Clear Sky Science · sv
CLTD-LP: en optimerad top-down-klustringsmetod med linjära prefixträd för skalbar upptäckt av frekventa mönster i stora datamängder
Att hitta mönster dolda i vardagsdata
Varje gång vi handlar online, spelar ett spel eller använder en digital tjänst lämnar vi efter oss ett spår av klick och val. Nedgrävda i dessa spår finns återkommande mönster som kan avslöja vilka produkter som ofta köps tillsammans, vilka systemhändelser som tenderar att föregå ett fel, eller hur människor beter sig på en webbplats. Denna artikel presenterar en ny datoralgoritm, kallad CLTD-LP, utformad för att upptäcka dessa återkommande kombinationer snabbt och med mindre minnesåtgång, även i mycket stora och komplexa datamängder.
Varför upprepade kombinationer spelar roll
Moderna organisationer samlar in enorma mängder loggar: livsmedelsinköp, webbplatsessioner, nätverksanslutningar, medicinska journaler med mera. En grundläggande uppgift i dataanalys är att upptäcka ”frekventa itemsets” – grupper av saker som tenderar att förekomma tillsammans i många poster, till exempel sylt, sås och smör i en matkasse, eller en uppsättning klick som ofta görs under ett onlineköp. Dessa grupper är råmaterial för rekommendationsmotorer, bedrägeridetektion, trafikolycksanalys och biologisk upptäckt. Men när datamängderna växer kan traditionella metoder för att hitta sådana mönster bli smärtsamt långsamma och kräva stora mängder minne.
Begränsningar hos tidigare utvinningsmetoder
Tidigare generationer av algoritmer, som Apriori och FP-growth, skannar igenom datamängder för att bygga strukturer som håller reda på vilka varor som förekommer tillsammans. Apriori arbetar bottom‑up genom att generera och testa många kandidatkombinationer, vilket kan explodera i antal. FP-growth förbättrar detta genom att bygga ett särskilt träd som komprimerar upprepade delar av transaktioner, men det är fortfarande beroende