Clear Sky Science · pl
Badanie algorytmu multimodalnego wykrywania obiektów na bazie fuzji podczerwieni i widzialnego obrazu opartego na międzymodalnej butelce informacyjnej i transformacji o minimalnej redundancji
Wyraźne widzenie w ciemności
Współczesne samochody, kamery uliczne i roboty ochronne coraz częściej muszą rozpoznawać ludzi i obiekty w deszczu, mgle i głębokiej nocy. Kamery światła widzialnego — podobnie jak nasze oczy — słabo radzą sobie, gdy scena jest ciemna lub pełna odblasków, podczas gdy kamery na podczerwień rejestrują ciepło, lecz często tracą szczegóły. W artykule zaproponowano nowy sposób łączenia, czyli „fuzji”, obrazów widzialnych i podczerwieni, dzięki któremu maszyny potrafią bardziej niezawodnie wykrywać pieszych w trudnych warunkach, z mniejszą liczbą fałszywych alarmów i pominięć.
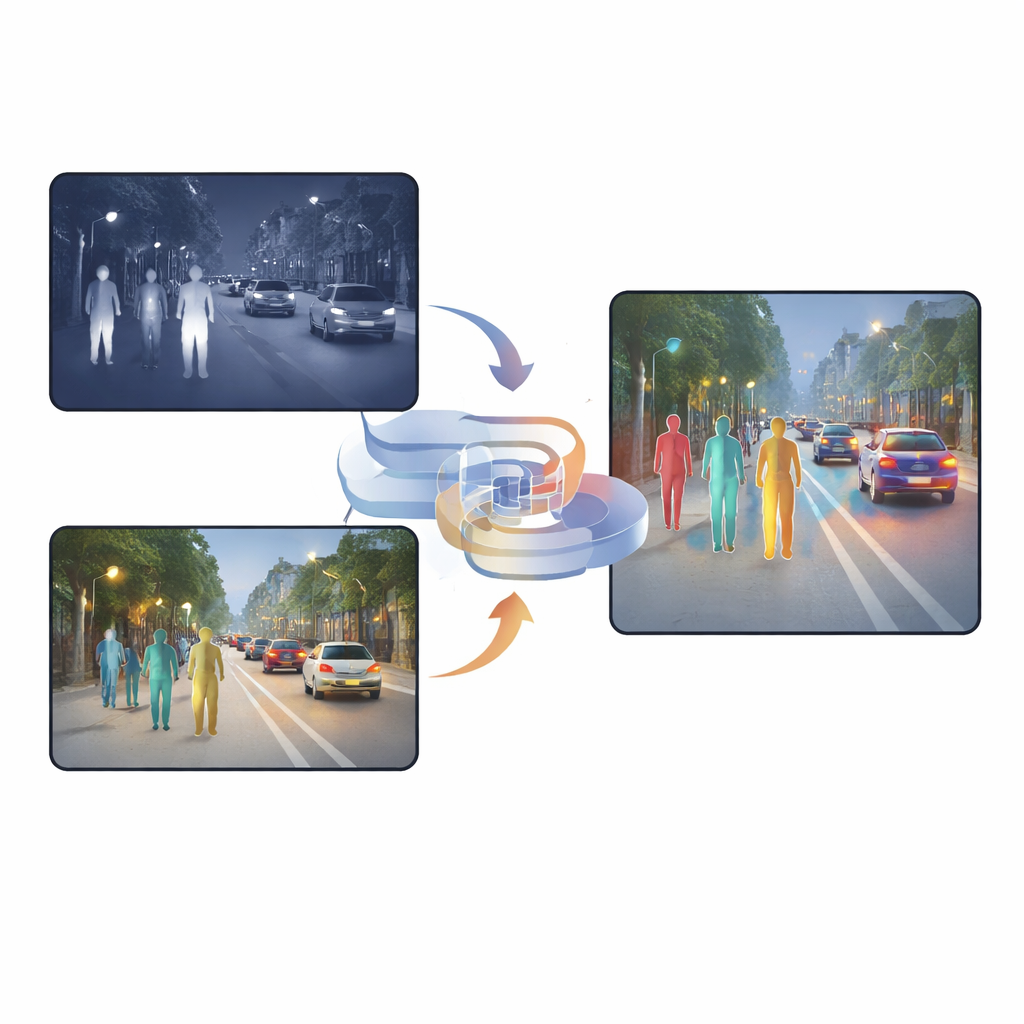
Dlaczego dwa rodzaje widzenia są lepsze niż jedno
Kamerki widzialne rejestrują bogate faktury, kolory i drobne detale w ciągu dnia, ale ich wydajność gwałtownie spada nocą lub przy trudnym oświetleniu. Kamery na podczerwień z kolei widzą ciepło, więc ludzie wyróżniają się nawet w ciemności, mgle lub przy podświetleniu od tyłu. Jednak obrazy w podczerwieni są często rozmyte i pozbawione ostrych krawędzi. Wiele istniejących systemów po prostu nakłada te dwa rodzaje obrazów lub stosuje mechanizmy uwagi, które decydują, piksel po pikselu, któremu aparatowi bardziej zaufać. Chociaż metody te pomagają, wciąż niosą ze sobą dużo zduplikowanej lub sprzecznej informacji, a wynikowa fuzja może mylić sieć detekcyjną, szczególnie gdy światło nagle się zmienia lub obiekty są częściowo zasłonięte.
