Clear Sky Science · sv
En studie om en multimodal objektidentifieringsalgoritm för infrarött‑synligt fusionsbilder baserad på tvärmodal informationsflaskhals och minsta redundanstransformation
Se klart i mörkret
Moderna bilar, gatukameror och säkerhetsrobotar måste i allt högre grad upptäcka människor och föremål i regn, dimma och mörker. Synkameror—lite som våra ögon—har svårt när scenen är mörk eller full av blänk, medan infraröda kameror fångar värme men ofta missar detaljer. Den här artikeln presenterar ett nytt sätt att kombinera, eller "fusera", syn‑ och infraröda bilder så att maskiner kan upptäcka fotgängare mer tillförlitligt under svåra förhållanden, med färre falska larm och missade mål.
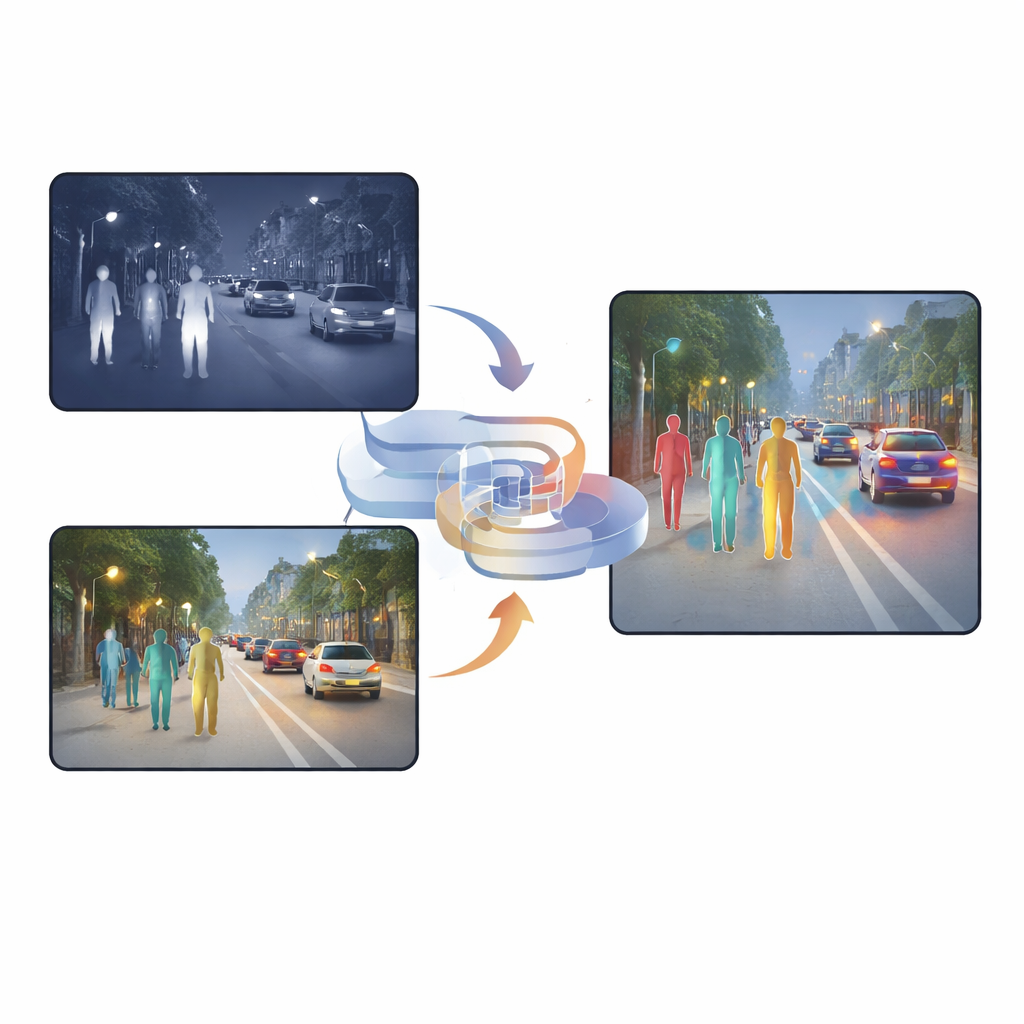
Varför två slags syn är bättre än en
Synkameror fångar rika texturer, färger och fina detaljer under dagen, men deras prestanda faller kraftigt på natten eller under hård belysning. Infraröda kameror ser däremot värme, så människor framträder även i mörker, dimma eller motljus. Infraröda bilder är dock ofta suddiga och saknar skarpa kanter. Många befintliga system staplar helt enkelt ihop de två bildtyperna eller använder uppmärksamhetsmekanismer som avgör, pixel för pixel, vilken kamera som bör tillmätas mest förtroende. Dessa metoder hjälper visserligen, men bär fortfarande mycket duplicerad eller motstridig information, och det sammanslagna resultatet kan bli förvirrande för detektorernätverket, särskilt vid snabba ljusförändringar eller partiellt dolda objekt.
