Clear Sky Science · pt
Um estudo sobre algoritmo multimodal de detecção de objetos por fusão infravermelho-visível baseado em gargalo de informação intercodal e transformação de redundância mínima
Enxergando Claramente na Escuridão
Carros modernos, câmeras de rua e robôs de segurança cada vez mais precisam identificar pessoas e objetos na chuva, neblina e noite profunda. Câmeras de luz visível — assim como nossos olhos — têm dificuldade quando a cena está escura ou cheia de reflexos, enquanto câmeras infravermelhas capturam calor, mas frequentemente perdem detalhes. Este trabalho apresenta uma nova forma de combinar, ou “fundir”, imagens visíveis e infravermelhas para que máquinas possam detectar pedestres com mais confiabilidade em condições difíceis, com menos alarmes falsos e alvos perdidos.
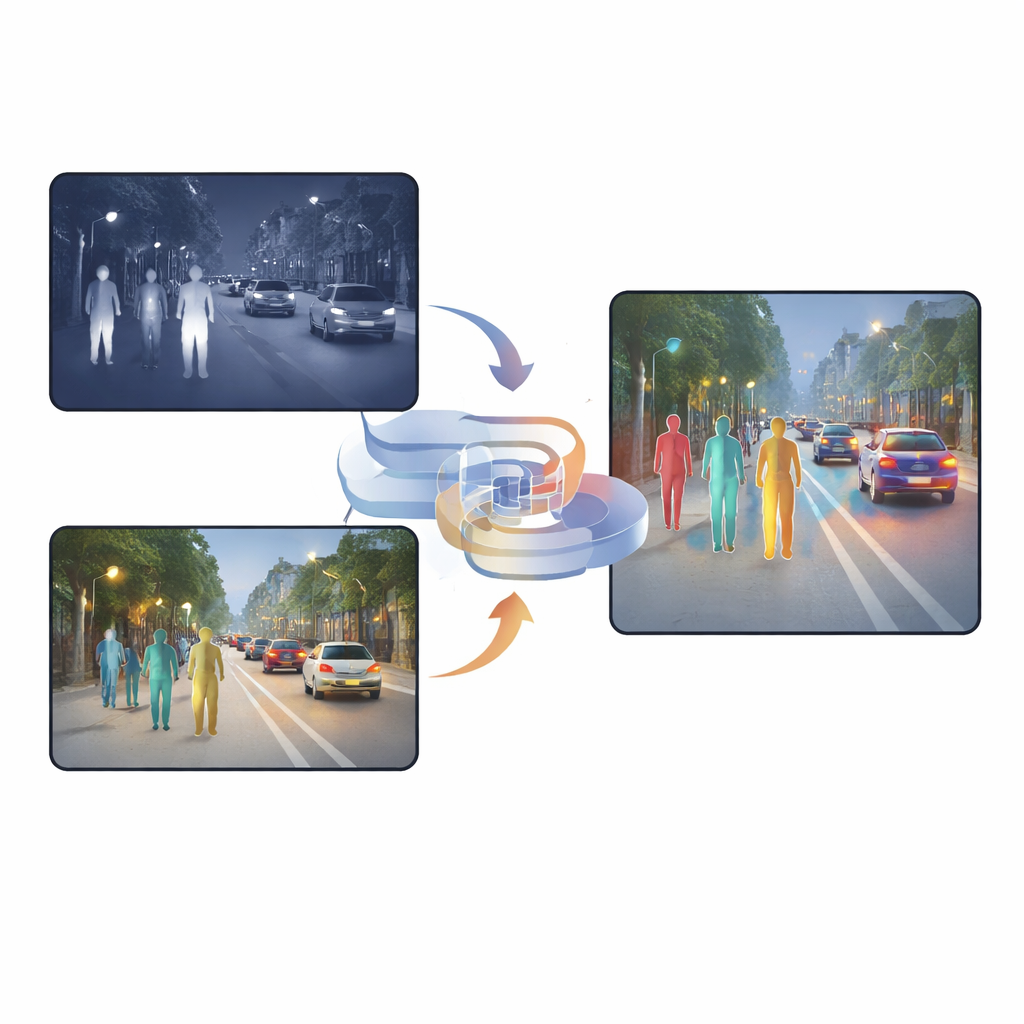
Por que Dois Tipos de Visão São Melhores que Um
Câmeras visíveis capturam texturas ricas, cores e detalhes finos durante o dia, mas seu desempenho cai drasticamente à noite ou sob iluminação severa. Câmeras infravermelhas, por outro lado, enxergam calor, de modo que pessoas se destacam mesmo no escuro, na névoa ou contra contraluz. No entanto, imagens infravermelhas costumam ser borradas e sem bordas nítidas. Muitos sistemas existentes simplesmente empilham esses dois tipos de imagem ou usam mecanismos de atenção que decidem, pixel a pixel, em qual câmera confiar mais. Embora esses métodos ajudem, eles ainda carregam muita informação duplicada ou conflitante, e o resultado da fusão pode confundir a rede de detecção, especialmente quando a luz muda subitamente ou objetos estão parcialmente ocultos.
