Clear Sky Science · it
Uno studio su un algoritmo di rilevamento multimodale per la fusione infrarosso-visibile basato sul collo di bottiglia dell'informazione cross-modale e sulla trasformazione a minima ridondanza
Vedere chiaramente nel buio
Auto moderne, telecamere stradali e robot di sicurezza devono sempre più spesso individuare persone e oggetti sotto pioggia, nebbia e nella notte profonda. Le videocamere in luce visibile—proprio come i nostri occhi—faticano quando la scena è scura o piena di abbagli, mentre le camere a infrarossi catturano il calore ma spesso perdono i dettagli. Questo articolo presenta un nuovo modo di combinare, o “fondere”, immagini visibili e infrarosse in modo che le macchine possano rilevare i pedoni in modo più affidabile in condizioni difficili, con meno falsi allarmi e bersagli mancati.
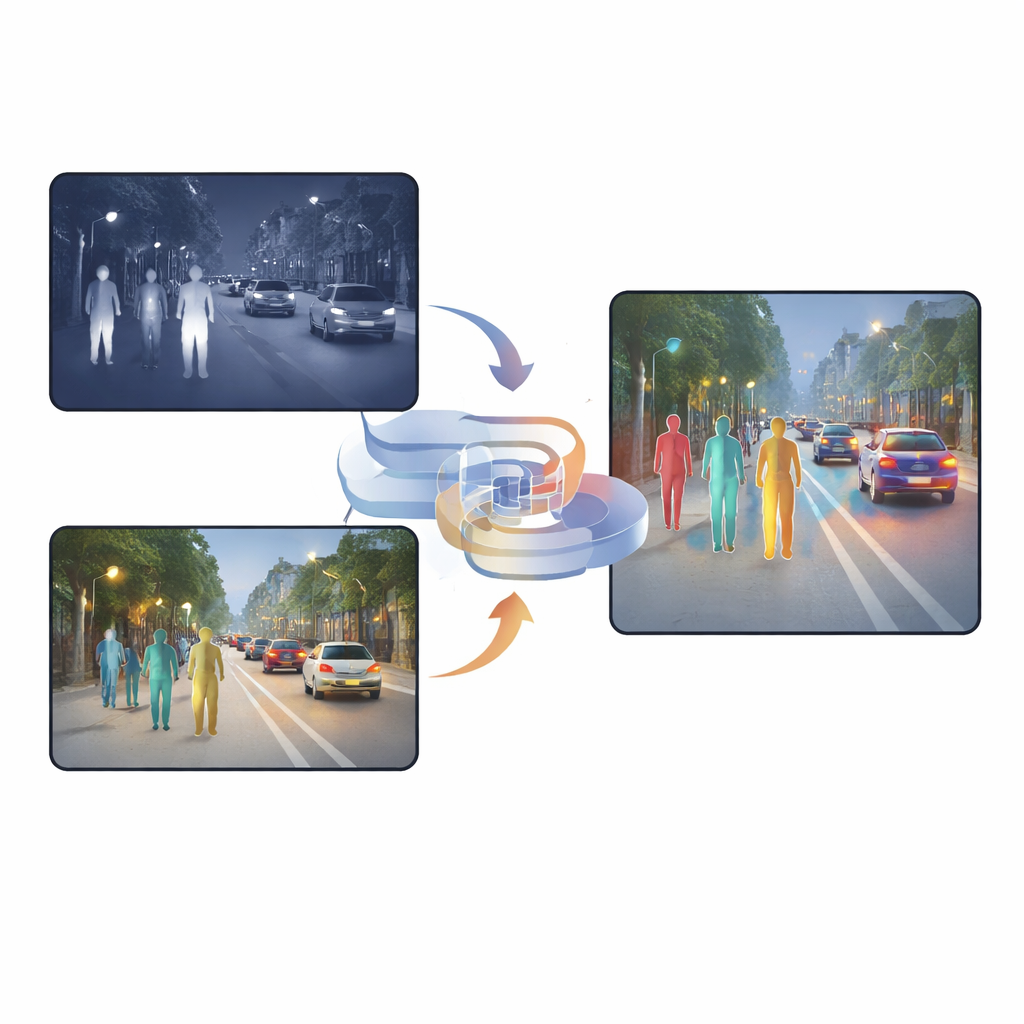
Perché due tipi di visione sono meglio di uno
Le camere visibili catturano ricche texture, colori e dettagli fini durante il giorno, ma le loro prestazioni calano drasticamente di notte o con illuminazione difficile. Le camere a infrarossi, al contrario, vedono il calore, perciò le persone risaltano anche nel buio, nella nebbia o in controluce. Tuttavia, le immagini infrarosse risultano spesso sfocate e prive di bordi netti. Molti sistemi esistenti si limitano ad accodare i due tipi di immagini o ad usare meccanismi di attenzione che decidono, pixel per pixel, a quale fotocamera affidarsi di più. Pur essendo utili, questi metodi trasportano ancora molte informazioni duplicate o conflittuali, e il risultato fuso può confondere la rete di rilevamento, specialmente quando la luce cambia improvvisamente o gli oggetti sono parzialmente nascosti.
