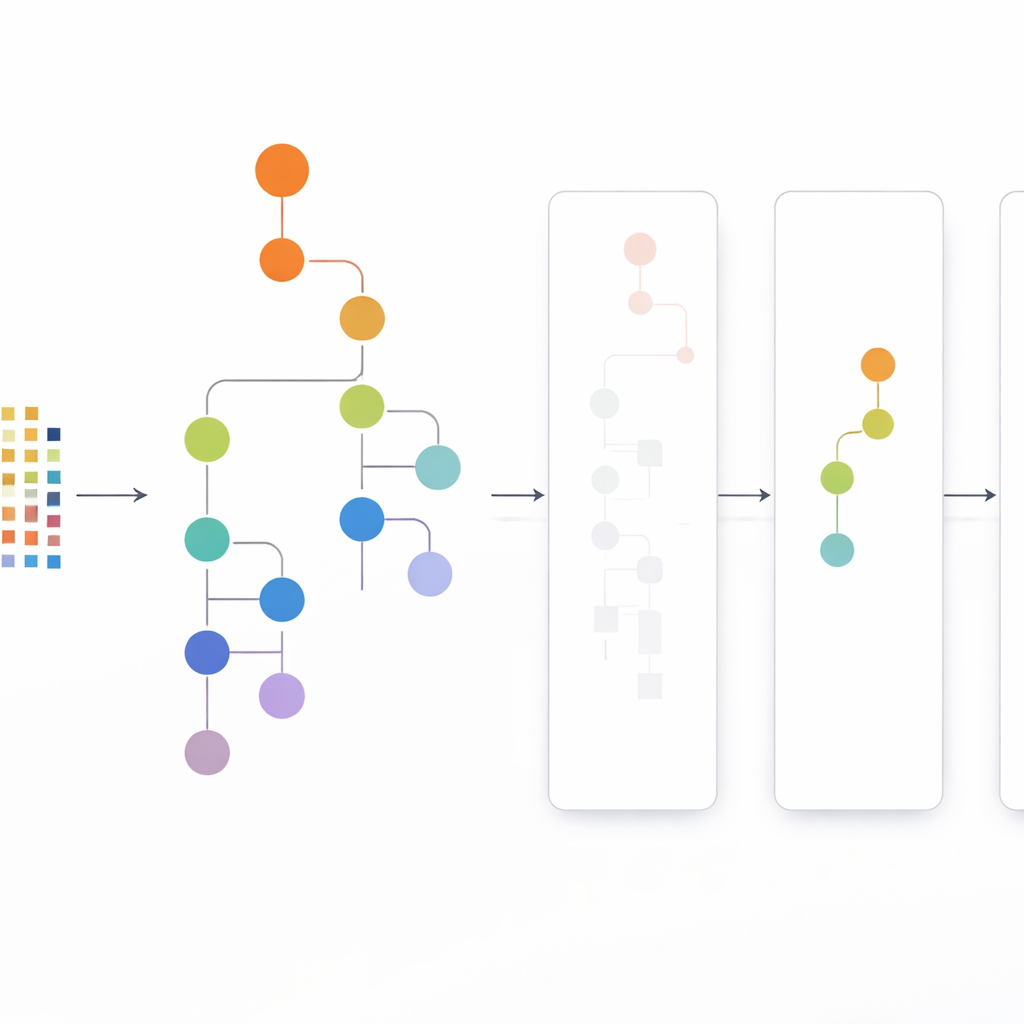
تبدأ مقاربة CLTD-LP بإعادة تشكيل مجموعة البيانات قبل بناء أي شجرة. تعامل كل معاملة، مثل سلة تسوق أو جلسة مستخدم، كنمط تشغيل/إيقاف بسيط للعناصر وتجمع المعاملات المتشابهة باستخدام التجميع. يستخدم المؤلفون مقياس التشابه الشائع (معامل جاكسارد) ويضبطون عدد العناقيد بحيث تكون السجلات داخل العنقود متشابهة بينما تبقى العناقيد مختلفة. داخل كل عنقود، تُقصى العناصر التي تظهر بندرة كبيرة، وتُحذف المعاملات الفارغة أو القريبة من الفراغ. يبقى بذلك مجموعة بيانات أصغر وأنظف تحافظ على السلوك الأساسي. تُغذى هذه البيانات المقطوعة على مستوى العنقود بعد ذلك في شجرة بادئات خطية — بنية مدمجة شبيهة بالمصفوفة تخزن مسارات العناصر بترتيب متسق، متفادية كثيرًا من عبء المؤشرات في تصاميم الأشجار التقليدية.
