Clear Sky Science · ja
クロスモーダル情報ボトルネックと最小冗長変換に基づく赤外線・可視融合マルチモーダル物体検出アルゴリズムに関する研究
暗闇の中で鮮明に見る
現代の自動車、街頭カメラ、警備ロボットは、雨や霧、深夜といった厳しい環境で人や物を検出する必要が増えています。可視光カメラは私たちの目と同様、暗い場面や強い逆光では性能が低下し、一方で赤外線カメラは熱を捉えられるため暗闇でも人物を浮かび上がらせますが、しばしば細部が失われがちです。本稿は、可視画像と赤外画像を新しい形で「融合」し、困難な条件下でも誤報や見逃しを減らして歩行者をより確実に検出する手法を提案します。
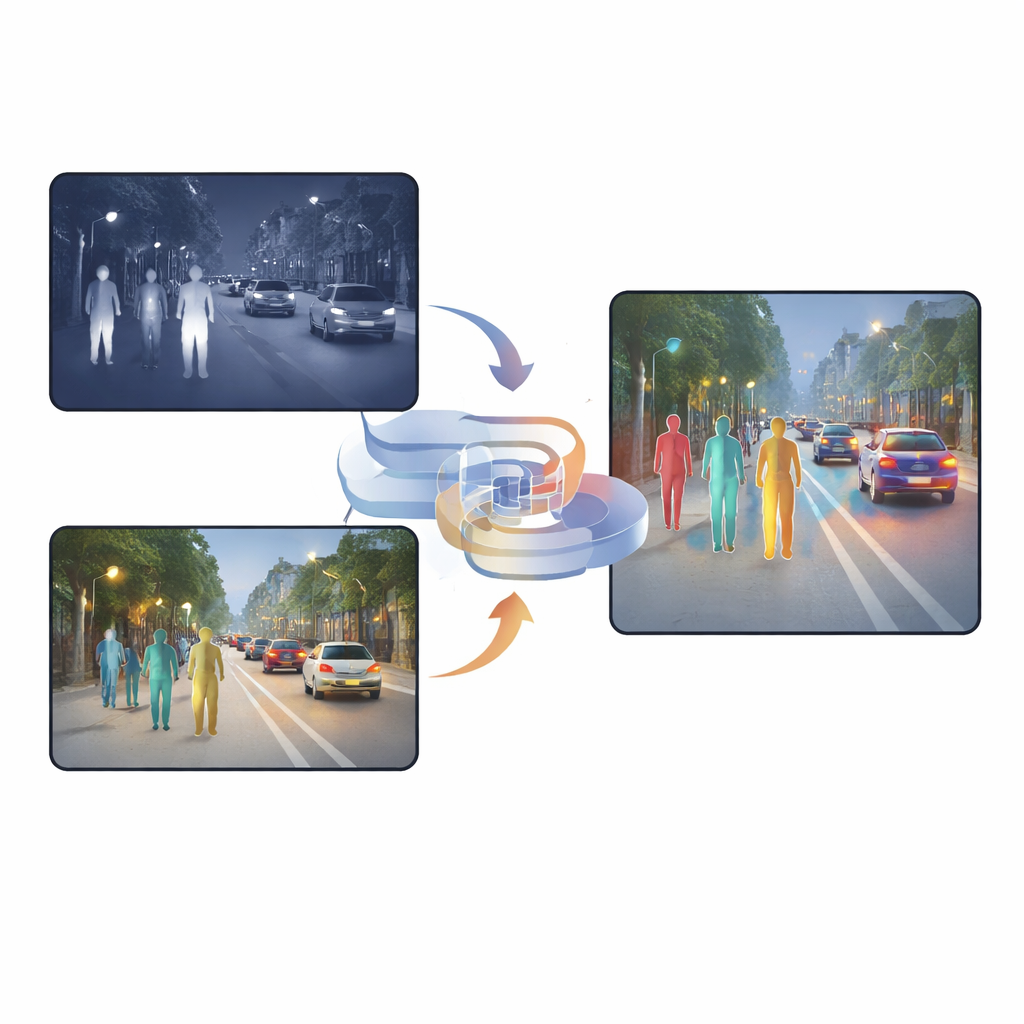
二つの視覚が一つより優れる理由
可視カメラは昼間に豊かなテクスチャ、色、細かなディテールを捉えますが、夜間や強い照明条件下では性能が急落します。対照的に赤外カメラは熱を基に映像化するため、暗闇や霧、逆光でも人物が目立ちます。ただし赤外画像はしばしばぼやけていて輪郭が弱いことが多いです。既存の多くのシステムはこれら二種類の画像を単純に積み重ねたり、ピクセルごとにどちらのカメラをより信頼するかを決める注意機構を使ったりしています。これらの方法は有益ですが、冗長または矛盾する情報を多く抱えがちで、光が急変したり物体が部分的に隠れたりすると、検出ネットワークにとって融合結果が混乱を招くことがあります。
ノイズを除き、重要な情報を保持する
著者らは、両カメラに共通する情報に焦点を当て、不要な情報を除去する新たな検出フレームワークを提案します。その中核はクロスモーダル情報ボトルネックであり、可視・赤外の結合データを意図的に狭い「チャネル」を通して圧縮し、両視点が同意する内容を再構成するモジュールです。この過程でネットワークは物体認識に真に役立つパターンだけを保持し、カメラ固有の癖やノイズを捨てることを学びます。可視画像に固有の特徴と赤外に固有の特徴を別々に抽出した上で、それらを制御された方法で再結合し、各カメラの強みを共有表現を圧倒しない形で保存します。
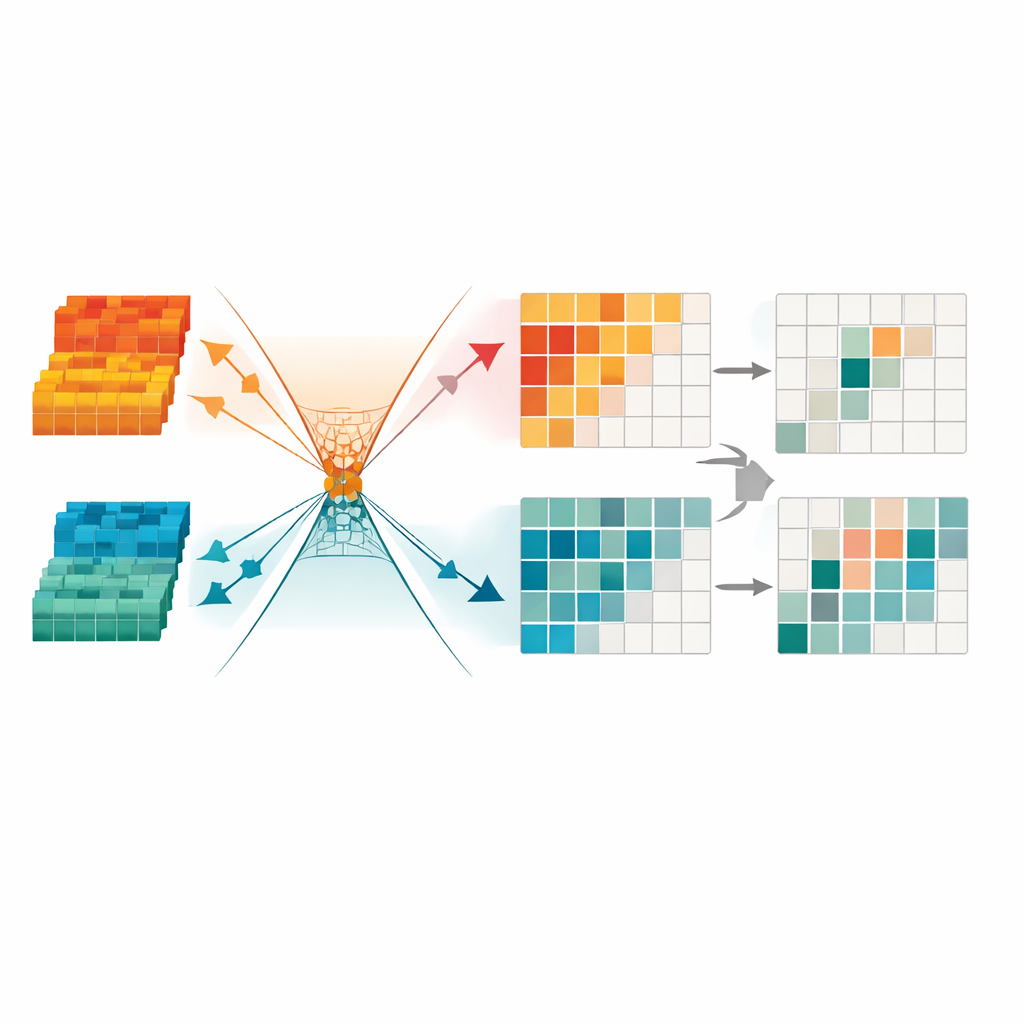
冗長な信号を削って鋭い焦点へ