av att upprepade gånger bygga så kallade villkorade träd och mönsterbaser för varje objekt. Nyare varianter, inklusive LP-growth, OFIM och SSFIM, försöker strömlinjeforma dessa steg, men de kämpar fortfarande när datamängder både är stora och glesa, där många objekt är sällsynta och transaktionerna långa och varierade.
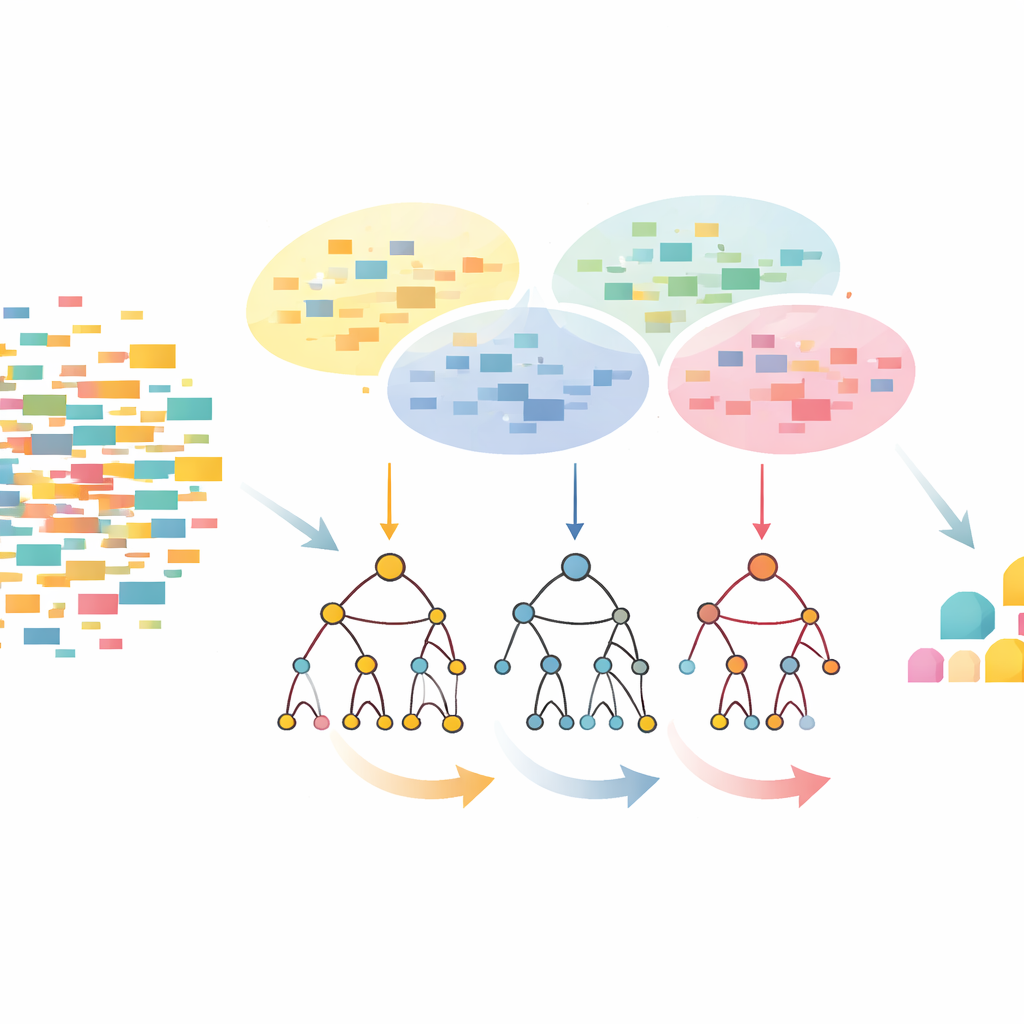
Klustra först, bygg sedan ett smartare träd
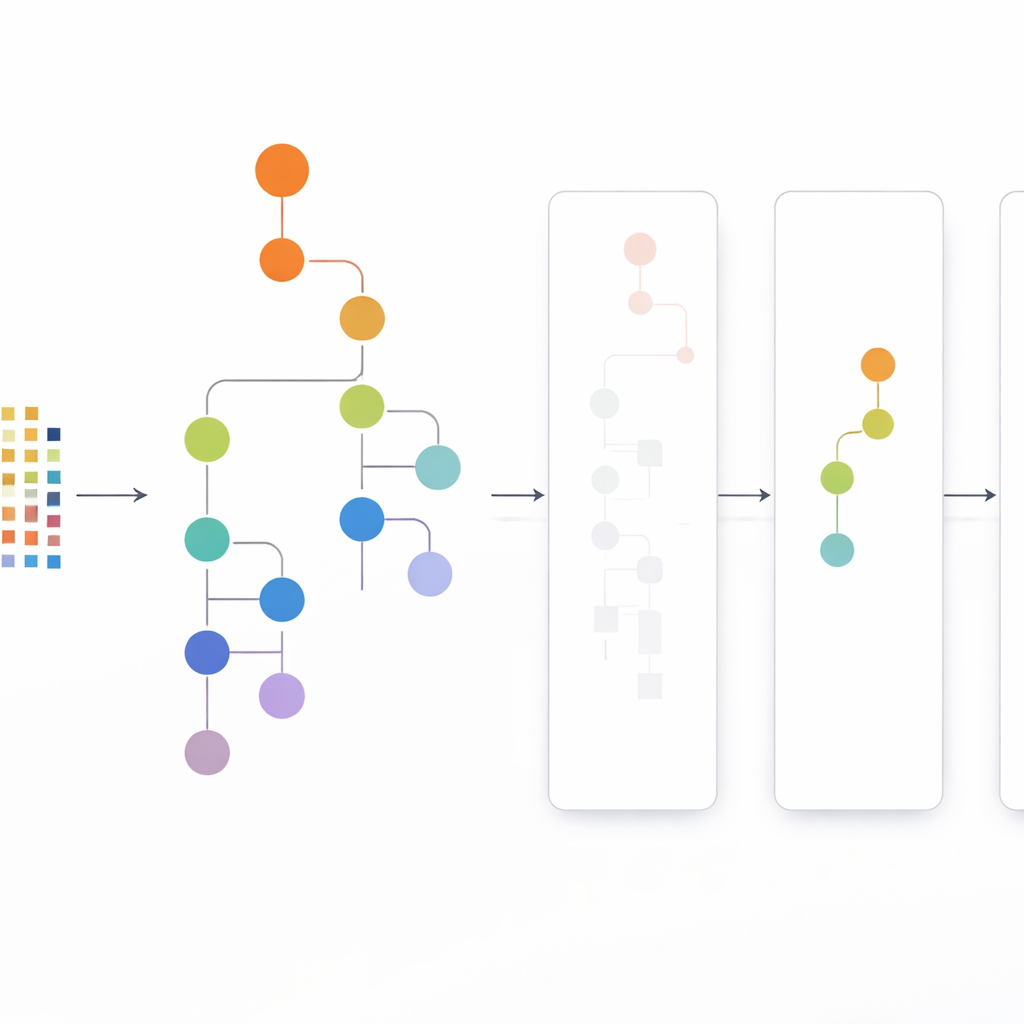
CLTD-LP‑metoden börjar med att omforma datamängden innan något träd byggs. Den behandlar varje transaktion, såsom en matkasse eller användarsession, som ett enkelt på/av‑mönster av objekt och grupperar liknande transaktioner med klustring. Författarna använder en vanlig likhetsmått (Jaccard‑koefficienten) och ställer in antalet kluster så att poster inom ett kluster är lika medan olika kluster förblir åtskilda. Inom varje kluster trunkeras objekt som förekommer för sällan bort, och tomma eller nästan tomma transaktioner kastas. Det som återstår är en mindre, renare datamängd som fortfarande bevarar kärnbeteendet. Denna beskurna, klusterspecifika data matas sedan in i ett linjärt prefixträd – en kompakt, arrayliknande struktur som lagrar sökvägar av objekt i en konsekvent ordning och undviker mycket av pekar‑overheaden hos klassiska trädstrukturer.
Att söka uppifrån och ner istället för underifrån och upp
När det linjära prefixträdet är byggt, hittar CLTD-LP mönster med en top‑down‑strategi. Istället för att börja från trädets botten och rekonstruera nya villkorade träd för varje objekt, går metoden från de vanligaste objekten nedåt och använder ”sub‑header‑tabeller” som temporära sammanfattningar. Dessa tabeller håller reda på hur ofta objekt förekommer tillsammans längs de sökvägar som inkluderar ett givet objekt, utan att återskapa extra träd. Genom att uppdatera räkningar direkt i den befintliga strukturen och undvika upprepad ombyggnad av delträd, minskar CLTD-LP dramatiskt mängden arbete. I ett matvaruexempel hittar algoritmen snabbt mängder som {cashew, sås, sylt} eller {sås, sylt, smör, grädde} genom att följa länkar genom trädet och aggregera räkningar längs delade sökvägar.
