Clear Sky Science · de
Eine Studie zum Multimodalen Objekterkennungsalgorithmus für Infrarot‑Sichtbarkeitssynthese basierend auf cross‑modalem Informationsflaschenhals und Minimum‑Redundanz‑Transformation
Klar sehen in der Dunkelheit
Moderne Autos, Straßenkameras und Sicherheitsroboter müssen immer häufiger Personen und Objekte bei Regen, Nebel und tiefster Nacht erkennen. Sichtbare Kameras — ähnlich wie unsere Augen — haben Schwierigkeiten, wenn die Szene dunkel ist oder starke Blendung vorliegt, während Infrarotkameras Wärme erfassen, aber oft Details vermissen. Diese Arbeit stellt eine neue Methode zur Kombination bzw. „Fusion“ von sichtbaren und infraroten Bildern vor, sodass Maschinen Fußgänger unter schwierigen Bedingungen zuverlässiger erkennen können, mit weniger Fehlalarmen und verpassten Zielen.
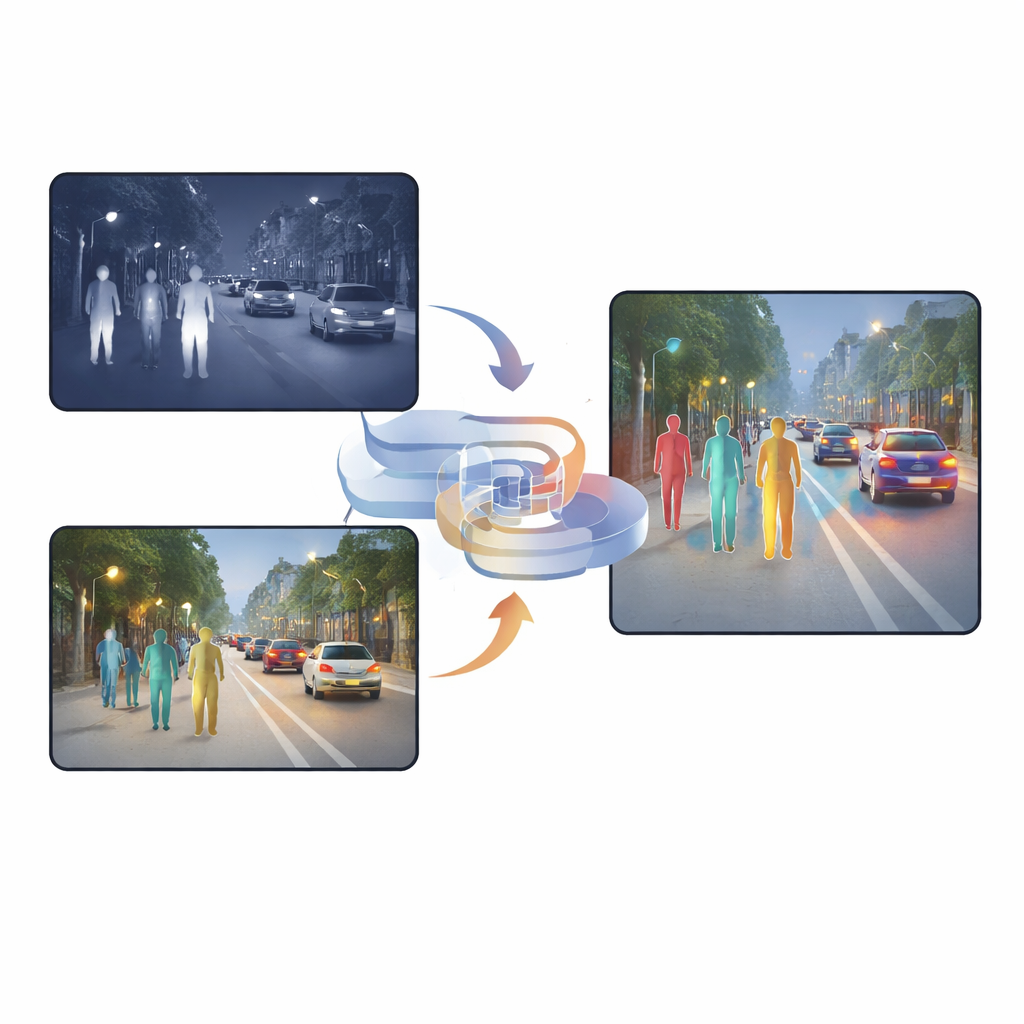
Warum zwei Arten von Sicht besser sind als eine
Sichtbare Kameras erfassen tagsüber reichhaltige Texturen, Farben und feine Details, verlieren jedoch nachts oder bei harten Lichtverhältnissen stark an Leistung. Infrarotkameras hingegen sehen Wärme, sodass Personen auch bei Dunkelheit, Nebel oder Gegenlicht hervorstechen. Infrarotbilder sind jedoch häufig verschwommen und haben wenig scharfe Kanten. Viele vorhandene Systeme legen diese beiden Bildtypen einfach übereinander oder nutzen Aufmerksamkeitsmechanismen, die pixelweise entscheiden, welcher Sensor glaubwürdiger ist. Zwar helfen solche Methoden, doch sie enthalten oft viel duplizierte oder widersprüchliche Information, und das fusionierte Ergebnis kann für das Erkennungsnetzwerk verwirrend sein — besonders bei plötzlichen Lichtwechseln oder teilweiser Verdeckung von Objekten.