Filtrera bort brus, behålla det väsentliga
Författarna föreslår ett nytt detektionsramverk som fokuserar på vad de två kamerorna har gemensamt och slänger det som inte behövs. I kärnan finns en tvärmodal informationsflaskhals, en modul som medvetet pressar den gemensamma syn‑infraröda datan genom en smal "kanal" och sedan rekonstruerar vad båda vyerna är överens om. Under denna process lär sig nätverket att behålla endast de mönster som verkligen hjälper till att känna igen objekt, samtidigt som kameraspecifika egenheter och brus kasseras. Det isolerar separat vad som är unikt för synbilder och vad som är unikt för infraröda bilder, för att sedan återkombinera dem på ett kontrollerat sätt så att varje kameras styrkor bevaras utan att dominera den delade vyn.
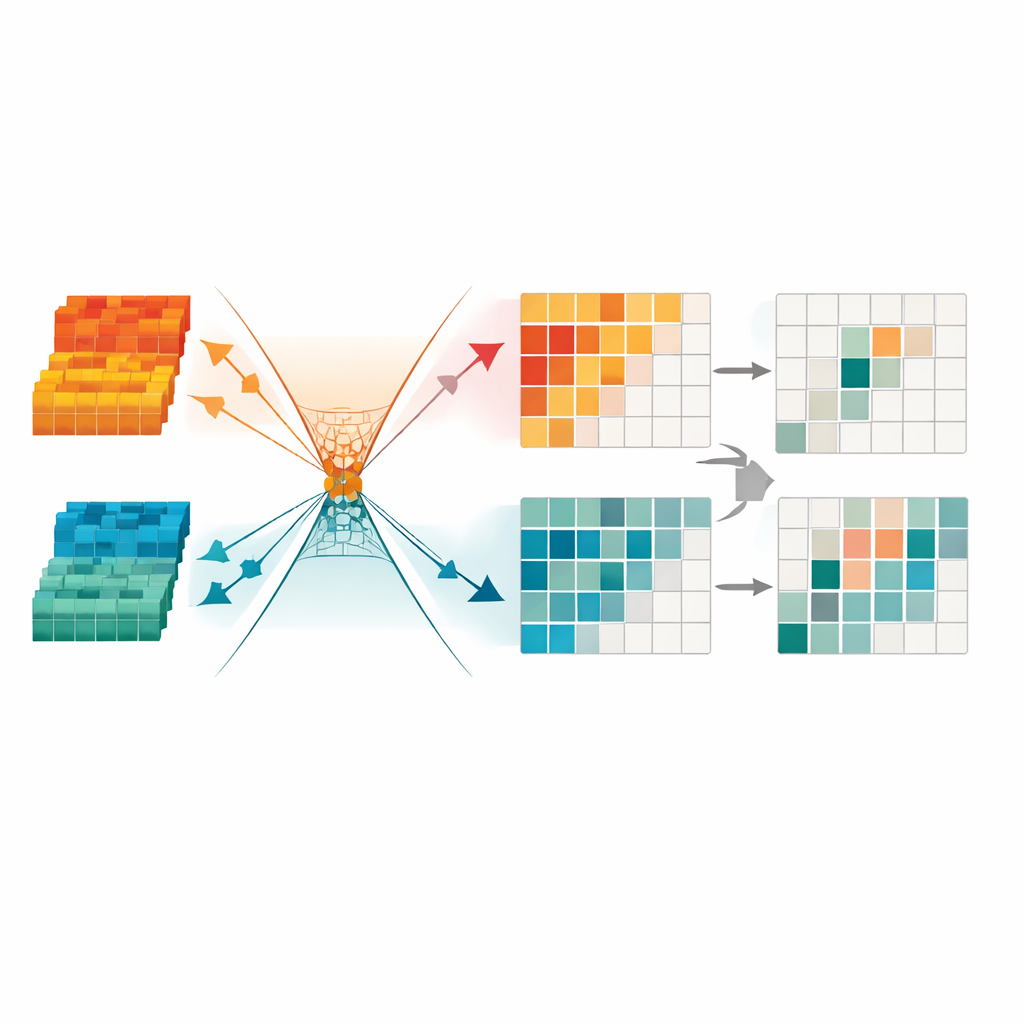
Beskära redundanta signaler för skarpare fokus
För att ytterligare rensa informationen introducerar ramverket en modul för minsta redundanstransformation. Denna komponent behandlar den fusionerade datan som en samling kanaler och regioner och maskerar automatiskt de delar som verkar instabila, detaljfattiga eller dominerade av belysningsartefakter. Den använder också matematiska begränsningar för att tvinga användbar struktur och kvarvarande redundans in i olika "riktningar" i sitt interna rum, vilket gör det lättare för nätverket att ignorera mönster som inte hjälper detektionen. Slutresultatet är en kompakt, gles representation som framhäver tydliga objektgränser och konsekventa former, särskilt viktigt för att upptäcka fotgängare på natten eller i röriga stadslandskap.
Sätta metoden på prov