Filtrare il rumore, mantenere l’essenziale
Gli autori propongono un nuovo framework di rilevamento che si concentra su ciò che le due camere hanno in comune e scarta ciò che non è necessario. Al suo centro c’è un Cross-modal Information Bottleneck, un modulo che comprime deliberatamente i dati congiunti visibile–infrarosso attraverso un “canale” stretto per poi ricostruire ciò su cui entrambe le viste sono d’accordo. Durante questo processo, la rete impara a conservare solo quei pattern che aiutano realmente a riconoscere gli oggetti, scartando vezzi e rumori specifici delle singole camere. Estrae separatamente ciò che è unico delle immagini visibili e ciò che è unico di quelle infrarosse, quindi li ricombina in modo controllato in modo che i punti di forza di ciascuna fotocamera siano preservati senza sovrastare la vista condivisa.
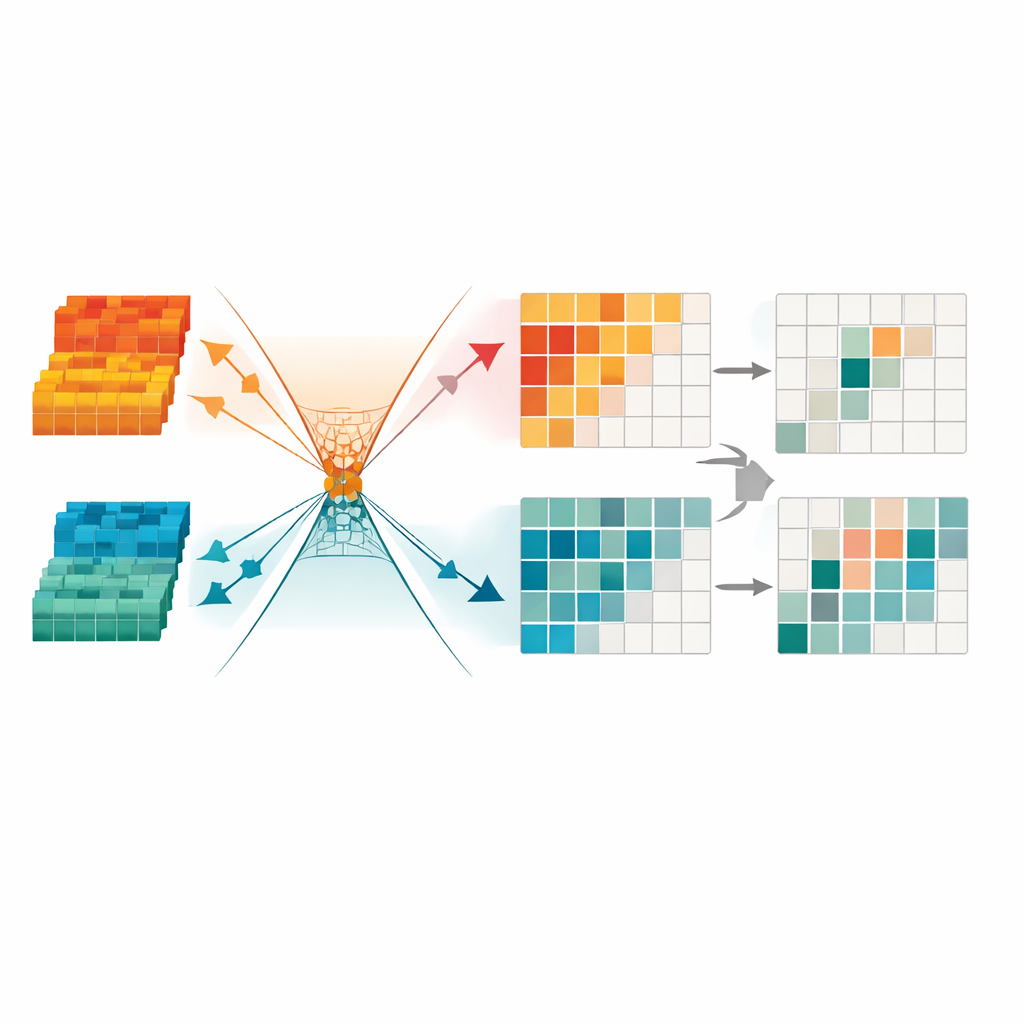
Ridurre i segnali ridondanti per una messa a fuoco più netta
Per pulire ulteriormente l’informazione, il framework introduce un modulo di Minimum Redundancy Transformation. Questo componente tratta i dati fusi come una collezione di canali e regioni, mascherando automaticamente quelli che risultano instabili, poveri di dettaglio o dominati da artefatti di illuminazione. Usa inoltre vincoli matematici per forzare la struttura utile e la ridondanza residua in “direzioni” diverse nel suo spazio interno, rendendo più semplice per la rete ignorare pattern che non aiutano nel rilevamento. Il risultato finale è una rappresentazione compatta e sparsa che mette in risalto bordi netti di oggetti e forme coerenti, particolarmente importante per individuare pedoni di notte o in scene urbane affollate.
Mettere il metodo alla prova
