Clear Sky Science · zh
基于跨模态信息瓶颈和最小冗余变换的红外-可见融合多模态目标检测算法研究
在黑暗中看清楚
现代汽车、路面摄像头和安防机器人越来越需要在雨、雾与深夜中识别人员和物体。可见光相机——类似于我们的眼睛——在场景昏暗或强光眩光时性能受限,而红外相机能捕捉热量信息但常常缺乏细节。本文提出了一种新的可见光与红外图像“融合”方式,使机器在困难环境下更可靠地检测行人,减少误报与漏检。
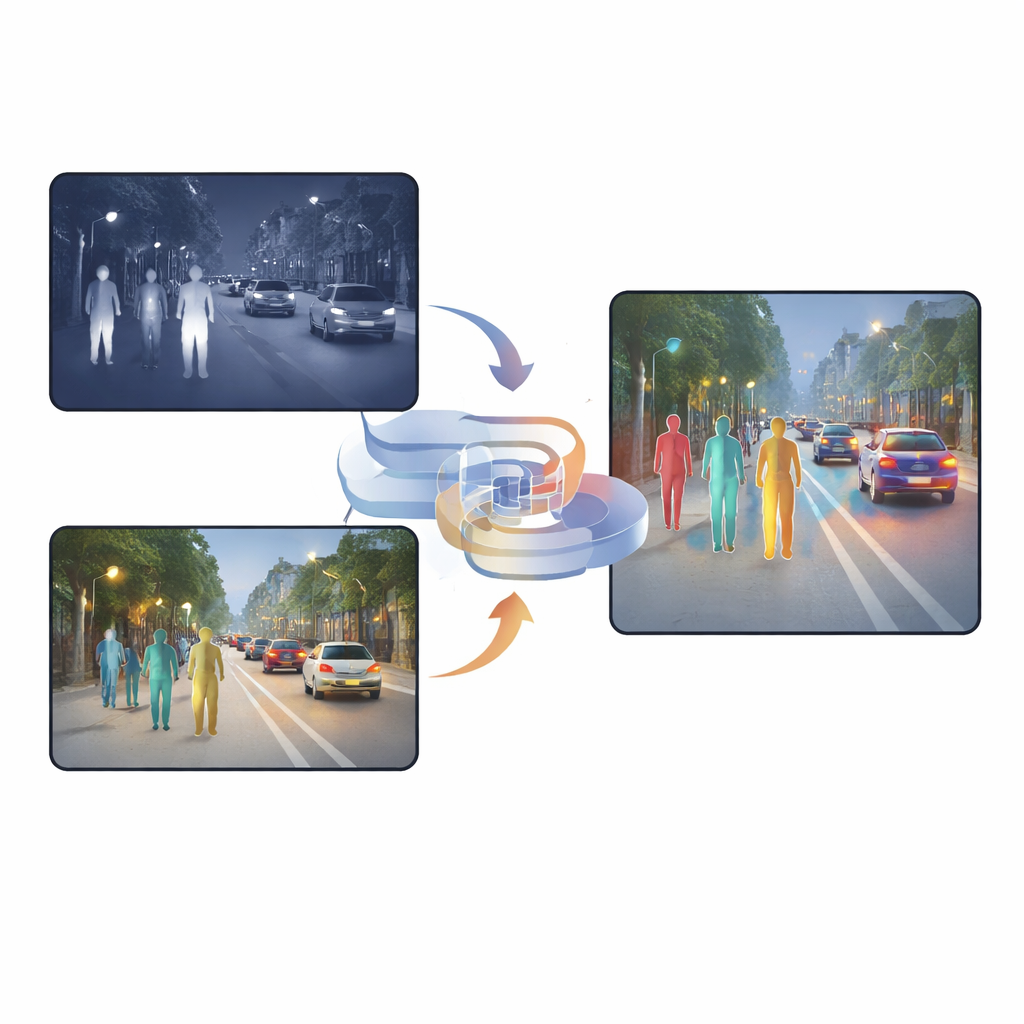
为何双重视觉优于单一
可见光相机在白天能捕捉丰富的纹理、颜色与细微结构,但在夜间或强光条件下性能会急剧下降。相比之下,红外相机能感知热源,使人在黑暗、浓雾或逆光中也能突出显示,然而红外图像通常模糊且缺乏清晰边缘。许多现有系统只是简单地将两类图像堆叠或使用像素级注意力机制决定依赖哪一个相机。这些方法虽然有帮助,但仍携带大量重复或冲突信息,融合结果可能令检测网络困惑,尤其在光线突变或目标部分被遮挡时更为明显。
去除噪声,保留要点
作者提出了一种新的检测框架,专注于两种相机共同拥有的信息并剔除无关内容。其核心是一个跨模态信息瓶颈模块,该模块将联合的可见—红外数据刻意压缩通过一条狭窄的“通道”,然后重建两种视图一致的成分。通过这个过程,网络学会只保留有助于识别目标的模式,同时丢弃相机特有的畸变与噪声。它还分别抽取出可见图像独有的信息和红外图像独有的信息,再以受控方式重组,使每个相机的优势被保留而不会淹没共享视图。
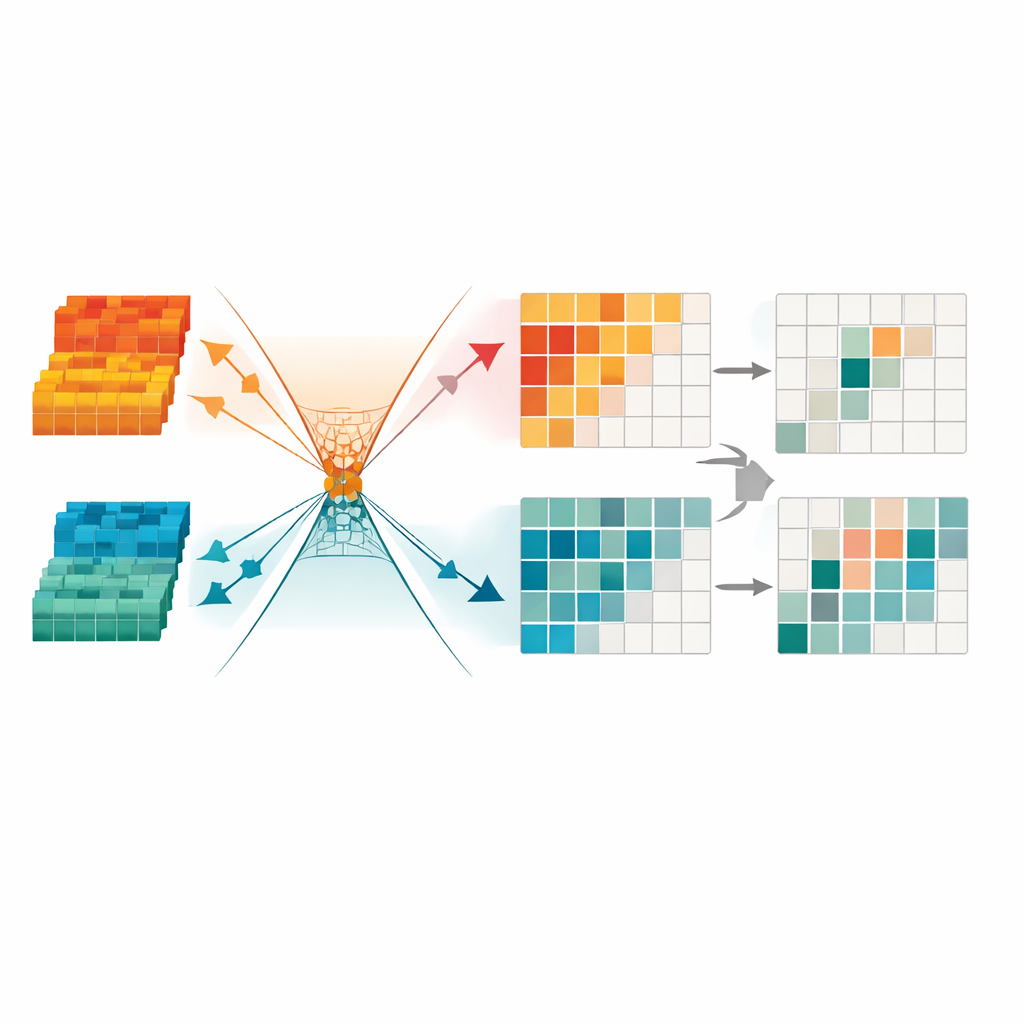
修剪冗余信号以聚焦关键
