Clear Sky Science · ru
CLTD-LP: оптимизированный сверху вниз подход кластеризации с линейными префиксными деревьями для масштабируемого обнаружения частых шаблонов в больших наборах данных
Нахождение шаблонов, скрытых в повседневных данных
Каждый раз, когда мы совершаем покупку онлайн, играем в игру или пользуемся цифровым сервисом, мы оставляем за собой след из кликов и выборов. В этих следах спрятаны повторяющиеся шаблоны, которые могут показать, какие товары часто покупают вместе, какие события системы предшествуют сбою или как люди ведут себя на сайте. В статье представлен новый алгоритм, названный CLTD-LP, предназначенный для быстрого обнаружения этих повторяющихся сочетаний с меньшими затратами памяти, даже в очень больших и сложных наборах данных.
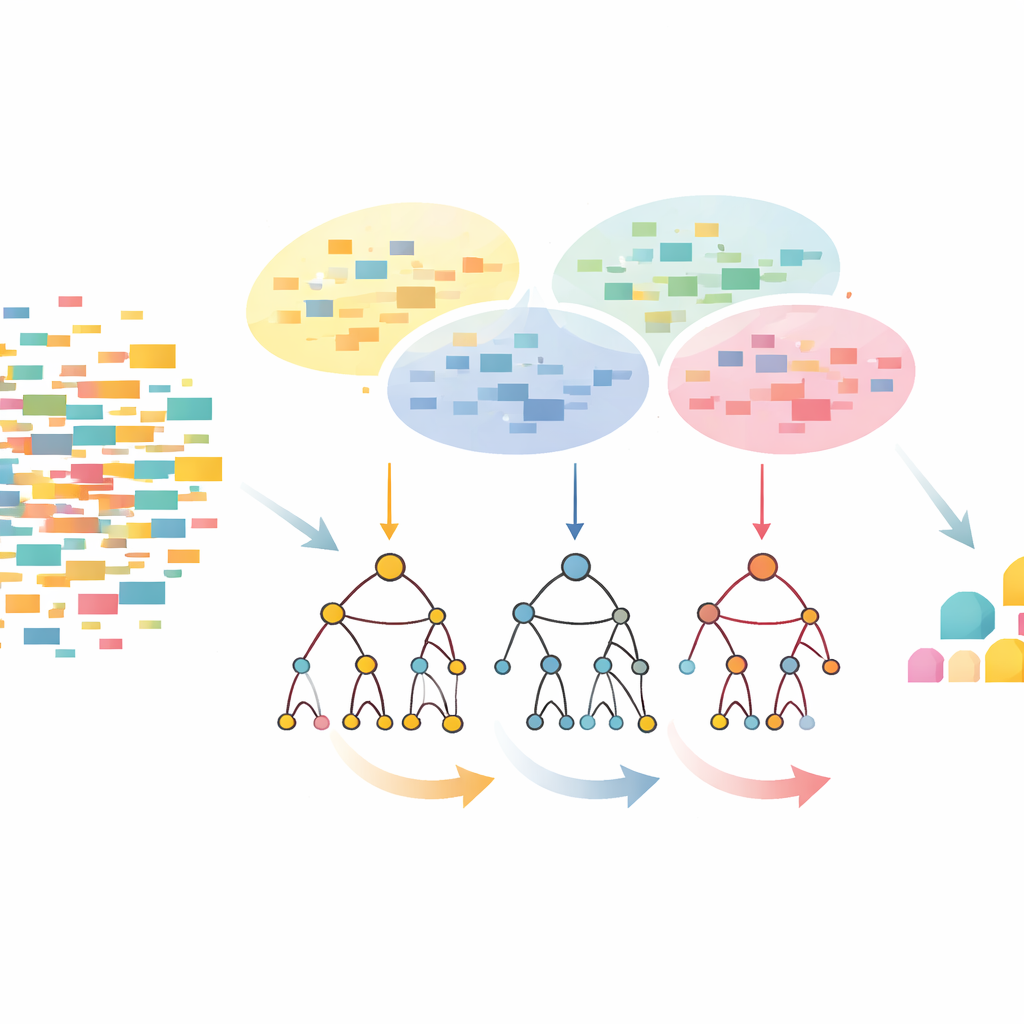
Почему повторяющиеся сочетания важны
Современные организации собирают огромные журналы событий: покупки в супермаркетах, сессии на сайтах, сетевые соединения, медицинские записи и многое другое. Базовая задача анализа данных — выявить «частые наборы» — группы элементов, которые часто появляются вместе во многих записях, например джем, соус и масло в корзине покупок или набор кликов, часто встречающийся в ходе онлайн‑покупки. Эти группы служат сырьем для систем рекомендаций, обнаружения мошенничества, анализа дорожных происшествий и биологических открытий. Однако по мере роста объёмов данных традиционные методы поиска таких шаблонов становятся крайне медленными и требуют большого объёма памяти.