Rauschen herausfiltern, das Wesentliche behalten
Die Autoren schlagen ein neues Erkennungsframework vor, das sich auf das konzentriert, was beide Kameras gemeinsam haben, und Unnötiges verwirft. Im Kern steht ein Cross‑modal Information Bottleneck, ein Modul, das die gemeinsamen sichtbaren‑infraroten Daten bewusst durch einen engen „Kanal“ presst und dann rekonstruiert, worauf sich beide Sichtweisen einigen. Während dieses Prozesses lernt das Netzwerk, nur jene Muster zu bewahren, die wirklich bei der Objekterkennung helfen, und kameraspezifische Eigenheiten und Störungen zu verwerfen. Es extrahiert getrennt, was für sichtbare Bilder einzigartig ist und was für infrarote, und fügt diese anschließend kontrolliert wieder zusammen, sodass die Stärken jeder Kamera erhalten bleiben, ohne die gemeinsame Sicht zu überlagern.
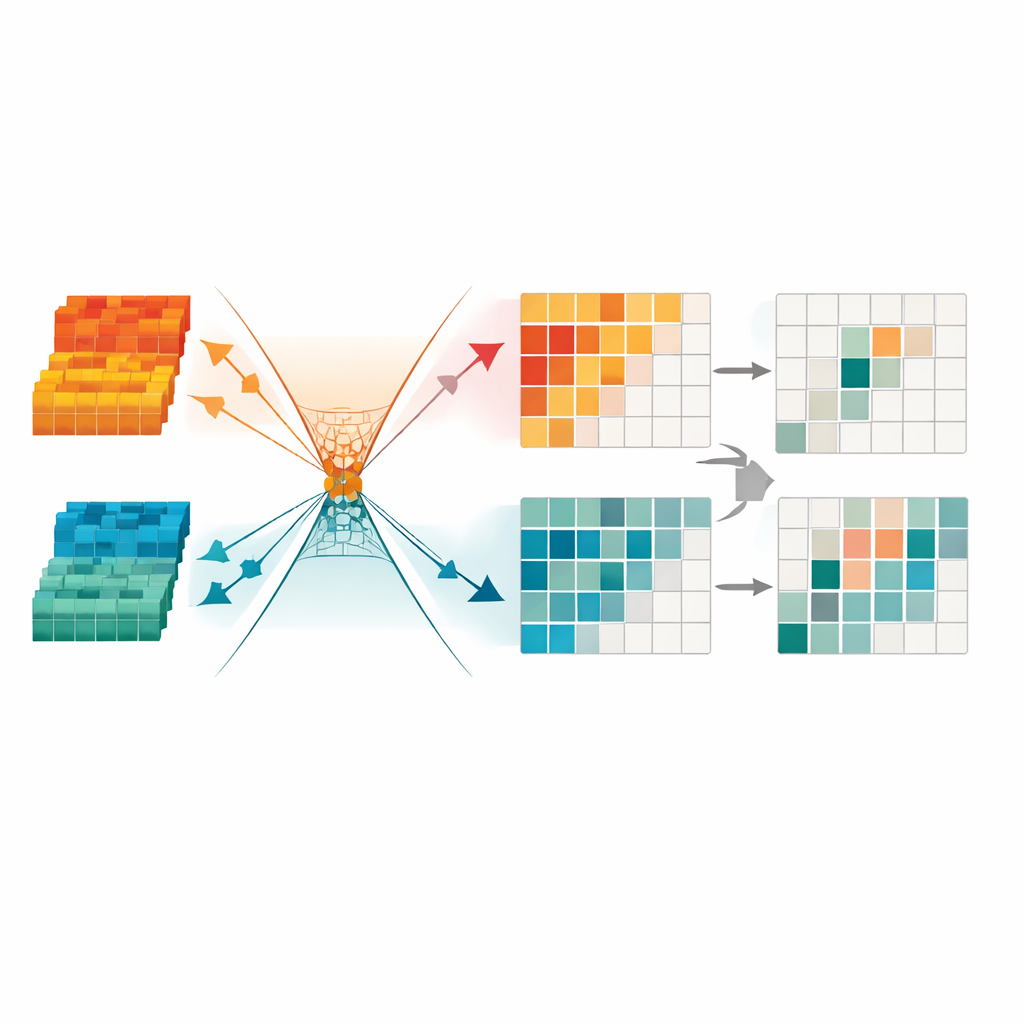
Redundante Signale beschneiden für schärferen Fokus
Um die Informationen weiter zu säubern, führt das Framework ein Minimum Redundancy Transformation‑Modul ein. Diese Komponente behandelt die fusionierten Daten wie eine Ansammlung von Kanälen und Regionen und maskiert automatisch solche, die instabil, detailarm oder von Beleuchtungsartefakten dominiert erscheinen. Sie verwendet außerdem mathematische Zwänge, um nützliche Struktur und verbleibende Redundanz in unterschiedliche „Richtungen“ ihres internen Raums zu zwingen, wodurch es dem Netzwerk leichter fällt, Muster zu ignorieren, die bei der Erkennung nicht helfen. Das Endergebnis ist eine kompakte, spärliche Repräsentation, die klare Objektgrenzen und konsistente Formen hervorhebt — besonders wichtig, um Fußgänger nachts oder in überladenen urbanen Szenen zu erkennen.
Die Methode auf die Probe stellen