为进一步净化信息,框架引入了最小冗余变换模块。该组件将融合后的数据视为若干通道与区域的集合,自动掩蔽那些表现不稳定、细节欠缺或受光照伪影主导的部分。它还使用数学约束将有用结构与剩余冗余在内部空间中强制分离到不同“方向”,从而使网络更易忽略对检测无益的模式。最终结果是紧凑、稀疏的表征,突显清晰的目标边界与一致的形状,这对在夜间或拥挤城市场景中识别行人尤为重要。
方法验证
研究者在两个广泛使用的成对可见-红外图像数据集KAIST与LLVIP上评估了其方法,这些数据集包含正常光照和弱光条件下的拥挤街景。他们的方法基于现代的Transformer检测器并采用两阶段训练:首先分别稳定各相机分支;然后微调融合以使两者协同工作。在两个数据集上,该框架在严格定位度量(要求边界框非常精确)上优于领先的仅可见、仅红外和其他融合方法。当图像被人为加入噪声、强烈亮度变化或合成遮挡(遮挡行人部分)时,模型仍表现出更高的可靠性,表明其对真实世界扰动具有鲁棒性。
对更安全机器的意义
简而言之,这项工作教会检测系统同时“听”两台相机,但不让它们相互覆盖对方。通过压缩并重组可见与红外图像的信息,所提方法保留共享的、有意义的线索并切除大量冗余与噪声,从而在昏暗街道或高度杂乱的背景中更清晰地识别人员。作者指出,相同原理可扩展到视频、多目标跟踪,甚至未来将图像与语言混合的系统,帮助机器在各种光照条件下更可靠地“看见”和理解世界。
引用: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
关键词: 红外-可见融合, 多模态目标检测, 行人检测, 弱光成像, 传感器融合鲁棒性