النظر من الأعلى إلى الأسفل بدلًا من الأسفل إلى الأعلى
بمجرد بناء شجرة البادئات الخطية، يستخرج CLTD-LP الأنماط باستخدام استراتيجية من الأعلى إلى الأسفل. بدلًا من البدء من أسفل الشجرة وإعادة بناء أشجار شرطية جديدة لكل عنصر، تمشي الطريقة من العناصر الأكثر شيوعًا نزولًا، مستخدمة «جداول فرعية للرؤوس» كملخصات مؤقتة. تحتفظ هذه الجداول بعدد مرات ظهور العناصر معًا على طول المسارات التي تتضمن عنصرًا معينًا، دون إعادة إنشاء أشجار إضافية. من خلال تحديث العدادات مباشرة على البنية القائمة وتجنب إعادة بناء الفروع بشكل متكرر، يخفض CLTD-LP بشكل كبير مقدار العمل. في مثال على غرار البقالة، تكشف الخوارزمية بسرعة عن مجموعات مثل {كاجو، صلصة، مربى} أو {صلصة، مربى، زبدة، كريم} باتباع الروابط عبر الشجرة وتجميع العدادات على طول المسارات المشتركة.
إثبات مكاسب السرعة والذاكرة
لاختبار الطريقة الجديدة، يطبق المؤلفون CLTD-LP على ثلاث مجموعات بيانات معيارية: قاعدة بيانات ألعاب الشطرنج، مجموعة بيانات ديموغرافية عامة (Pumsb)، ومجموعة بيانات تسوق عبر الإنترنت حقيقية قاموا ببنائها. لكل مجموعة بيانات، يغيرون عتبة «التكرار» المطلوبة لعد النمط ويقارنون خوارزميتهم مع LP-growth وOFIM وSSFIM. عبر الثلاثة، ينهي CLTD-LP عمله باستمرار في وقت أقل ويستهلك ذاكرة أقل، خصوصًا عندما تكون عتبة التكرار منخفضة ويجب استكشاف مجموعات عناصر كثيرة. يدعم المؤلفون هذه الملاحظات بتشغيلات متكررة، واختيار دقيق لإعدادات التجميع، واختبارات إحصائية تُظهر أن التحسينات ليست نتيجة صدفة.
ما يعنيه هذا لتنقيب البيانات في العالم الحقيقي
بعبارة بسيطة، يقدم CLTD-LP طريقة أكفأ لإيجاد التراكيب ذات الدلالة في مجموعات كبيرة من السجلات. من خلال تجميع المعاملات المتشابهة أولًا، وقص العناصر غير المرجحة، ثم استكشاف شجرة مبسطة من الأعلى إلى الأسفل، تتجنب الطريقة كثيرًا من الهدر الموجود في الخوارزميات القديمة. بالنسبة للشركات والباحثين الذين يتعاملون مع أحجام متزايدة من سجلات المعاملات والسجلات، يعني هذا تحليلات أسرع وبصمة ذاكرة أصغر، دون التضحية بالدقة. لا تزال الطريقة تتطلب ضبطًا دقيقًا لإعدادات التجميع، لكنها تشير إلى أدوات قابلة للتوسع قادرة على مواكبة الآثار الرقمية المتنامية للحياة الحديثة.
الاستشهاد: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
الكلمات المفتاحية: تنقيب مجموعات العناصر المتكررة, خوارزميات تنقيب البيانات, تحليل سلال التسوق, اكتشاف الأنماط, طرق التجميع