I ricercatori valutano il loro approccio su due dataset largamente usati di immagini visibili e infrarosse abbinate, KAIST e LLVIP, che includono strade affollate in condizioni normali e di scarsa illuminazione. Il loro metodo è costruito su un moderno detector basato su transformer ed è addestrato in due fasi: prima ogni ramo della fotocamera viene stabilizzato separatamente; poi la fusione viene rifinita affinché i due lavorino insieme senza attriti. Su entrambi i dataset, il nuovo framework supera i principali metodi basati solo su visibile, solo su infrarosso e quelli fusi, specialmente in misure di localizzazione rigorose che richiedono box di delimitazione molto precisi. Rimane inoltre più affidabile quando le immagini sono corrotte artificialmente con rumore, variazioni intense di luminosità o occlusioni sintetiche che bloccano parti dei pedoni, dimostrando che il modello è robusto a disturbi del mondo reale.
Cosa significa questo per macchine più sicure
In termini semplici, questo lavoro insegna ai sistemi di rilevamento ad ascoltare entrambe le camere senza però lasciarle sovrapporsi. Comprimendo e riorganizzando l’informazione proveniente da immagini visibili e infrarosse, il metodo proposto conserva gli indizi condivisi e significativi e taglia gran parte della ridondanza e del rumore. Ciò porta a un riconoscimento più nitido delle persone in scene difficili, dalle strade fiocamente illuminate agli sfondi fortemente ingombrati. Gli autori suggeriscono che gli stessi principi potrebbero essere estesi al video, al tracciamento multi-oggetto e persino a futuri sistemi che combinano immagini e linguaggio, aiutando le macchine a vedere—e comprendere—il mondo in modo più affidabile in ogni tipo di illuminazione.
Citazione: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Parole chiave: fusione infrarosso-visibile, rilevamento multimodale di oggetti, rilevamento pedoni, immagini in condizioni di scarsa illuminazione, robustezza della fusione dei sensori