Clear Sky Science · ar
دراسة حول خوارزمية كشف الأجسام متعددة الوسائط بالاندماج تحت الحمراء والمرئية بناءً على عنق الزجاجة للمعلومات عبر الوسائط وتحويل الحد الأدنى من التكرار
الرؤية الواضحة في الظلام
تتطلب السيارات الحديثة وكاميرات الشوارع والروبوتات الأمنية بشكل متزايد اكتشاف الأشخاص والأشياء في المطر والضباب والليل الدامس. الكاميرات الضوئية—مثل أعيننا—تتعثر عندما يكون المشهد مظلماً أو مشبعاً بالتوهج، بينما تلتقط كاميرات الأشعة تحت الحمراء الحرارة لكنها غالباً ما تفقد التفاصيل. تقدم هذه الورقة طريقة جديدة لدمج، أو «توحيد»، الصور المرئية وتحت الحمراء بحيث تتمكن الآلات من الكشف عن المشاة بشكل أكثر موثوقية في ظروف صعبة، مع تقليل الإنذارات الكاذبة والأهداف الفائتة.
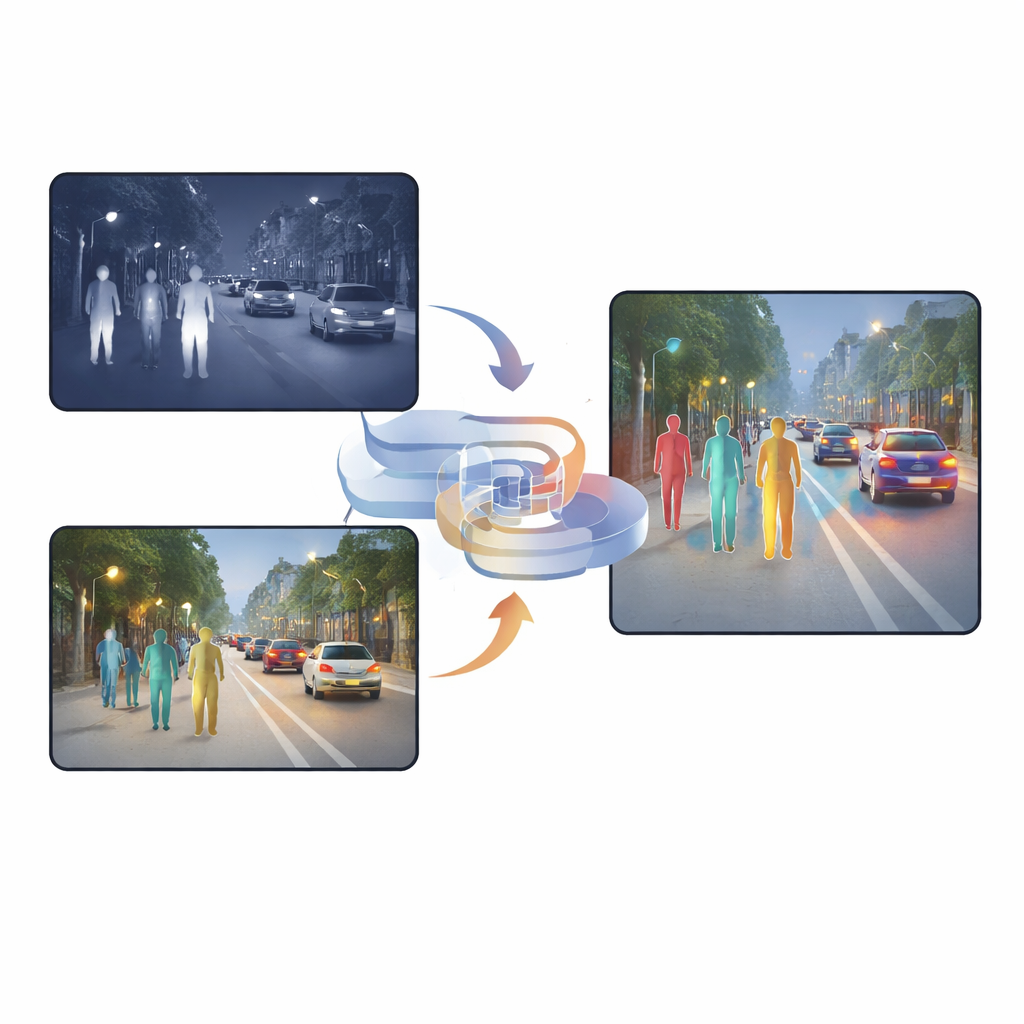
لماذا رؤية نوعين أفضل من واحدة
تلتقط الكاميرات المرئية نسيجاً غنياً وألواناً وتفاصيل دقيقة خلال النهار، لكن أداؤها ينخفض بشدة ليلاً أو تحت إضاءة قاسية. أما كاميرات الأشعة تحت الحمراء، فرغم ذلك فتُظهر الحرارة، لذلك يبرز الأشخاص حتى في الظلام أو الضباب أو الإضاءة الخلفية. ومع ذلك، غالباً ما تكون صور الأشعة تحت الحمراء ضبابية وتفتقر إلى الحواف الواضحة. كثير من الأنظمة الحالية تكتفي بترصيف هذين النوعين من الصور أو تستخدم آليات انتباه تقرر، بكسلاً بكسل، أي كاميرا يثق بها أكثر. ورغم أن هذه الطرق مفيدة، فإنها لا تزال تحمل الكثير من المعلومات المكررة أو المتضاربة، وقد يكون الناتج المندمج محيراً لشبكة الكشف، خاصة عندما تتغير الإضاءة فجأة أو تغطي الأشياء جزئياً.
