Clear Sky Science · nl
CLTD-LP: een geoptimaliseerde top-down clusteringbenadering met lineaire prefixbomen voor schaalbare ontdekking van frequente patronen in grote datasets
Patronen ontdekken die verborgen liggen in alledaagse data
Elke keer dat we online winkelen, een spel spelen of een digitale dienst gebruiken, laten we een spoor van klikken en keuzes achter. In deze sporen zitten terugkerende patronen die kunnen onthullen welke producten vaak samen worden gekocht, welke systeemgebeurtenissen vaak aan een storing voorafgaan, of hoe mensen zich op een website gedragen. Dit artikel introduceert een nieuw computeralgoritme, CLTD-LP, dat is ontworpen om deze herhalende combinaties snel en met minder geheugen te vinden, zelfs in zeer grote en complexe datasets.
Waarom terugkerende combinaties ertoe doen
Moderne organisaties verzamelen enorme logboeken met gebeurtenissen: supermarkttransacties, websitesessies, netwerkverbindingen, medische dossiers en meer. Een basistaak in data-analyse is het ontdekken van “frequente itemsets” – groepen van items die vaak samen voorkomen in veel records, zoals jam, saus en boter in een boodschappenmandje, of een reeks klikken die gewoonlijk tijdens een online winkelbeurt worden gedaan. Deze groepen vormen de grondstof voor aanbevelingssystemen, fraudeopsporing, verkeersonderzoek en biologische ontdekking. Naarmate data groeit, kunnen traditionele methoden om zulke patronen te vinden echter erg traag worden en veel geheugen vereisen.
Beperkingen van eerdere miningmethoden
Eerdere generaties algoritmen, zoals Apriori en FP-growth, scannen datasets om structuren op te bouwen die bijhouden welke items samen voorkomen. Apriori werkt bottom-up door veel kandidaatcombinaties te genereren en te testen, wat explosief kan groeien in aantal. FP-growth verbetert dit door een speciale boom te bouwen die herhaalde delen van transacties comprimeert, maar het blijft afhankelijk van het herhaaldelijk bouwen van zogenoemde conditionele bomen en patroonbases voor elk item. Recente varianten, waaronder LP-growth, OFIM en SSFIM, proberen deze stappen te stroomlijnen, maar hebben nog steeds moeite wanneer datasets zowel groot als zeldzaam zijn, met veel zeldzame items en lange, gevarieerde transacties.
