Clear Sky Science · es
Un estudio sobre un algoritmo multimodal de detección de objetos por fusión infrarrojo-visible basado en cuello de botella de información cruzada y transformación de mínima redundancia
Ver con claridad en la oscuridad
Los coches modernos, las cámaras urbanas y los robots de seguridad cada vez tienen que detectar personas y objetos bajo lluvia, niebla y noche cerrada. Las cámaras de luz visible—como nuestros ojos—tienen dificultades cuando la escena está a oscuras o hay deslumbramiento, mientras que las cámaras infrarrojas captan el calor pero a menudo pierden detalle. Este artículo presenta una nueva forma de combinar, o “fusionar”, imágenes visibles e infrarrojas para que las máquinas puedan detectar peatones con mayor fiabilidad en condiciones difíciles, con menos falsas alarmas y menos objetivos perdidos.
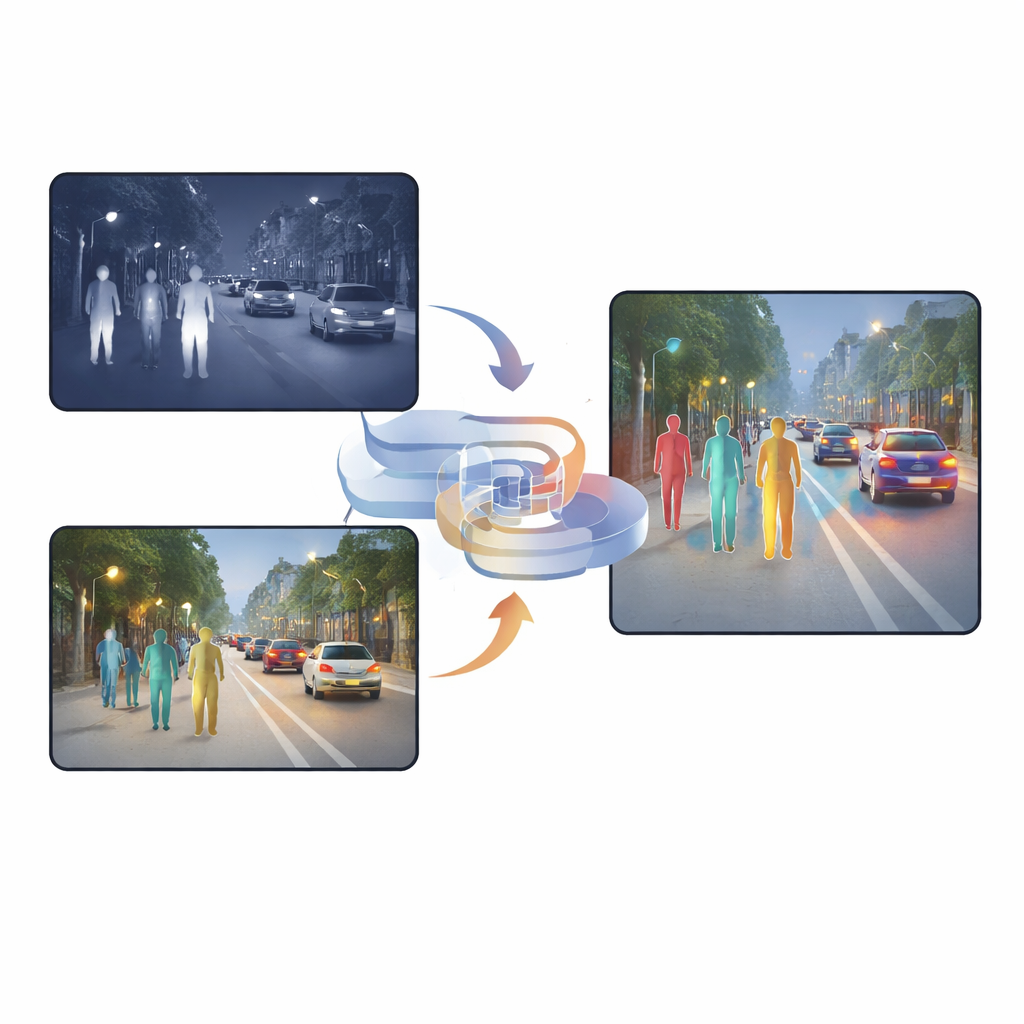
Por qué dos tipos de visión son mejores que uno
Las cámaras visibles capturan texturas ricas, colores y detalles finos durante el día, pero su rendimiento cae drásticamente por la noche o con una iluminación dura. Las cámaras infrarrojas, en cambio, detectan el calor, por lo que las personas destacan incluso en la oscuridad, la niebla o con contraluz. Sin embargo, las imágenes infrarrojas suelen ser borrosas y carecer de bordes nítidos. Muchos sistemas existentes simplemente apilan ambos tipos de imagen o usan mecanismos de atención que deciden, píxel a píxel, en qué cámara confiar más. Aunque estos métodos ayudan, siguen conteniendo mucha información duplicada o conflictiva, y el resultado fusionado puede confundir a la red de detección, especialmente cuando la iluminación cambia de forma abrupta o los objetos están parcialmente ocultos.