تصفيه الضوضاء، والاحتفاظ بالضروري
يقترح المؤلفون إطار كشف جديد يركز على ما يتفق عليه الكاميران ويلقي بما لا يلزم. في جوهره يوجد «عنق زجاجة المعلومات عبر الوسائط»، وهو وحدة تضغط عمداً البيانات المشتركة بين المرئي وتحت الحمراء عبر «قناة» ضيقة ثم تعيد بناء ما تتفق عليه النظرتان. خلال هذه العملية تتعلم الشبكة الاحتفاظ بالأنماط التي تساعد فعلاً على التعرف على الأجسام، بينما تتخلص من خصوصيات الكاميرا والضوضاء. تستخرج أيضاً بشكل منفصل ما هو فريد في الصور المرئية وما هو فريد في صور الأشعة تحت الحمراء، ثم تعيد دمجهما بطريقة مضبوطة بحيث تُحافظ نقاط قوة كل كاميرا دون أن تطغى على الرؤية المشتركة.
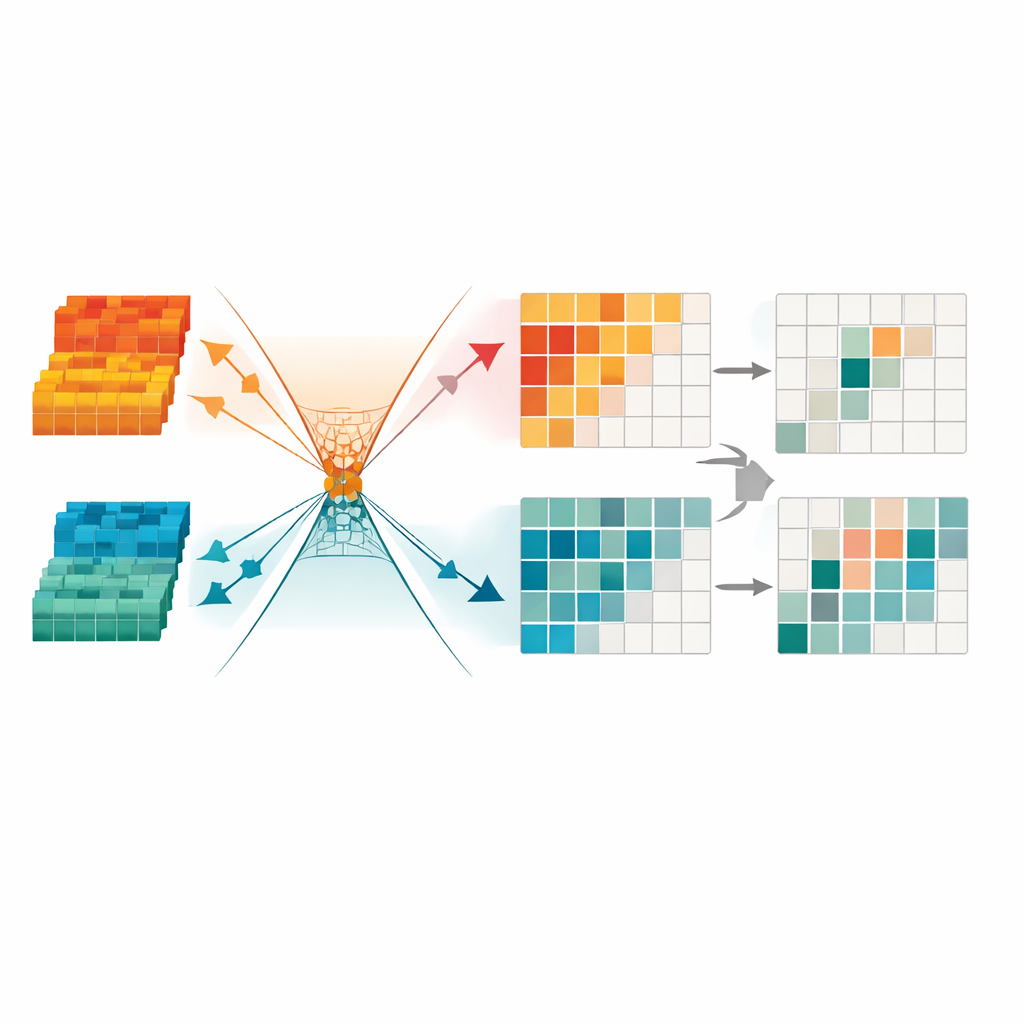
تقليص الإشارات المكررة لتركيز أدق
لتنقية المعلومات بشكل أكبر، يقدم الإطار وحدة تحويل الحد الأدنى من التكرار. تتعامل هذه المكوّنات مع البيانات المندمجة كمجموعة من القنوات والمناطق، وتقوم تلقائياً بإخفاء تلك التي تبدو غير مستقرة أو منخفضة التفاصيل أو سائدة بتشوهات ناتجة عن الإضاءة. كما تستخدم قيوداً رياضية لإجبار البنية المفيدة والبقايا المكررة على الانصراف إلى «اتجاهات» مختلفة في فضائها الداخلي، مما يسهل على الشبكة تجاهل الأنماط غير المفيدة للكشف. والنتيجة النهائية تمثيل مضغوط ونادر يبرز حدود الأجسام والأشكال المتسقة، وهو أمر بالغ الأهمية لرصد المشاة ليلاً أو في المشاهد الحضرية المزدحمة.
اختبار الطريقة