Filtrando o Ruído, Mantendo o Essencial
Os autores propõem uma nova estrutura de detecção que se concentra no que as duas câmeras têm em comum e descarta o que não é necessário. No centro está um Gargalo de Informação Cross-modal, um módulo que deliberadamente espreme os dados conjuntos visível–infravermelho através de um “canal” estreito e então reconstrói o que ambas as visões concordam. Durante esse processo, a rede aprende a manter apenas os padrões que realmente ajudam a reconhecer objetos, ao mesmo tempo em que descarta peculiaridades e ruídos específicos de cada câmera. Ela separa o que é único das imagens visíveis e o que é exclusivo das infravermelhas, depois recombina esses elementos de forma controlada para que os pontos fortes de cada câmera sejam preservados sem dominar a visão compartilhada.
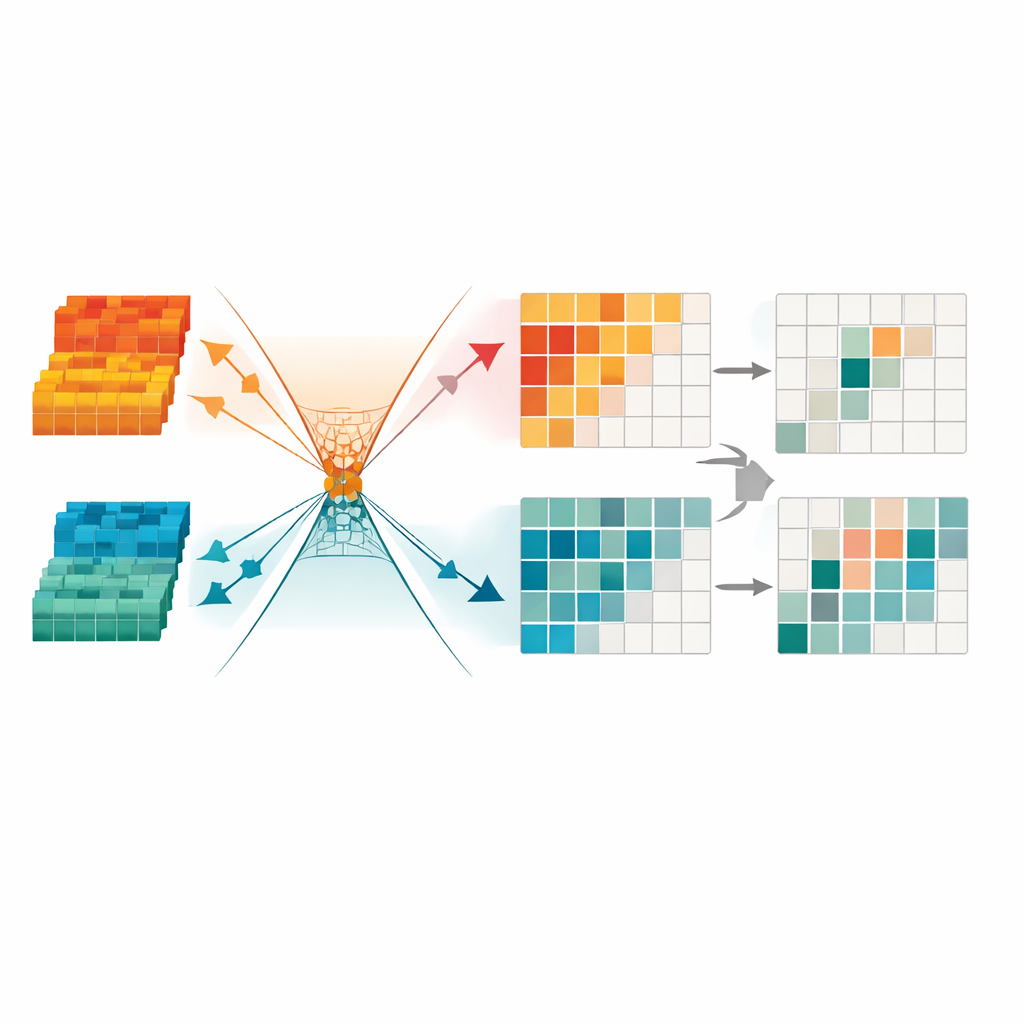
Eliminando Sinais Redundantes para um Foco Mais Nítido
Para limpar ainda mais a informação, a estrutura introduz um módulo de Transformação de Redundância Mínima. Esse componente trata os dados fundidos como uma coleção de canais e regiões, e mascara automaticamente aqueles que parecem instáveis, pobres em detalhes ou dominados por artefatos de iluminação. Também usa restrições matemáticas para forçar estruturas úteis e redundâncias residuais a seguirem “direções” diferentes em seu espaço interno, facilitando para a rede ignorar padrões que não ajudam na detecção. O resultado final é uma representação compacta e esparsa que destaca contornos claros de objetos e formas consistentes, particularmente importante para identificar pedestres à noite ou em cenas urbanas abarrotadas.
Colocando o Método à Prova