Filtrar el ruido, conservar lo esencial
Los autores proponen un nuevo marco de detección que se centra en lo que ambas cámaras comparten y desecha lo que no es necesario. En su núcleo está un Cuello de Botella de Información Cross-modal, un módulo que comprime deliberadamente los datos conjuntos visible–infrarrojo a través de un canal estrecho y luego reconstruye aquello en lo que ambas vistas coinciden. Durante este proceso, la red aprende a conservar solo los patrones que realmente ayudan a reconocer objetos, mientras descarta rarezas y ruido específicos de cada cámara. Extrae por separado lo que es único de las imágenes visibles y lo que es propio del infrarrojo, y luego los recombina de forma controlada para que las fortalezas de cada cámara se preserven sin sobrecargar la vista compartida.
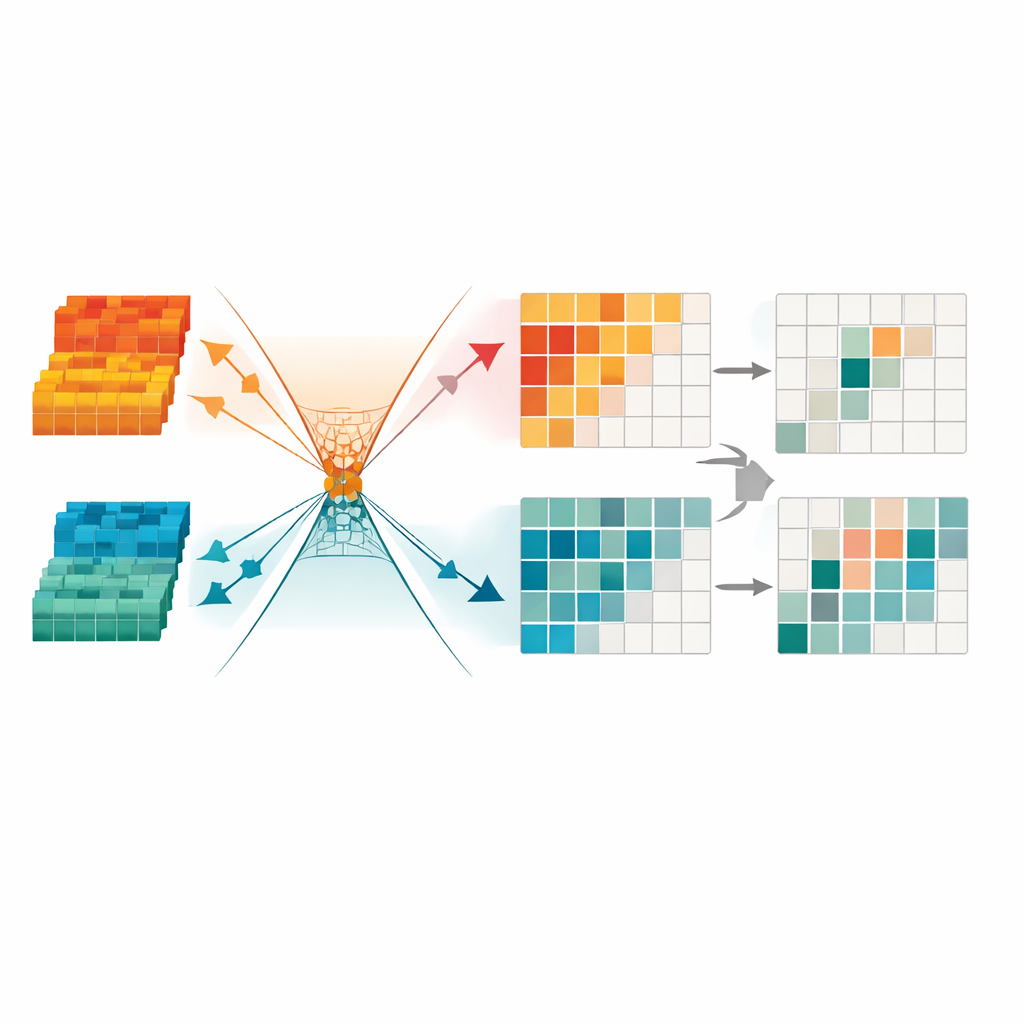
Recortar señales redundantes para un enfoque más nítido
Para limpiar aún más la información, el marco introduce un módulo de Transformación de Mínima Redundancia. Este componente trata los datos fusionados como una colección de canales y regiones, y enmascara automáticamente aquellos que parecen inestables, con poco detalle o dominados por artefactos de iluminación. También aplica restricciones matemáticas para forzar que la estructura útil y la redundancia residual ocupen “direcciones” distintas en su espacio interno, lo que facilita a la red ignorar patrones que no ayudan en la detección. El resultado final es una representación compacta y dispersa que resalta límites de objetos claros y formas consistentes, algo especialmente importante para detectar peatones por la noche o en escenas urbanas muy cargadas.
Poniendo el método a prueba