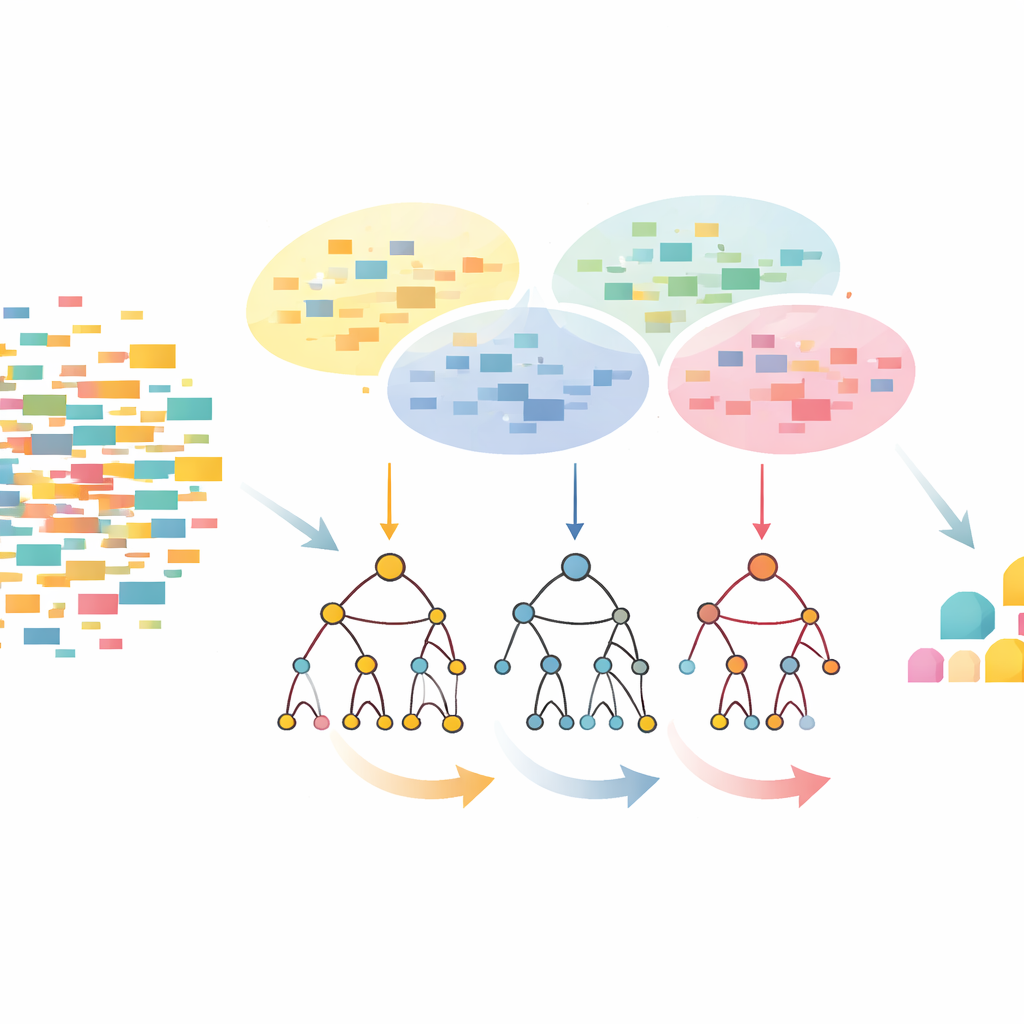
Eerst clusteren, daarna een slimmer boomontwerp
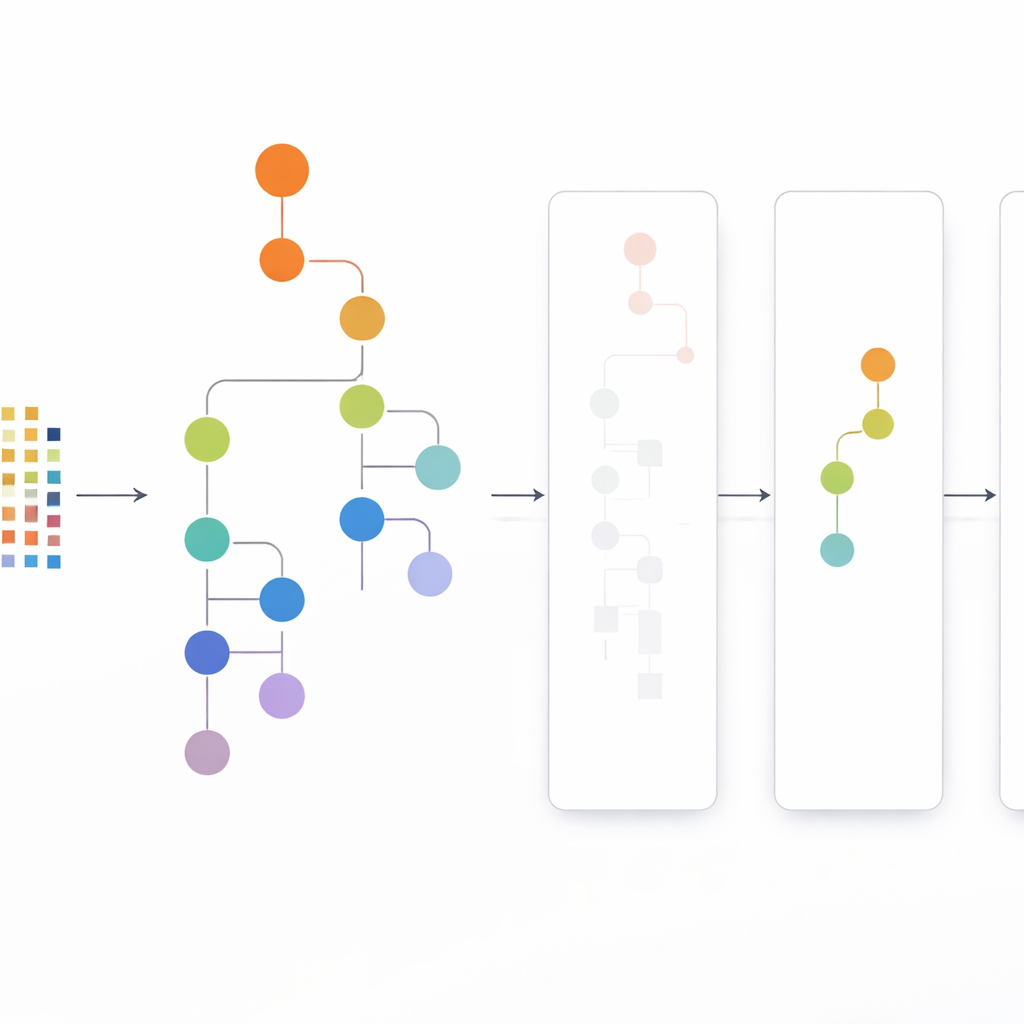
De CLTD-LP-benadering begint met het herschikken van de dataset voordat er een boom wordt gebouwd. Elke transactie, zoals een boodschappenmandje of gebruikerssessie, wordt behandeld als een eenvoudig aan/uit-patroon van items en vergelijkbare transacties worden gegroepeerd met clustering. De auteurs gebruiken een gangbare maat voor gelijkenis (de Jaccard-coëfficiënt) en stemmen het aantal clusters af zodat records binnen een cluster op elkaar lijken terwijl verschillende clusters onderscheidend blijven. Binnen elk cluster worden items die te zelden voorkomen verwijderd en lege of vrijwel lege transacties weggegooid. Wat overblijft is een kleinere, schonere dataset die het kerngedrag behoudt. Deze gesnoeide, clustergewijze data voedt vervolgens een lineaire prefixboom — een compacte, arrayachtige structuur die paden van items in een consistente volgorde opslaat en veel van de pointer-overhead van klassieke boomontwerpen vermijdt.
Top-down bekijken in plaats van bottom-up
Zodra de lineaire prefixboom is opgebouwd, zoekt CLTD-LP patronen met een top-down strategie. In plaats van te beginnen onderaan de boom en voor elk item nieuwe conditionele bomen te reconstrueren, loopt de methode van de meest voorkomende items naar beneden en gebruikt “sub-header-tabellen” als tijdelijke samenvattingen. Deze tabellen houden bij hoe vaak items samen voorkomen langs de paden die een bepaald item bevatten, zonder extra bomen opnieuw op te bouwen. Door tellen direct op de bestaande structuur bij te werken en het herhaaldelijk herbouwen van subtrees te vermijden, vermindert CLTD-LP de hoeveelheid werk drastisch. In een supermarktvoorbeeld onthult het algoritme snel sets zoals {cashew, saus, jam} of {saus, jam, boter, room} door links door de boom te volgen en aantallen langs gedeelde paden te aggregeren.