Die Forschenden bewerten ihren Ansatz an zwei weit verbreiteten Datensätzen mit gepaarten sichtbaren und infraroten Bildern, KAIST und LLVIP, die belebte Straßen sowohl unter normalen als auch unter schwach beleuchteten Bedingungen enthalten. Ihre Methode baut auf einem modernen, transformer‑basierten Detektor auf und wird in zwei Stufen trainiert: Zunächst wird jede Kamerazweig separat stabilisiert; anschließend wird die Fusion feinabgestimmt, sodass beide Zweige reibungslos zusammenarbeiten. Über beide Datensätze hinweg übertrifft das neue Framework führende Sicht‑einzige, Infrarot‑einzige und fusionierte Methoden, insbesondere bei strengen Lokalisierungsmaßen, die sehr genaue Begrenzungsrahmen erfordern. Es bleibt auch zuverlässiger, wenn Bilder künstlich mit Rauschen, starken Helligkeitsänderungen oder synthetischen Verdeckungen, die Teile von Fußgängern blockieren, gestört werden, was zeigt, dass das Modell robust gegenüber realen Störungen ist.
Was das für sichere Maschinen bedeutet
Einfach gesprochen lehrt diese Arbeit Erkennungssysteme, beiden Kameras zuzuhören, aber nicht zuzulassen, dass sie einander übertönen. Durch Komprimieren und Umorganisieren der Informationen aus sichtbaren und infraroten Bildern behält die vorgeschlagene Methode die gemeinsamen, aussagekräftigen Hinweise und schneidet einen Großteil der Redundanz und des Rauschens weg. Das führt zu klarerer Erkennung von Personen in schwierigen Szenen — von schwach beleuchteten Straßen bis zu stark überfüllten Hintergründen. Die Autoren schlagen vor, dass dieselben Prinzipien auf Video, Multi‑Object‑Tracking und sogar zukünftige Systeme, die Bilder mit Sprache kombinieren, ausgeweitet werden könnten, um Maschinen zu helfen, die Welt unter allen Lichtverhältnissen zuverlässiger zu sehen — und zu verstehen.
Zitation: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Schlüsselwörter: Infrarot‑Sichtbarkeitssynthese, multimodale Objekterkennung, Fußgängererkennung, Low‑Light‑Bildgebung, Robustheit der Sensorfusion