Forskarna utvärderar sitt tillvägagångssätt på två väletablerade dataset med parade syn‑ och infraröda bilder, KAIST och LLVIP, som innehåller folktäta gator under både normala och svagljusförhållanden. Deras metod bygger på en modern transformer‑baserad detektor och tränas i två steg: först stabiliseras varje kameragren separat; därefter finslipas fusionen så att de två fungerar smidigt tillsammans. Över båda dataset överträffar det nya ramverket ledande metoder som använder enbart syn, enbart infrarött eller tidigare fusionsmetoder, särskilt i strikta lokalisationsmått som kräver mycket precisa avgränsningsboxar. Det förblir också mer tillförlitligt när bilder artificiellt korruptas med brus, kraftiga ljusförändringar eller syntetiska ocklusioner som blockerar delar av fotgängare, vilket visar att modellen är robust mot verkliga störningar.
Vad detta betyder för säkrare system
Enkelt uttryckt lär detta arbete detekteringssystem att lyssna på båda kamerorna utan att låta dem tala över varandra. Genom att komprimera och omorganisera informationen från syn‑ och infraröda bilder bevarar den föreslagna metoden de delade, meningsfulla ledtrådarna och skär bort mycket av redundansen och bruset. Detta leder till tydligare igenkänning av människor i svåra scener, från svagt upplysta gator till starkt röriga bakgrunder. Författarna föreslår att samma principer kan utvidgas till video, flerspårig objektuppföljning och till och med framtida system som blandar bilder med språk, vilket hjälper maskiner att se—och förstå—världen mer tillförlitligt i alla slags ljusförhållanden.
Citering: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Nyckelord: infraröd‑synlig fusion, multimodal objektidentifiering, gångtrafikantdetektion, bildtagning i svagt ljus, sensorfusion och robusthet