Clear Sky Science · ja
CLTD-LP: 大規模データセットでのスケーラブルな頻出パターン発見のための線形プレフィックス木を用いた最適化トップダウンクラスタリング手法
日常データに隠れたパターンを見つける
オンラインで買い物をしたり、ゲームをしたり、デジタルサービスを利用するたびに、クリックや選択の軌跡を残します。これらの軌跡の中には、どの製品が一緒に購入されやすいか、どのシステムイベントが故障に先行しやすいか、あるいは人々がウェブサイト上でどのように振る舞うかを示す反復するパターンが埋もれています。本稿はCLTD-LPと呼ばれる新しいアルゴリズムを紹介します。これは非常に大きく複雑なデータセットでも、繰り返し現れる組み合わせを高速かつ省メモリで検出するよう設計されています。
繰り返し現れる組み合わせが重要な理由
現代の組織は膨大なイベントログを収集します:食料品の購入履歴、ウェブサイトのセッション、ネットワーク接続、医療記録など。データ解析における基本的な課題の一つは「頻出アイテムセット」を発見することです。たとえば食料品のかごにジャム、ソース、バターが一緒に入ることが多い、あるいはオンラインショッピング中に共通して行われる一連のクリック、などが該当します。これらのグループはレコメンデーション、詐欺検出、交通事故分析、生物学的発見の原料となります。しかしデータが増大すると、こうしたパターンを見つける従来の手法は極めて遅くなり、多大なメモリを要求するようになります。
従来のマイニング手法の限界
AprioriやFP-growthのような従来のアルゴリズムは、どのアイテムが共起するかを記録する構造を作るためにデータセットを走査します。Aprioriはボトムアップで多数の候補組合せを生成して検証するため、候補数が爆発的に増えることがあります。FP-growthはトランザクションの繰り返し部分を圧縮する特別な木を構築する点で改善をもたらしましたが、依然として各アイテムごとに条件付き木やパターンベースを繰り返し構築する必要があります。LP-growth、OFIM、SSFIMなどの最近の派生手法はこれらの手順を合理化しようとしますが、データが大規模かつスパースで、多くのアイテムが稀でトランザクションが長く多様な場合には依然として苦戦します。