Snelheids- en geheugengewinst aantonen
Om de nieuwe methode te testen passen de auteurs CLTD-LP toe op drie benchmarkdatasets: een schaakspel-database, een openbare demografiedataset (Pumsb) en een echte online winkeldataset die ze hebben samengesteld. Voor elke dataset variëren ze hoeveel een patroon moet voorkomen om te tellen en vergelijken ze hun algoritme met LP-growth, OFIM en SSFIM. Over alle drie heen voltooit CLTD-LP consequent zijn werk sneller en gebruikt minder geheugen, vooral wanneer de vereiste frequentiedrempel laag is en veel itemsets moeten worden onderzocht. De auteurs onderbouwen deze observaties met herhaalde runs, zorgvuldige keuze van clusteringinstellingen en statistische tests die aantonen dat de verbeteringen niet door toeval komen.
Wat dit betekent voor data-analyse in de praktijk
Kort gezegd biedt CLTD-LP een efficiëntere manier om betekenisvolle combinaties te vinden in grote verzamelingen records. Door eerst vergelijkbare transacties te groeperen, onwaarschijnlijke items te verwijderen en vervolgens een gestroomlijnde boom top-down te doorlopen, vermijdt de methode veel van de verspilling die in oudere algoritmen voorkomt. Voor bedrijven en onderzoekers die te maken hebben met groeiende hoeveelheden log- en transactiegegevens, betekent dit snellere analyses en kleinere geheugenvriendelijke oplossingen zonder verlies van nauwkeurigheid. De aanpak vereist nog steeds zorgvuldige afstemming van clusteringinstellingen, maar wijst de weg naar schaalbare tools die gelijke tred kunnen houden met de steeds uitdijende digitale sporen van het moderne leven.
Bronvermelding: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Trefwoorden: frequent itemset mining, data mining-algoritmen, winkelwagenanalyse, patroonontdekking, clusteringmethoden