Os pesquisadores avaliamos a abordagem em dois conjuntos de dados amplamente usados de imagens visíveis e infravermelhas pareadas, KAIST e LLVIP, que incluem ruas lotadas em condições normais e de baixa luminosidade. O método deles é construído sobre um detector moderno baseado em transformador e treinado em duas etapas: primeiro, cada ramo de câmera é estabilizado separadamente; depois, a fusão é refinada para que os dois funcionem juntos de forma suave. Em ambos os conjuntos de dados, a nova estrutura supera métodos líderes apenas-visíveis, apenas-infravermelho e métodos de fusão, especialmente em medidas rigorosas de localização que exigem caixas delimitadoras muito precisas. Também se mantém mais confiável quando as imagens são artificialmente corrompidas com ruído, mudanças bruscas de brilho ou oclusões sintéticas que bloqueiam partes dos pedestres, mostrando que o modelo é robusto a perturbações do mundo real.
O Que Isso Significa para Máquinas Mais Seguras
Em termos simples, este trabalho ensina sistemas de detecção a ouvir ambas as câmeras sem deixá-las se sobrepor. Ao comprimir e reorganizar a informação de imagens visíveis e infravermelhas, o método proposto mantém as pistas compartilhadas e significativas e corta grande parte da redundância e do ruído. Isso leva a um reconhecimento mais claro de pessoas em cenas difíceis, desde ruas pouco iluminadas até fundos fortemente congestionados. Os autores sugerem que os mesmos princípios poderiam ser estendidos para vídeo, rastreamento de múltiplos objetos e até sistemas futuros que combinem imagens com linguagem, ajudando as máquinas a ver — e entender — o mundo de forma mais confiável em todo tipo de iluminação.
Citação: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Palavras-chave: fusão infravermelho-visível, detecção multimodal de objetos, detecção de pedestres, imagens em baixa luminosidade, robustez da fusão de sensores