Odseparowanie szumu, zachowanie istotnego
Autorzy proponują nową architekturę wykrywania, która koncentruje się na tym, co wspólne dla obu kamer, i odrzuca to, co niepotrzebne. Serce rozwiązania stanowi międzymodalny kanał informacyjny (Cross-modal Information Bottleneck) — moduł, który celowo przepuszcza wspólne dane z widzialnego i podczerwieni przez wąskie „łącze”, a następnie rekonstruuje to, na czym obie perspektywy się zgadzają. W trakcie tego procesu sieć uczy się zachowywać tylko te wzorce, które faktycznie pomagają rozpoznawać obiekty, odrzucając przy tym cechy charakterystyczne dla konkretnego sensora i szumy. Osobno wydziela to, co unikatowe dla obrazu widzialnego i dla podczerwieni, a następnie łączy je w kontrolowany sposób, tak aby mocne strony każdej kamery były zachowane, nie dominując jednak wspólnego widoku.
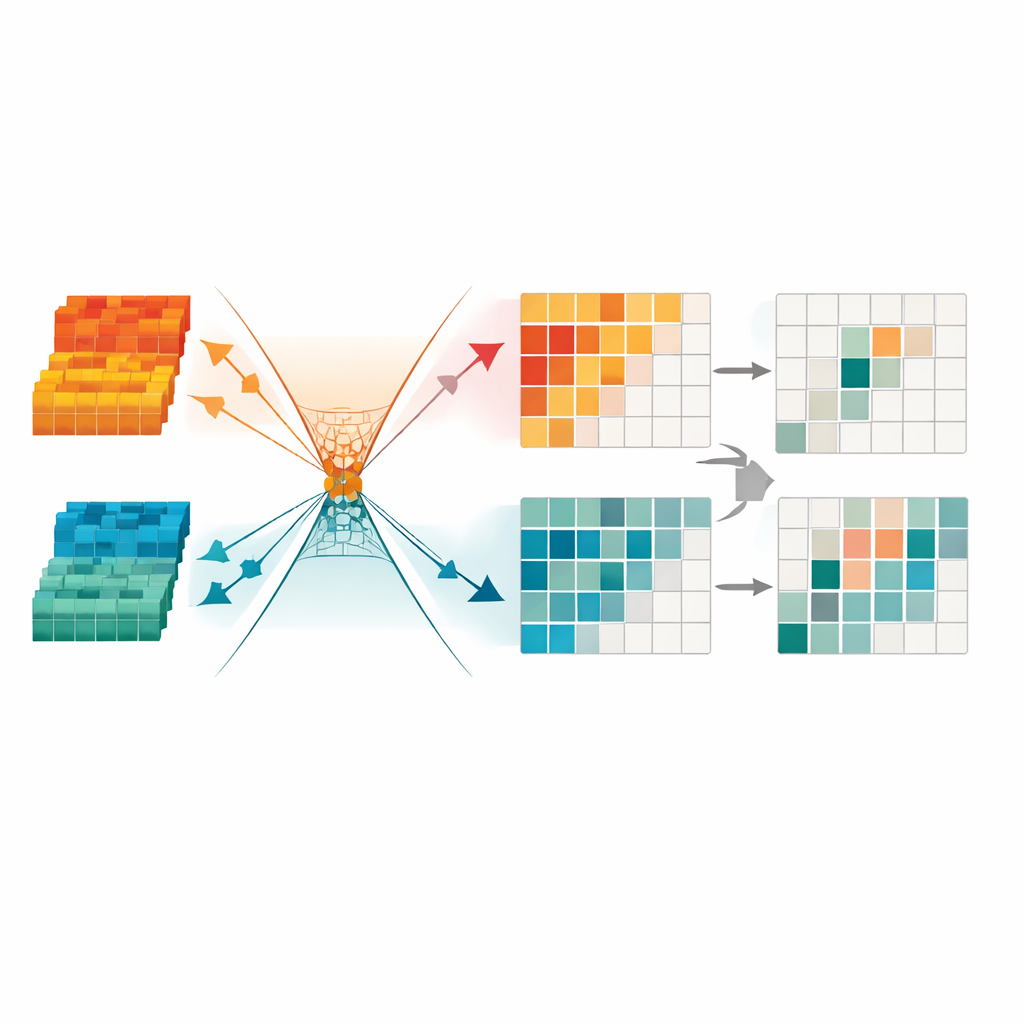
Przycinanie sygnałów redundantnych dla ostrzejszego skupienia
Aby jeszcze bardziej oczyścić informacje, architektura wprowadza moduł transformacji o minimalnej redundancji (Minimum Redundancy Transformation). Komponent traktuje zfuzowane dane jak zbiór kanałów i regionów i automatycznie maskuje te, które wydają się niestabilne, ubogie w szczegóły lub zdominowane przez artefakty oświetleniowe. Stosuje też matematyczne ograniczenia, aby wymusić rozdzielenie użytecznej struktury i pozostałej redundancji w różnych „kierunkach” wewnętrznej przestrzeni, co ułatwia sieci ignorowanie wzorców nieprzydatnych do wykrywania. Efektem jest kompaktowa, rzadka reprezentacja uwydatniająca wyraźne granice obiektów i spójne kształty — szczególnie ważne przy wykrywaniu pieszych nocą lub w zatłoczonych miejskich scenach.
Testy metody