Bevis för förbättrad hastighet och minnesanvändning
För att testa den nya metoden applicerar författarna CLTD-LP på tre referensdatamängder: en schackdatabas, en offentlig demografisk datamängd (Pumsb) och en verklig online‑köpdatasats som de konstruerat. För varje datamängd varierar de hur ”frekvent” ett mönster måste vara för att räknas och jämför sin algoritm med LP‑growth, OFIM och SSFIM. I samtliga tre fall slutför CLTD-LP konsekvent sitt arbete snabbare och använder mindre minne, särskilt när den nödvändiga frekvenströskeln är låg och många itemsets måste utforskas. Författarna stöder dessa iakttagelser med upprepade körningar, noggrant val av klusterinställningar och statistiska tester som visar att förbättringarna inte beror på slumpen.
Vad detta betyder för verklig datautvinning
Enkelt uttryckt erbjuder CLTD-LP ett mer effektivt sätt att hitta meningsfulla kombinationer i stora samlingar av poster. Genom att först gruppera liknande transaktioner, ta bort osannolika objekt och sedan utforska ett strömlinjeformat träd uppifrån och ner, undviker metoden mycket av det spill som ses i äldre algoritmer. För företag och forskare som hanterar växande volymer logg‑ och transaktionsdata innebär detta snabbare analyser och mindre minnesavtryck, utan att offra noggrannheten. Metoden kräver fortfarande noggrann justering av klusterinställningar, men den pekar mot skalbara verktyg som kan hålla takt med den ständigt expanderande digitala spårmängden i det moderna livet.
Citering: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Nyckelord: frekvent itemset‑utvinning, data mining‑algoritmer, varukorgsanalys, mönsterupptäckt, klustringsmetoder