Ограничения ранних методов извлечения
Ранние поколения алгоритмов, такие как Apriori и FP-growth, просматривают наборы данных и строят структуры для учёта со‑встречаемости элементов. Apriori работает снизу вверх, генерируя и проверяя множество кандидатных комбинаций, число которых может взрываться. FP-growth улучшает ситуацию, строя специальное дерево, сжимающее повторяющиеся части транзакций, но при этом он всё ещё полагается на многократное построение так называемых условных деревьев и баз шаблонов для каждого элемента. Более современные варианты, включая LP-growth, OFIM и SSFIM, пытаются оптимизировать эти шаги, но по‑прежнему испытывают трудности при работе с большими и разреженными наборами данных, где многие элементы редки, а транзакции длинны и разнообразны.
Сначала кластеризация, затем более умное дерево
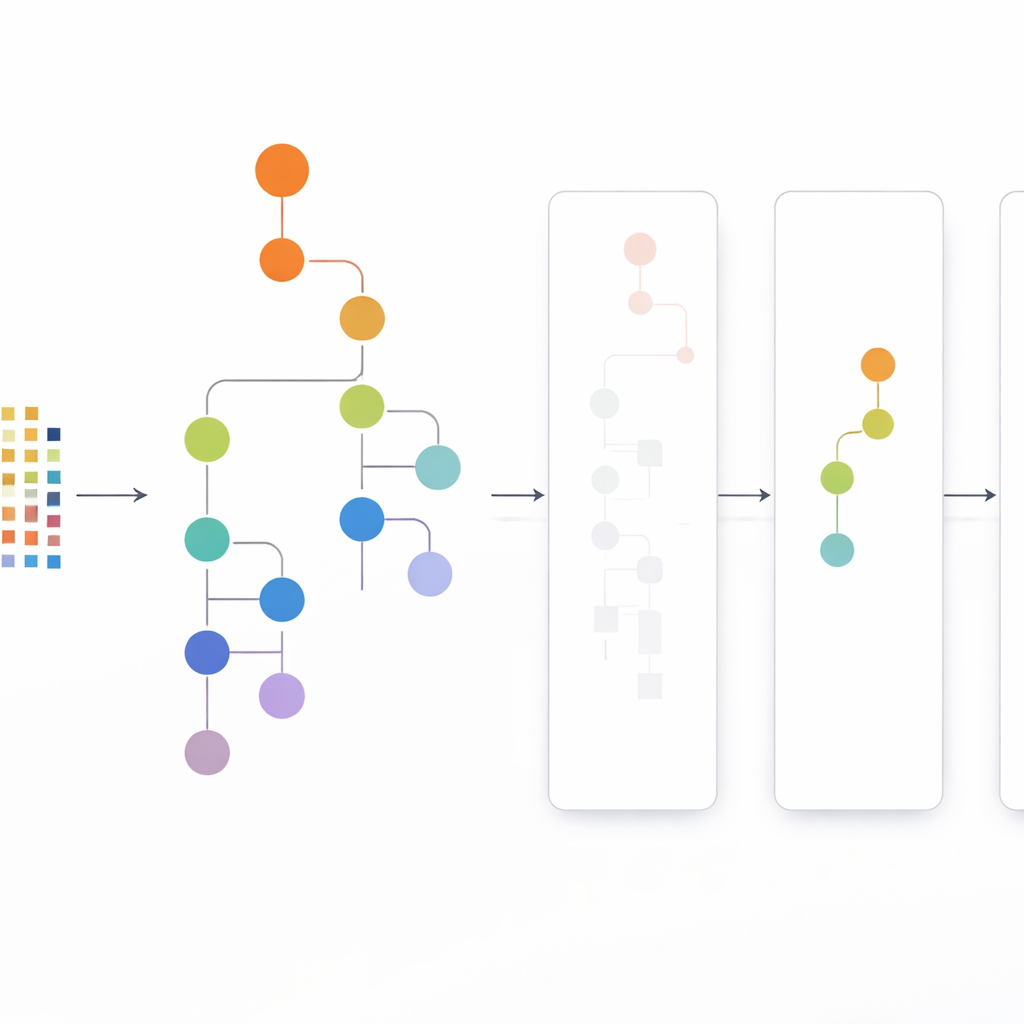
Подход CLTD-LP начинается с преобразования набора данных до построения какого‑либо дерева. Каждая транзакция, например корзина покупок или сессия пользователя, рассматривается как простая бинарная схема наличия элементов, и похожие транзакции группируются с помощью кластеризации. Авторы используют распространённую меру схожести (коэффициент Жаккара) и настраивают число кластеров так, чтобы записи внутри кластера были похожи, а кластеры различались между собой. Внутри каждого кластера редкие элементы отсеиваются, а пустые или почти пустые транзакции удаляются. В результате остаётся меньший, чище набор данных, сохраняющий ключевое поведение. Эти подготовленные данные по кластерам затем поступают в линейное префиксное дерево — компактную, массивоподобную структуру, которая хранит пути элементов в согласованном порядке и избегает значительных накладных расходов на указатели, присущих классическим деревьям.
Просмотр сверху вниз вместо снизу вверх
После построения линейного префиксного дерева CLTD-LP извлекает шаблоны, используя стратегию сверху вниз. Вместо того чтобы начинать с нижних уровней дерева и восстанавливать новые условные деревья для каждого элемента, метод проходит от наиболее частых элементов вниз, используя «таблицы подзаголовков» в качестве временных сводных данных. Эти таблицы