Los investigadores evalúan su enfoque en dos conjuntos de datos ampliamente usados de imágenes emparejadas visibles e infrarrojas, KAIST y LLVIP, que incluyen calles concurridas tanto en condiciones normales como con poca luz. Su método se basa en un detector moderno basado en transformadores y se entrena en dos etapas: primero, se estabiliza cada rama de la cámara por separado; luego, se afina la fusión para que ambas funcionen de forma coordinada. En ambos conjuntos, el nuevo marco supera a los métodos líderes que usan solo visible, solo infrarrojo o fusiones simples, especialmente en medidas estrictas de localización que requieren cajas delimitadoras muy precisas. Además, se mantiene más fiable cuando las imágenes se corrompen artificialmente con ruido, cambios bruscos de brillo u oclusiones sintéticas que bloquean partes de los peatones, demostrando que el modelo es robusto frente a perturbaciones del mundo real.
Qué significa esto para máquinas más seguras
En términos sencillos, este trabajo enseña a los sistemas de detección a escuchar a ambas cámaras sin dejar que una eclipse a la otra. Al comprimir y reorganizar la información de las imágenes visibles e infrarrojas, el método propuesto conserva las señales compartidas y significativas y elimina gran parte de la redundancia y el ruido. Esto conduce a un reconocimiento más claro de las personas en escenas difíciles, desde calles poco iluminadas hasta fondos muy cargados. Los autores sugieren que los mismos principios podrían extenderse al vídeo, al seguimiento de múltiples objetos e incluso a futuros sistemas que mezclen imágenes con lenguaje, ayudando a que las máquinas vean—y entiendan—el mundo con mayor fiabilidad en todo tipo de iluminación.
Cita: Tan, W., Geng, B. & Bai, X. A study on infrared-visible fusion multimodal object detection algorithm based on cross-modal information bottleneck and minimum redundancy transformation. Sci Rep 16, 12991 (2026). https://doi.org/10.1038/s41598-026-35339-2
Palabras clave: fusión infrarrojo-visible, detección multimodal de objetos, detección de peatones, imágenes con poca luz, robustez en fusión de sensores