Badacze oceniają swoje podejście na dwóch szeroko stosowanych zbiorach par obrazów widzialnych i podczerwieni, KAIST i LLVIP, które obejmują zatłoczone ulice w warunkach normalnych i przy słabym oświetleniu. Metoda oparta jest na nowoczesnym detektorze typu transformer i trenowana jest w dwóch etapach: najpierw stabilizowane są oddzielnie gałęzie dla każdej kamery; potem fuzja jest dopracowywana tak, by obie współpracowały płynnie. Na obu zbiorach nowe rozwiązanie przewyższa wiodące metody opierające się wyłącznie na widzialnym obrazie, wyłącznie na podczerwieni oraz metody z fuzją, zwłaszcza w rygorystycznych miarach lokalizacji wymagających bardzo precyzyjnych ramek ograniczających. Ponadto metoda pozostaje bardziej niezawodna, gdy obrazy są sztucznie zniekształcone szumem, gwałtownymi zmianami jasności lub syntetycznymi zasłonięciami części pieszych, co pokazuje odporność modelu na zaburzenia typowe dla rzeczywistych warunków.
Co to oznacza dla bezpieczniejszych maszyn
Mówiąc wprost, praca ta uczy systemy detekcji słuchania obu kamer, ale nie pozwalania im na wzajemne zagłuszanie się. Poprzez kompresję i reorganizację informacji z obrazów widzialnych i podczerwieni, proponowana metoda zachowuje wspólne, znaczące wskazówki i odcina dużą część redundancji oraz szumu. Prowadzi to do czytelniejszego rozpoznawania ludzi w trudnych scenach — od słabo oświetlonych ulic po silnie zagracone tła. Autorzy sugerują, że te same zasady można rozszerzyć na wideo, śledzenie wielu obiektów, a nawet przyszłe systemy łączące obrazy z językiem, pomagając maszynom widzieć — i rozumieć — świat bardziej niezawodnie w różnorodnych warunkach oświetleniowych.
Cytowanie: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Słowa kluczowe: fuzja podczerwieni i widzialnego obrazu, multimodalne wykrywanie obiektów, wykrywanie pieszych, obrazowanie przy słabym świetle, odporność fuzji sensorów