先にクラスタリングして、より賢い木を作る
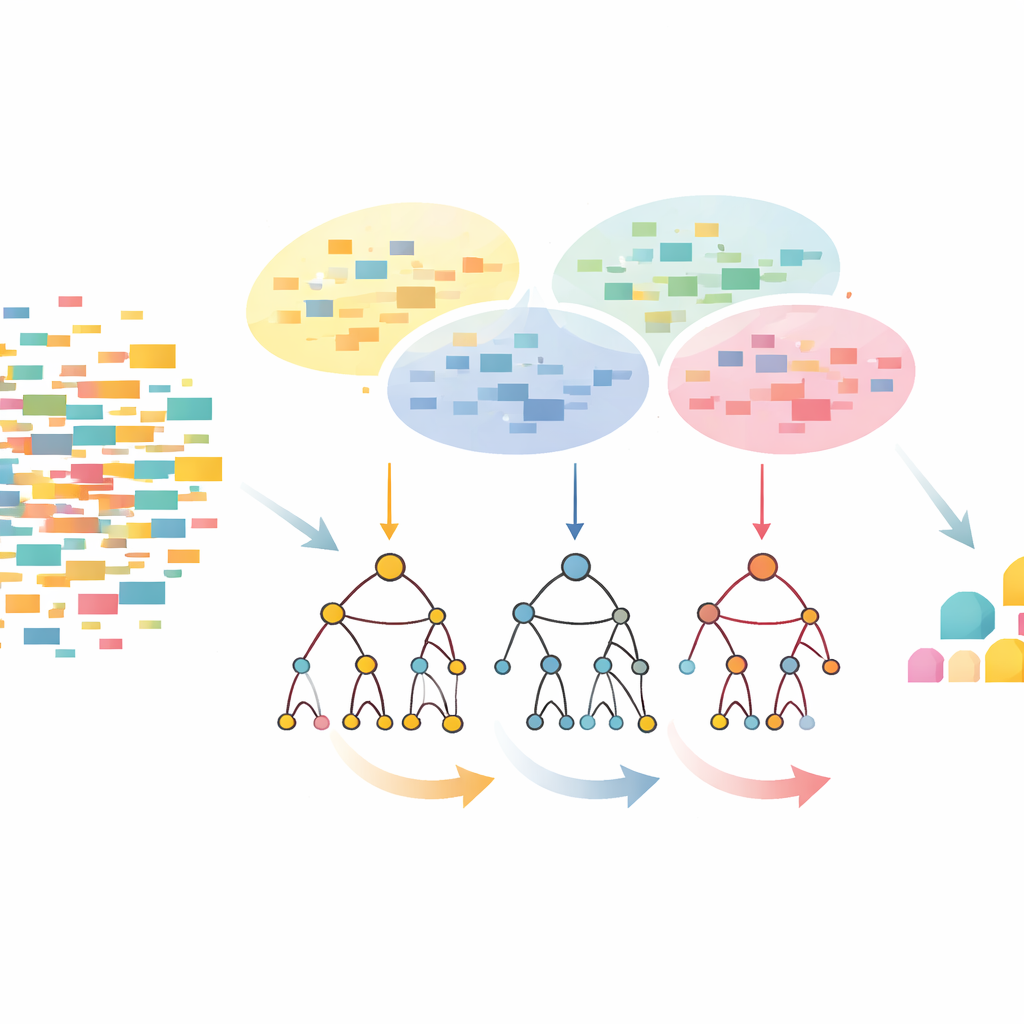
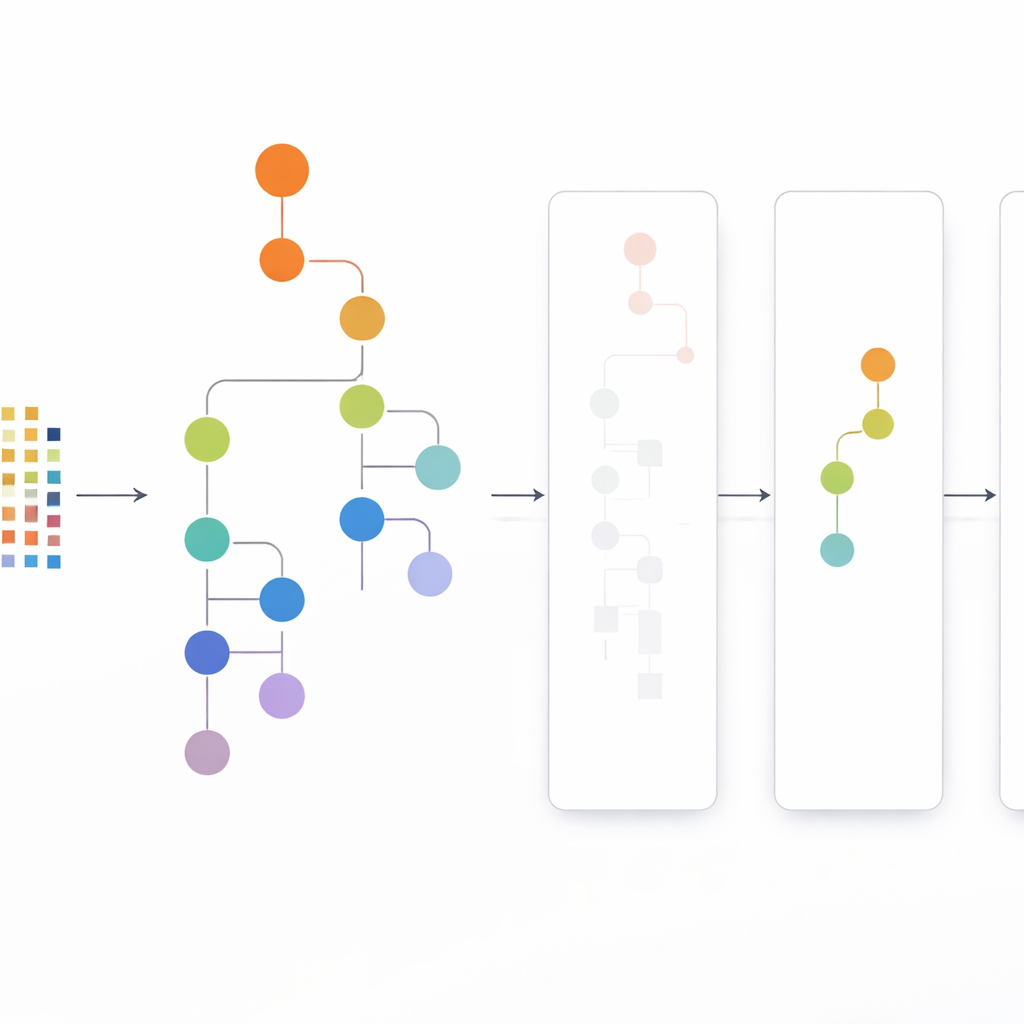
CLTD-LPのアプローチは、木を構築する前にデータセットを再形成することから始まります。各トランザクション(買い物かごやユーザーセッションなど)をアイテムのオン・オフパターンとして扱い、類似したトランザクションをクラスタリングでまとめます。著者らは一般的な類似度指標であるジャカード係数を用い、クラスタ内のレコードが類似しつつ異なるクラスタは区別されるようにクラスタ数を調整します。各クラスタ内で出現頻度の低いアイテムは切り捨てられ、空またはほとんど空のトランザクションは除外されます。こうして残るのは核となる振る舞いを保持した、小さくよりクリーンなデータです。このクラスタ別に剪定されたデータを次に線形プレフィックス木に入力します。線形プレフィックス木はアイテムのパスを一貫した順序で格納するコンパクトな配列状構造で、古典的な木構造に伴うポインタのオーバーヘッドを大幅に回避します。
ボトムアップではなくトップダウンで見る
線形プレフィックス木を構築した後、CLTD-LPはトップダウン戦略でパターンをマイニングします。各アイテムごとにボトムから条件付き木を再構築するのではなく、最も頻出するアイテムから下へ向かって探索を行い、「サブヘッダーテーブル」を一時的な要約として利用します。これらのテーブルは、あるアイテムを含むパスに沿ってアイテムがどれだけ共起するかを追跡しますが、追加の木を再構築する必要はありません。既存構造上で直接カウントを更新し、サブツリーの再構築を避けることで、CLTD-LPは作業量を劇的に削減します。食料品の例では、アルゴリズムは木のリンクをたどり共有パスに沿ってカウントを集約することで、{カシューナッツ, ソース, ジャム} や {ソース, ジャム, バター, クリーム} のような集合を素早く浮かび上がらせます。
速度とメモリ面での利得を実証