отслеживают, как часто элементы встречаются вместе вдоль путей, включающих данный элемент, без воссоздания дополнительных деревьев. Обновляя счётчики непосредственно в существующей структуре и избегая повторной перестройки поддеревьев, CLTD-LP существенно сокращает объём работы. На примере продуктовой корзины алгоритм быстро выявляет наборы вроде {кешью, соус, джем} или {соус, джем, масло, сливки}, проходя по связям в дереве и суммируя счётчики вдоль общих путей.
Доказательства прироста скорости и экономии памяти
Для оценки метода авторы применяют CLTD-LP к трём эталонным наборам данных: базе партий в шахматах, публичному демографическому набору (Pumsb) и реальному набору онлайн‑покупок, собранному ими. Для каждого набора они варьируют порог «частоты», при котором шаблон считается значимым, и сравнивают свой алгоритм с LP-growth, OFIM и SSFIM. Во всех трёх случаях CLTD-LP последовательно завершает вычисления быстрее и использует меньше памяти, особенно когда порог частоты невысок и требуется исследовать множество наборов. Авторы подкрепляют эти наблюдения повторными прогонками, тщательным подбором параметров кластеризации и статистическими тестами, показывающими, что улучшения не случайны.
Что это значит для реального анализа данных
Проще говоря, CLTD-LP предлагает более эффективный способ находить значимые сочетания в больших коллекциях записей. Сначала группируя похожие транзакции, отбрасывая маловероятные элементы, а затем исследуя упрощённое дерево сверху вниз, метод избегает большого числа лишних операций, характерных для старых алгоритмов. Для компаний и исследователей, работающих с растущими объёмами журналов и транзакционных данных, это означает более быстрый анализ и меньшие требования к памяти без потери точности. Подход по‑прежнему требует тщательной настройки параметров кластеризации, но указывает путь к масштабируемым инструментам, которые могут поспевать за постоянно растущими цифровыми следами современной жизни.
Цитирование: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
Ключевые слова: поиск частых наборов, алгоритмы интеллектуального анализа данных, анализ корзины покупок, обнаружение шаблонов, методы кластеризации