يقوم الباحثون بتقييم نهجهم على مجموعتي بيانات مستخدمتين على نطاق واسع من الصور المرئية والمطابقة لها تحت الحمراء، KAIST وLLVIP، اللتين تتضمنان شوارع مزدحمة في ظروف إضاءة طبيعية ومنخفضة. بُنيت طريقتهم على كاشف معتمد على الترنسفورمر العصري وتم تدريبها على مرحلتين: أولاً تُثبَّت كل فرع كاميرا بشكل منفصل؛ ثم تُضبط عملية الاندماج بدقة حتى يعمل الفرعان معاً بسلاسة. عبر المجموعتين، يتفوق الإطار الجديد على أبرز الطرق المعتمدة على المرئي فقط أو الأشعة تحت الحمراء فقط أو طرق الاندماج، لا سيما في مقاييس التحديد الصارمة التي تتطلب صناديق تحديد دقيقة جداً. كما يظل أكثر موثوقية عند تلف الصور اصطناعياً بضوضاء أو تغييرات سطوع شديدة أو حجب اصطناعي لأجزاء من المشاة، ما يبيّن متانة النموذج أمام الاضطرابات الواقعية.
ما يعنيه هذا لآلات أكثر أماناً
بعبارة بسيطة، تعلم هذا العمل أنظمة الكشف أن تستمع إلى الكاميرتين دون أن تدعهما يتنافسان على الكلام. عبر ضغط وإعادة تنظيم المعلومات من الصور المرئية وتحت الحمراء، تحافظ الطريقة المقترحة على الإشارات المشتركة والمعنوية وتقطع كثيراً من التكرار والضوضاء. يؤدي ذلك إلى تعرف أوضح على الأشخاص في المشاهد الصعبة، من الشوارع الخافتة الإضاءة إلى الخلفيات المزدحمة. ويقترح المؤلفون أن نفس المبادئ يمكن تمديدها إلى الفيديو وتعقب الأجسام المتعدد وحتى الأنظمة المستقبلية التي تمزج الصور مع اللغة، لمساعدة الآلات على رؤية—وفهم—العالم بشكل أكثر موثوقية في كل ظروف الإضاءة.
الاستشهاد: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
الكلمات المفتاحية: اندماج تحت الحمراء والمرئية, كشف الأجسام متعددة الوسائط, كشف المشاة, التصوير في الإضاءة المنخفضة, متانة اندماج المستشعرات