情報をさらに洗練するために、本フレームワークは最小冗長変換モジュールを導入します。このコンポーネントは融合データをチャネルや領域の集合とみなし、不安定、ディテールが乏しい、または照明アーチファクトに支配された部分を自動的にマスクします。さらに有用な構造と残存する冗長性を内部空間の異なる「方向」に押し込むよう数理的拘束を課し、検出に寄与しないパターンを無視しやすくします。その結果、特に夜間や雑多な都市風景で歩行者を見つける際に重要となる、明瞭な物体境界や一貫した形状を強調する、コンパクトで疎な表現が得られます。
手法の実地評価
研究者らは、ペア化された可視・赤外画像の二つの広く使われるデータセット、KAISTとLLVIPで提案手法を評価しています。これらは通常光条件および低照度条件下の混雑した街路を含みます。手法は最新のトランスフォーマーベースの検出器を基盤とし、二段階で学習されます。まず各カメラ枝を個別に安定化し、その後融合を微調整して両者が円滑に協調するようにします。両データセットにわたり、本フレームワークは可視のみ、赤外のみ、既存の融合手法と比べて優れた性能を示し、特に極めて正確なバウンディングボックスを要求する厳格な位置決め指標で顕著でした。また、画像に人工的にノイズ、激しい輝度変化、あるいは歩行者の一部を覆う合成的な遮蔽を加えても信頼性を保ち、実世界の攪乱に対する頑健性を示しました。
より安全な機械への意義
平たく言えば、本研究は検出システムに対して両方のカメラに耳を傾けさせつつ、一方が他方を圧倒しないようにすることを教えます。可視と赤外の情報を圧縮し再編成することで、共有される意味ある手がかりを保持し、多くの冗長性やノイズを取り除きます。その結果、薄暗い路地から雑多な背景まで、困難な場面での人物認識がより明瞭になります。著者らは、同じ原理をビデオ、複数物体追跡、さらには画像とテキストを混合する将来のシステムへと拡張することで、あらゆる照明条件下で機械がより確実に世界を「見て」理解する助けになると示唆しています。
引用: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
キーワード: 赤外線-可視融合, マルチモーダル物体検出, 歩行者検出, 低照度イメージング, センサ融合の頑健性