新手法を検証するため、著者らはCLTD-LPを三つのベンチマークデータセットに適用しました:チェスのゲームデータベース、公開人口統計データセット(Pumsb)、および彼らが構築した実際のオンラインショッピングデータセットです。各データセットについて、パターンと見なすための「頻度」閾値を変化させ、LP-growth、OFIM、SSFIMと比較しました。三つのデータセットいずれにおいても、特に要求頻度閾値が低く多くのアイテムセットを探索する必要がある場合に、CLTD-LPは一貫して処理時間が短くメモリ使用量も少ない結果を示しました。著者らは反復実行、クラスタリング設定の慎重な選択、そして改善が偶然によるものではないことを示す統計検定によりこれらの観察を裏付けています。
実世界のデータマイニングにとっての意義
要するに、CLTD-LPは大量の記録群の中から意味のある組合せをより効率的に見つける手段を提供します。まず類似トランザクションをグループ化して可能性の低いアイテムを剪定し、続いてトップダウンで簡略化された木を探索することで、従来アルゴリズムに見られた無駄の多くを回避します。ログやトランザクションデータの増大に直面する企業や研究者にとって、これは精度を損なうことなく分析を高速化し、メモリ負荷を小さくすることを意味します。アプローチはクラスタリング設定の慎重な調整を依然として必要としますが、現代の生活が生み出す拡張し続けるデジタル痕跡に追随できるスケーラブルなツールへの道を示しています。
引用: Sinthuja, M., Diviya, M. & Saranya, P. CLTD-LP: an optimized top-down clustering approach with linear prefix trees for scalable frequent pattern discovery in large datasets. Sci Rep 16, 9918 (2026). https://doi.org/10.1038/s41598-026-37338-9
キーワード: 頻出アイテムセットマイニング, データマイニングアルゴリズム, 買い物かご分析, パターン発見, クラスタリング手法